사전 훈련된 파일에서 모델 발행하기
Palantir은 플랫폼 외부에서 생성된 가중치를 감싼 모델을 생성할 수 있게 합니다. 이 파일들은 오픈 소스 모델 가중치, 로컬 개발 환경에서 훈련된 모델, Code Workspaces 애플리케이션에서 훈련된 모델, 레거시 시스템에서의 모델 가중치를 포함할 수 있습니다.
Palantir 모델이 생성되면 Palantir은 다음을 제공합니다:
- 배치 파이프라인과 실시간 모델 호스팅과의 통합.
- 완전한 버젼, 세분화된 권한 부여, 그리고 통제된 모델 출처.
- Modeling Objectives를 통한 모델 관리 및 실시간 배포.
- 온톨로지와의 바인딩, 모델에서의 함수 및 what-if 시나리오 분석을 통한 운영화 허용.
모델 파일에서 모델 생성하기
모델 파일에서 모델을 생성하려면 다음이 필요합니다:
- Palantir에 업로드할 수 있는 모델 파일
- 모델을 로드하고 추론을 실행하는 방법을 Palantir에 알려주는 모델 어댑터
1. 모델 파일을 비구조화된 데이터셋에 업로드하기
먼저, 모델 파일을 Palantir 플랫폼의 비구조화된 데이터셋에 업로드합니다. 프로젝트에서 +New > Dataset을 선택하여 새로운 데이터셋을 생성합니다.
