예제: scikit-learn 모델 업로드
아래 문서는 기존 모델 파일에서 Foundry로 모델을 통합하는 방법에 대한 예시를 제공합니다. 단계별 가이드는 사전 학습된 파일에서 모델 게시하기 문서를 참조하십시오.
모델 파일에서 모델 생성
다음 예제는 UC Irvine에서 발표한 Iris 분류 데이터셋을 사용하여 로컬에서 학습된 모델을 사용합니다. 데이터셋에는 네 가지 기능이 있습니다; sepal_length, sepal_width, petal_length 및 petal_width로 구성되어 있으며, 이를 통해 iris 꽃의 특정 종을 예측하는 모델을 구축할 수 있습니다.
이 예제에서는 모델이 로컬에서 scikit-learn 라이브러리를 사용한 K-최근접 이웃 분류기로 학습되었다고 가정합니다. 또한 이 예제는 모델이 Python 3.8.0 및 scikit-learn 1.3.2로 학습되었다고 가정합니다.
학습 후 모델은 아래에서 정의한 대로 pickle 파일로 저장됩니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier import pickle # 붓꽃 데이터셋 불러오기 iris = load_iris() X = iris.data y = iris.target # 데이터셋 분할 (훈련 데이터와 테스트 데이터) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.4, random_state=4) # K-최근접 이웃 알고리즘을 사용한 분류기 생성 knn = KNeighborsClassifier(n_neighbors = 5) # 훈련 데이터를 사용하여 모델 훈련 knn.fit(X_train, y_train) # 모델을 파일로 저장하기 (pickle 사용) with open("iris_model.pkl", "wb") as f: pickle.dump(knn, f)
1. 모델 파일을 비구조화된 데이터셋에 업로드
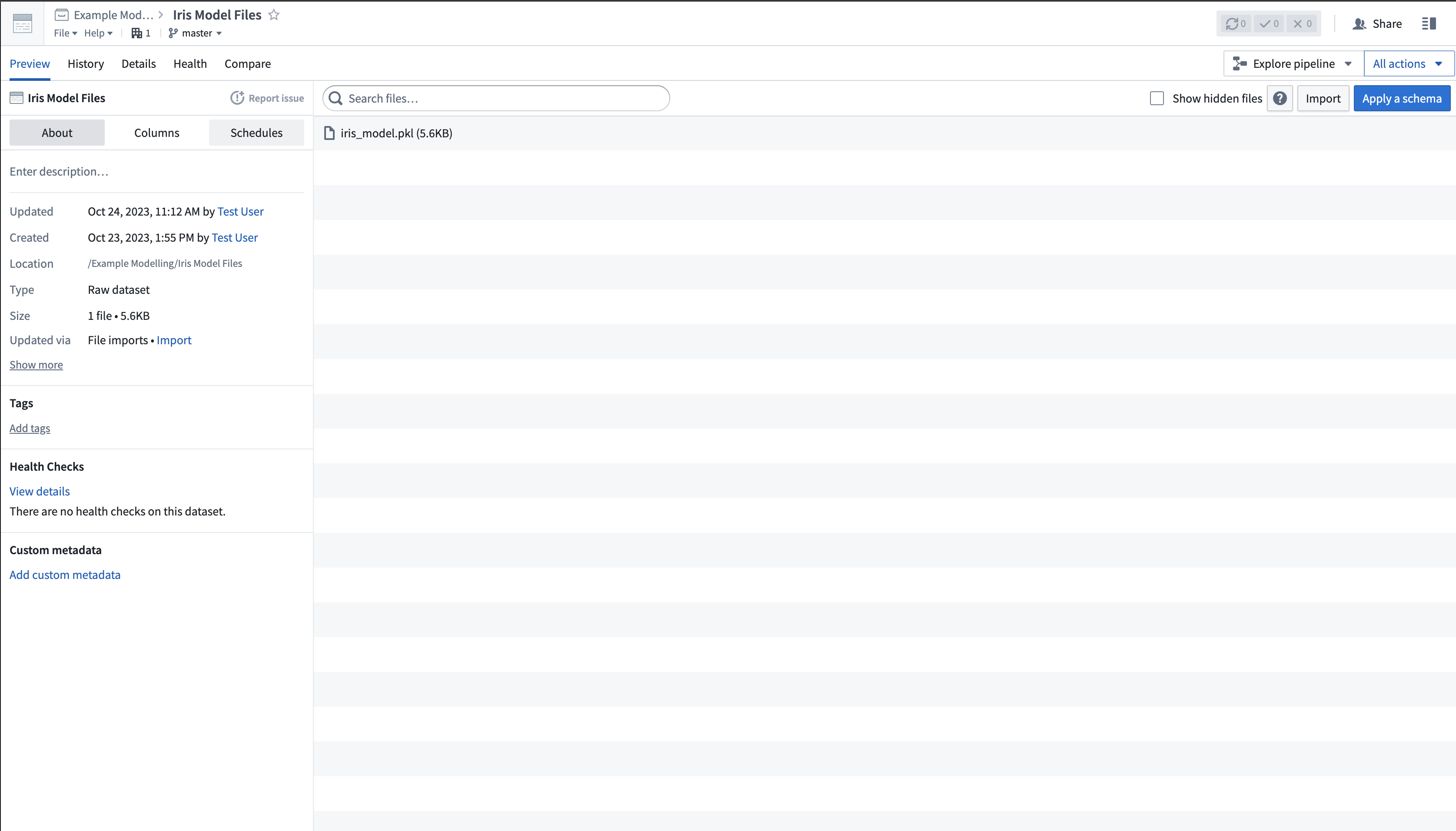
scikit-train 모델 파일은 아래 이미지와 같이 Palantir에 비구조화된 데이터셋으로 업로드됩니다:
2. 모델 어댑터 로직을 정의하기 위한 모델 훈련 템플릿 생성
Code Repositories 애플리케이션에서 새로운 모델 통합 저장소를 모델 훈련 언어 템플릿으로 생성한 뒤, scikit-learn 1.3.2에 대한 의존성을 추가합니다. 모델 파일을 읽고 모델을 게시하는 로직을 정의합니다.
3. 모델 파일을 모델로 게시
모델 어댑터 로직이 실행되면, 모델이 플랫폼에 게시됩니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47from transforms.api import transform, Input import palantir_models as pm from palantir_models.transforms import ModelOutput from palantir_models_serializers import DillSerializer import pickle import os @transform( model_files=Input("<Your Input Path>"), # 모델 파일을 불러오는 경로를 지정합니다. model_output=ModelOutput("<Your Output path>") # 모델 결과를 저장할 경로를 지정합니다. ) def compute(model_files, model_output): fs = model_files.filesystem() with fs.open("iris_model.pkl", "rb") as f: # Iris 모델 파일을 불러옵니다. model = pkl.load(f) model_adapter = IrisModelAdapter(model, "target") # 모델과 예측 컬럼 이름을 기준으로 IrisModelAdapter 객체를 생성합니다. model_output.publish( model_adapter=model_adapter # 생성된 객체를 사용하여 모델 결과를 저장합니다. ) class IrisModelAdapter(pm.ModelAdapter): # Palantir model adapter를 확장하여 Iris 모델에 맞게 조정합니다. @auto_serialize( model=DillSerializer(), # 모델 객체를 직렬화합니다. prediction_column_name=DillSerializer() # 예측 컬럼 이름을 직렬화합니다. ) def __init__(self, model, prediction_column_name="target"): self.model = model self.prediction_column_name = prediction_column_name @classmethod def api(cls): column_names = ["sepal_length", "sepal_width", "petal_length", "petal_width"] # 사용할 컬럼 이름을 지정합니다. columns =[(name, float) for name in column_names] # 사용할 컬럼과 그 데이터 타입을 정의합니다. inputs = {"df_in": pm.Pandas(columns=columns)} # 입력 데이터를 정의합니다. outputs = {"df_out": pm.Pandas(columns=columns+[("target", int)])} # 출력 데이터를 정의합니다. return inputs, outputs # 입력과 출력 데이터를 반환합니다. def predict(self, df_in): # 예측 메서드를 정의합니다. inference_data = df_in predictions = self.model.predict(inference_data.values) # 모델을 사용하여 예측합니다. inference_data[self.prediction_column_name] = predictions # 예측 결과를 데이터에 추가합니다. return inference_data # 최종 데이터를 반환합니다.
4. 게시된 모델 사용하기
모델이 게시되면, 플랫폼에서 추론을 위해 사용할 준비가 됩니다. 이 예시에서는 새로운 Modelling Objective를 생성하고 모델을 제출할 것입니다.
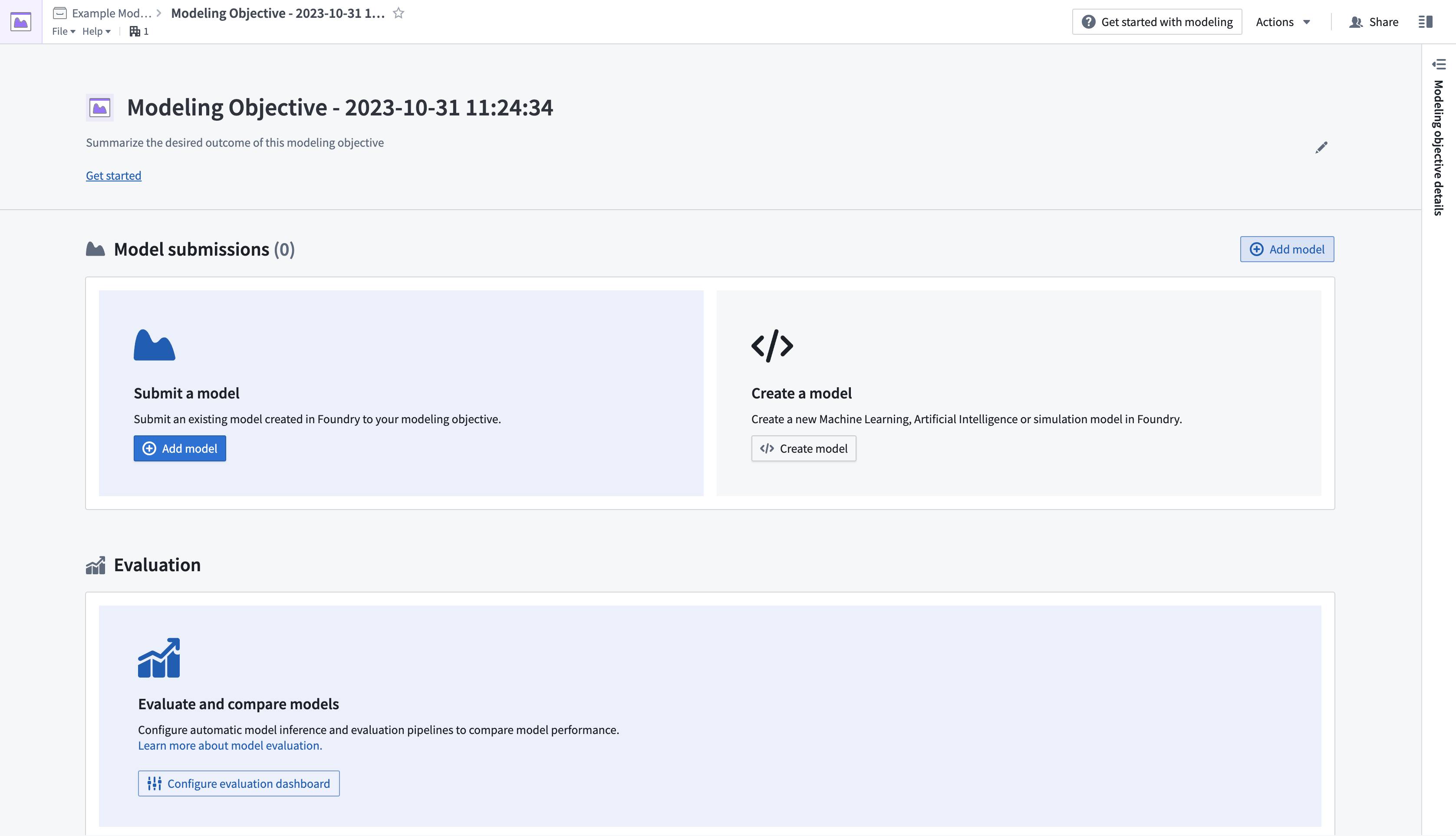
- 원하는 프로젝트 폴더로 이동하여 새 Modelling Objective를 생성한 뒤, New > Modeling Objective를 선택합니다. 이렇게 하면 Modeling Objectives 애플리케이션이 열립니다.
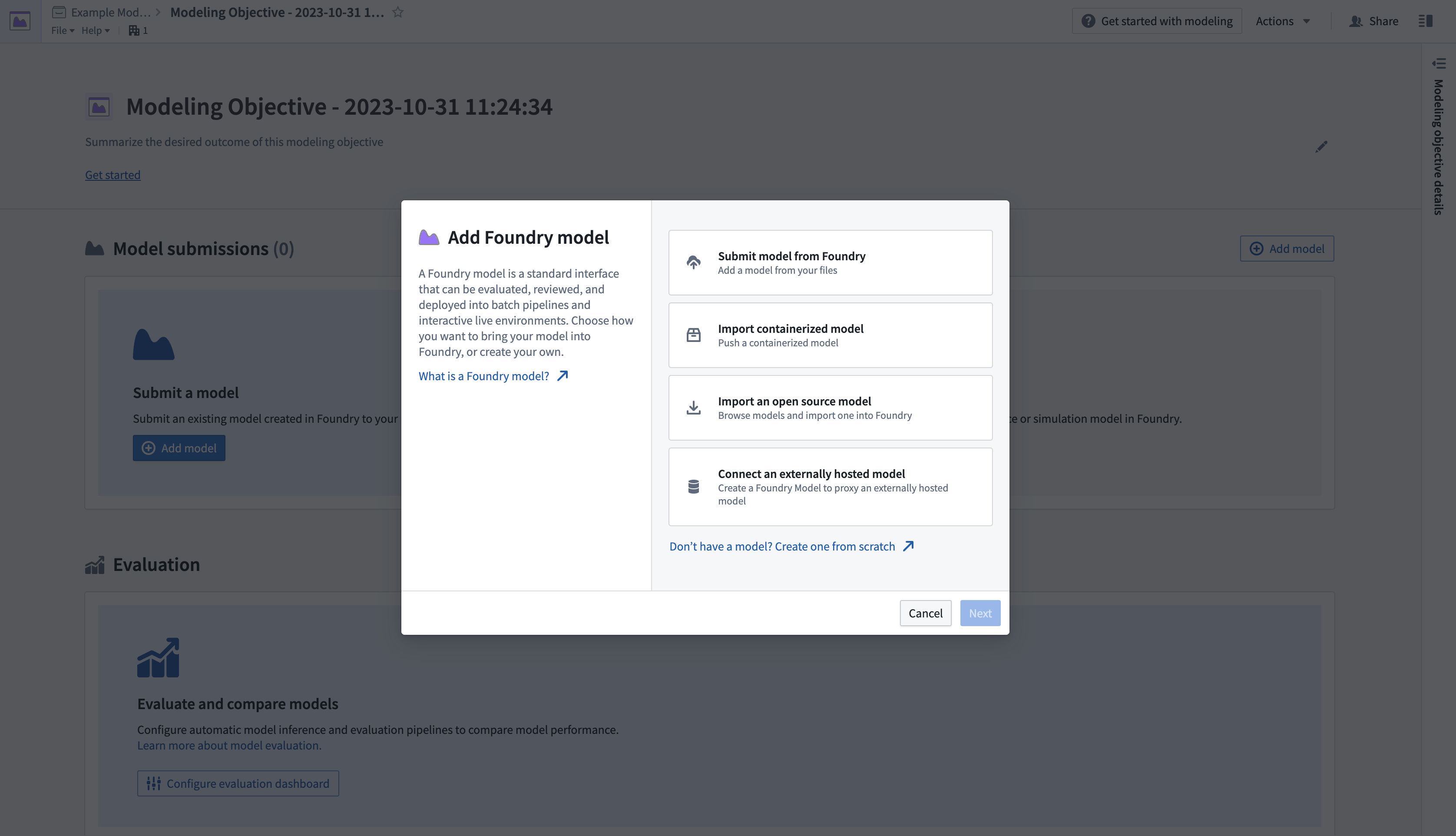
- 다음으로, 목표에 모델을 제출합니다. Model Submissions > Submit a Model 섹션에서 Add Model을 선택하여 아래와 같이 대화 상자를 엽니다.
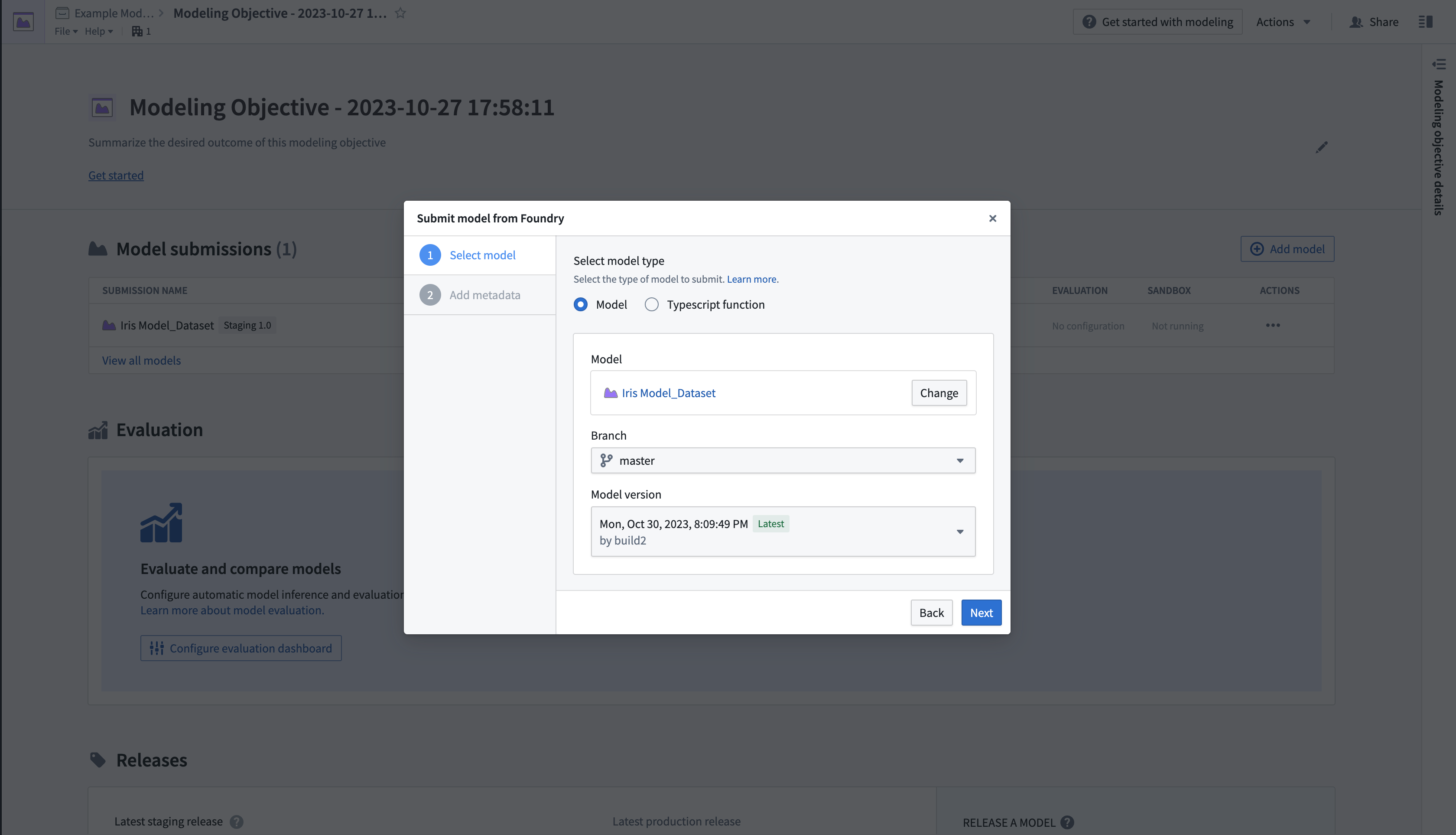
- Submit model from Foundry를 선택한 후 Next를 선택하여 플랫폼에서 게시된 모델을 로드할 수 있는 대화 상자를 엽니다.
- 모델이 제출되면, Modelling Objective 개요 페이지로 다시 이동하게 되며, Model submissions 섹션에서 제출에 대한 정보를 확인할 수 있습니다.
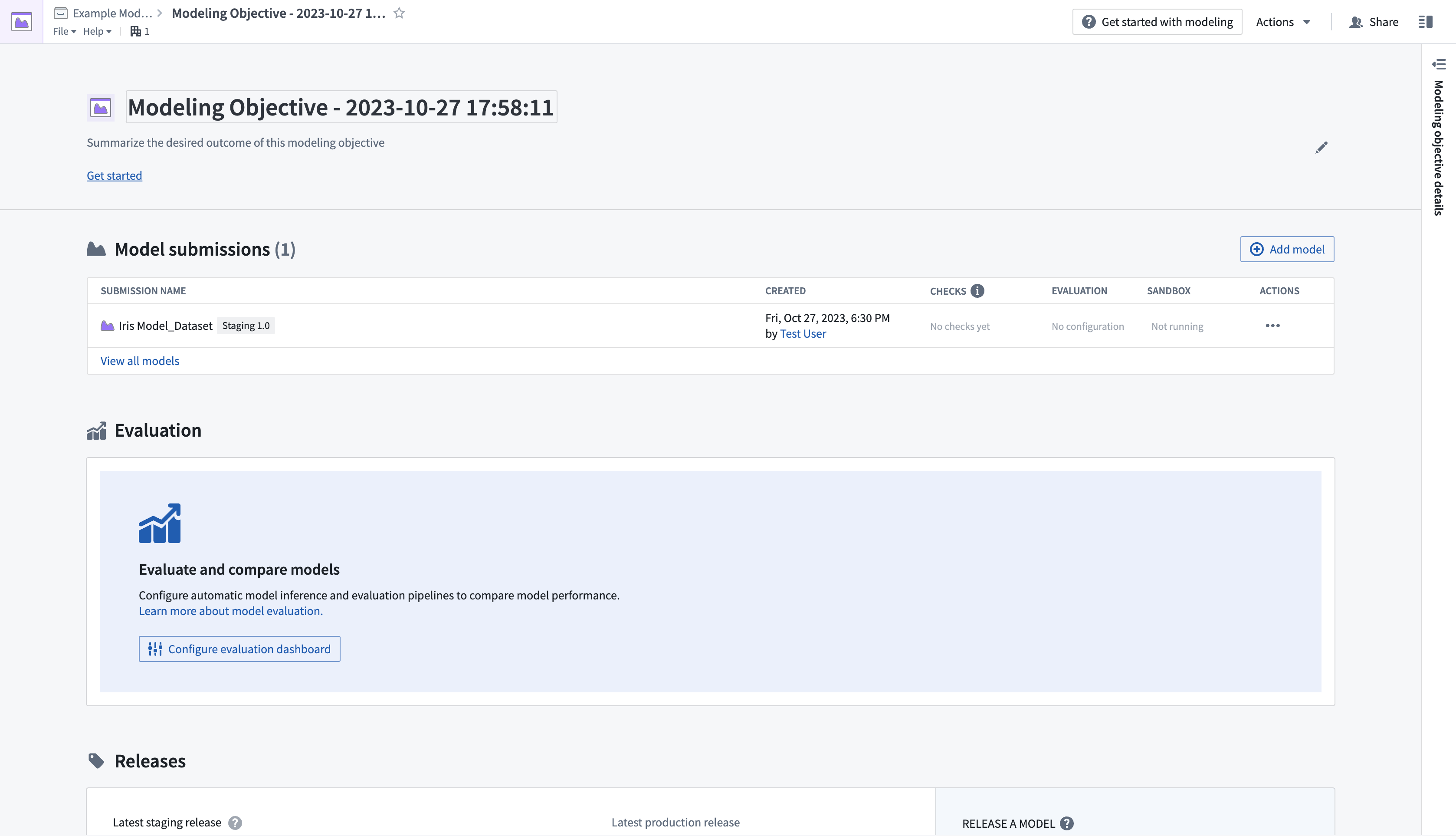
- Model submissions 섹션에서 새로 제출된 모델을 선택하여 모델 페이지를 엽니다.
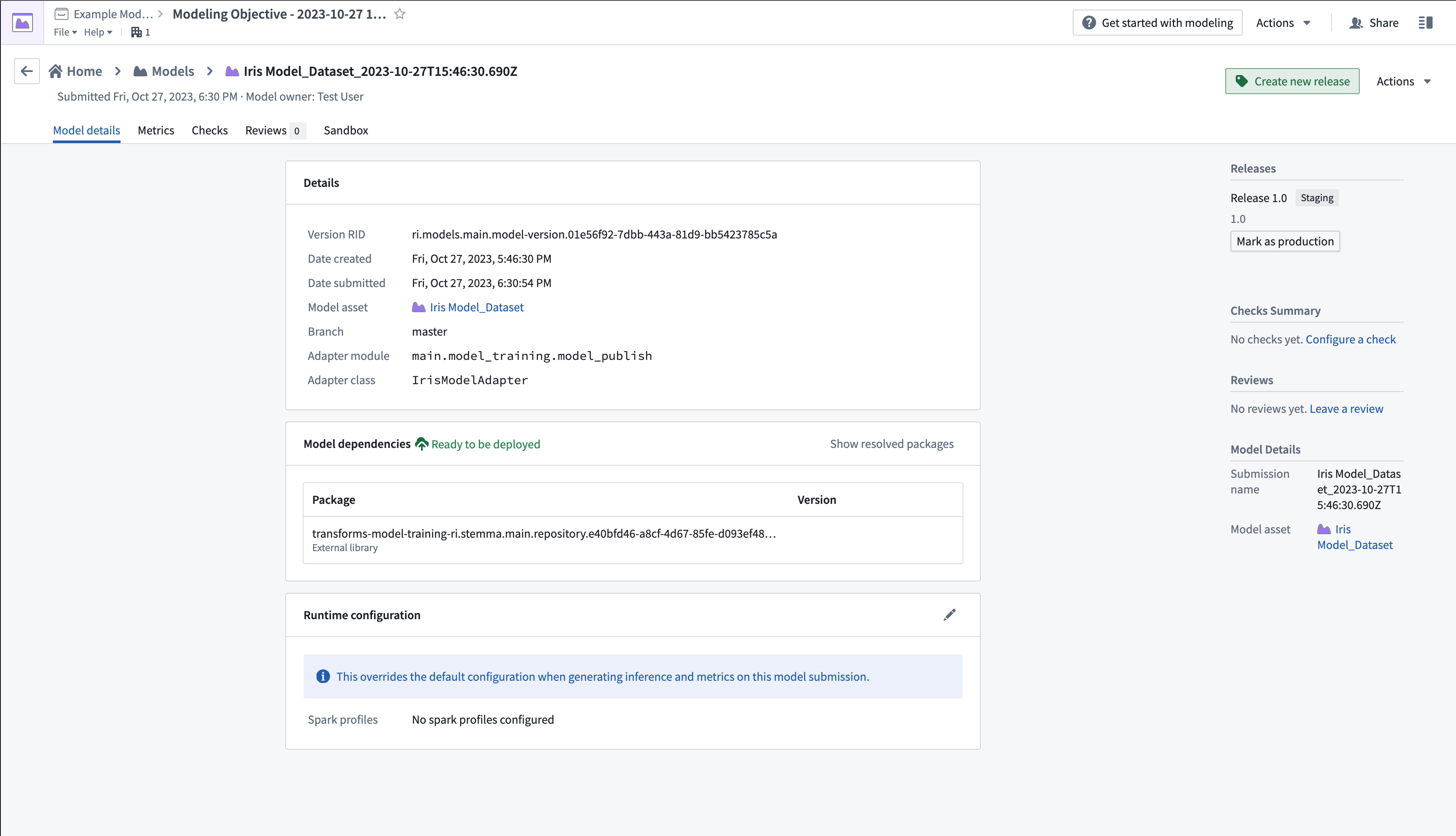
- 오른쪽 상단에서 Create new release를 선택하여 새 창을 열고 릴리스를 생성합니다.
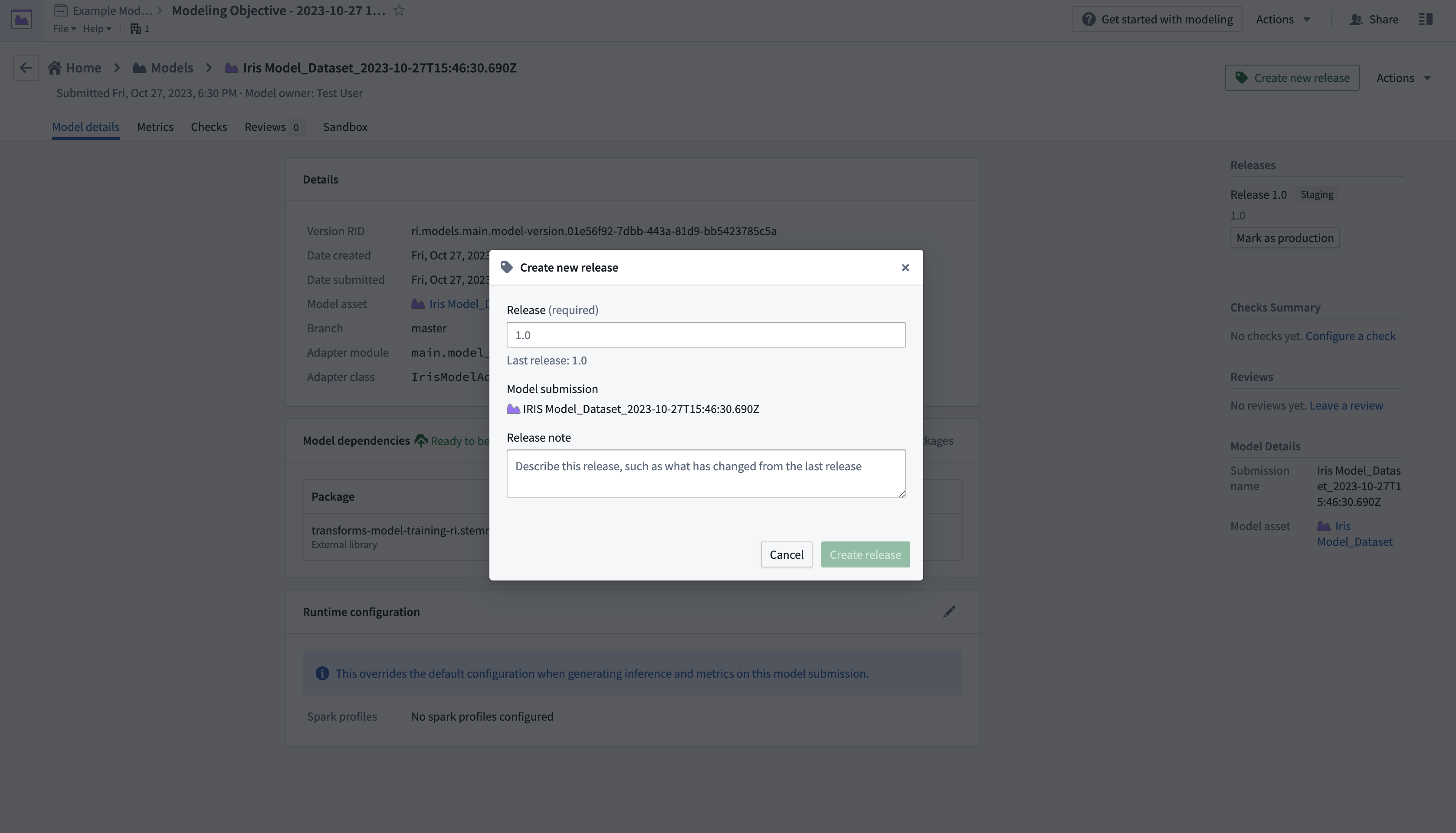
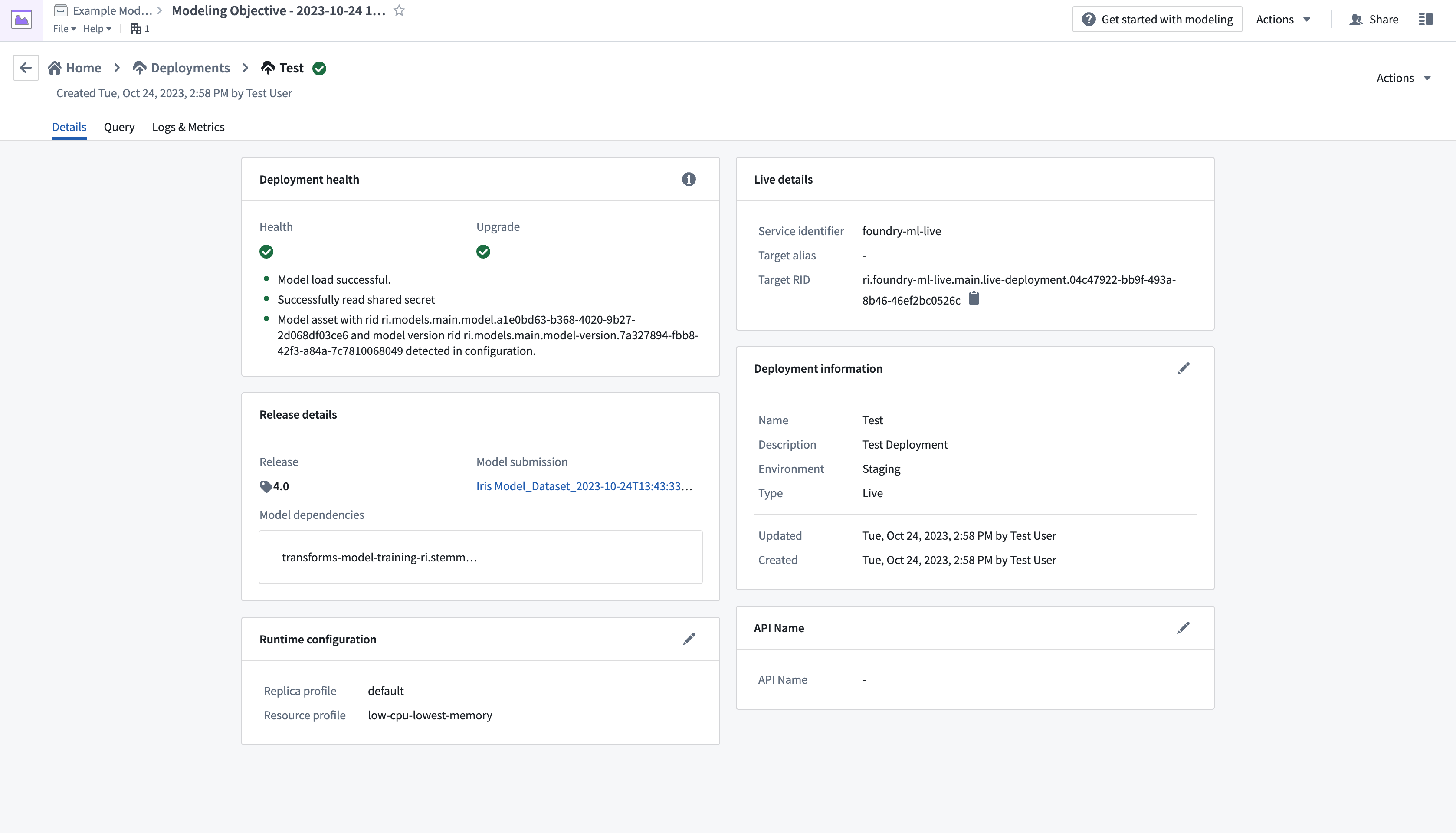
- 릴리스를 생성한 후, 화면의 왼쪽 상단에 있는 이름을 선택하여 Modelling Objective 개요 페이지로 돌아갑니다. Deployments로 스크롤 다운한 후 Create deployment를 선택하여 다른 대화 상자 창을 엽니다.
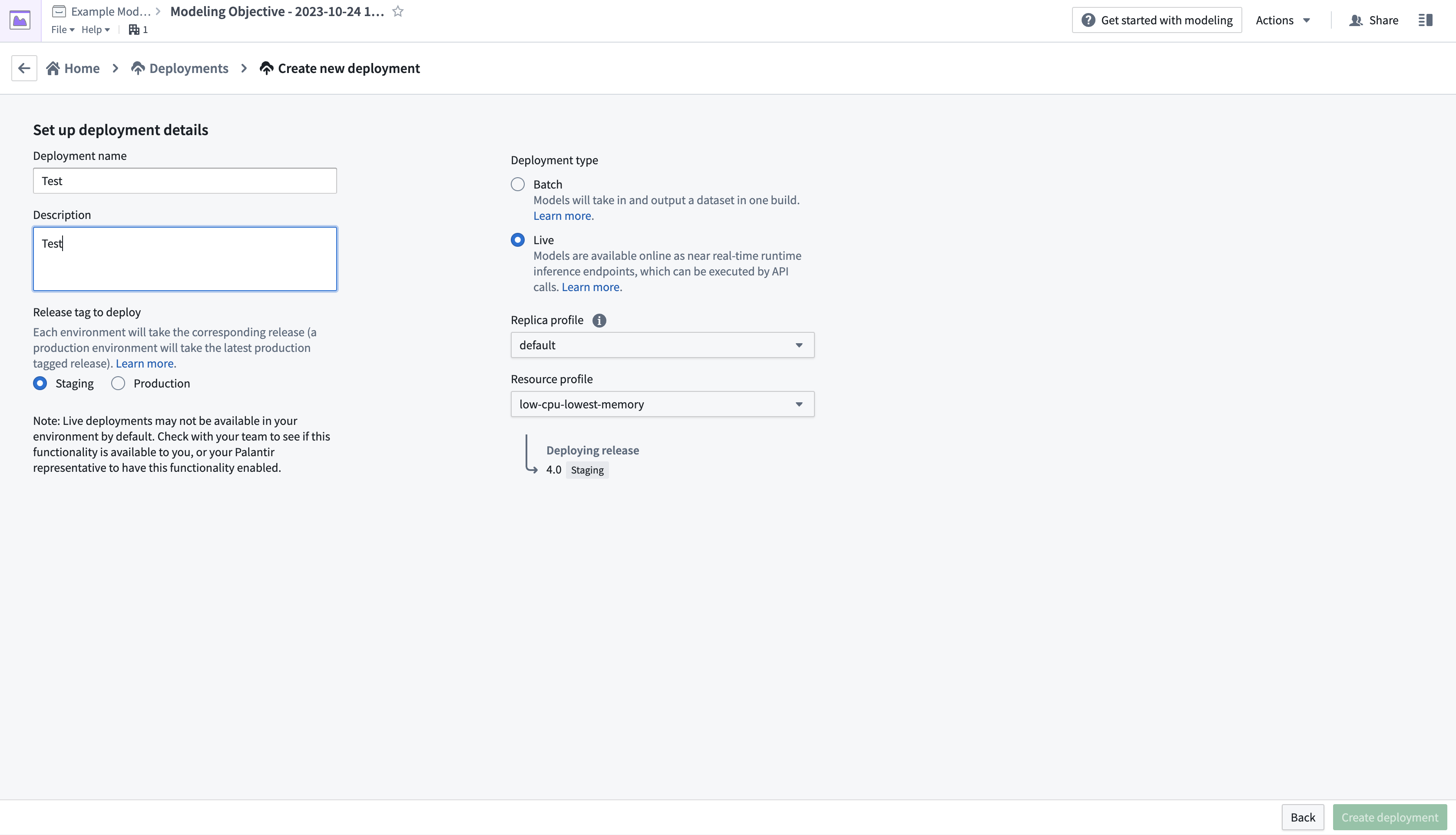
- 설정 양식을 완료한 후, 오른쪽 하단에서 Create deployment를 선택합니다. Modelling Objective 개요로 돌아가 Deployments로 스크롤 다운한 후, 새로 배포된 모델을 선택하여 테스트합니다.
- 페이지의 왼쪽 상단에서 Query 탭을 선택하고, 값을 추가하고 결과물을 확인하여 모델을 테스트합니다.
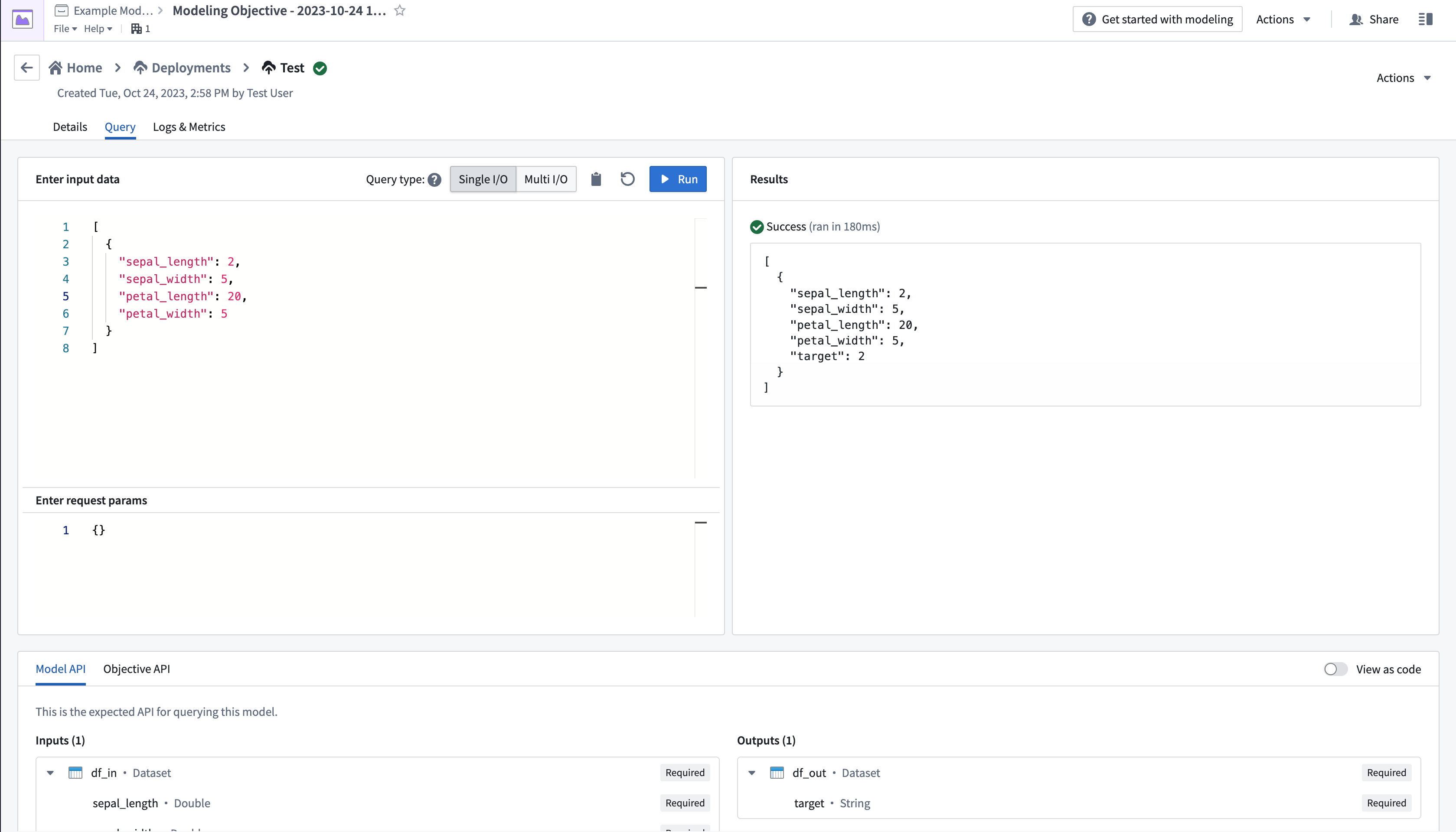
라이브 배포 생성 및 쿼리에 대한 자세한 내용은 라이브 배포 문서에서 찾을 수 있습니다.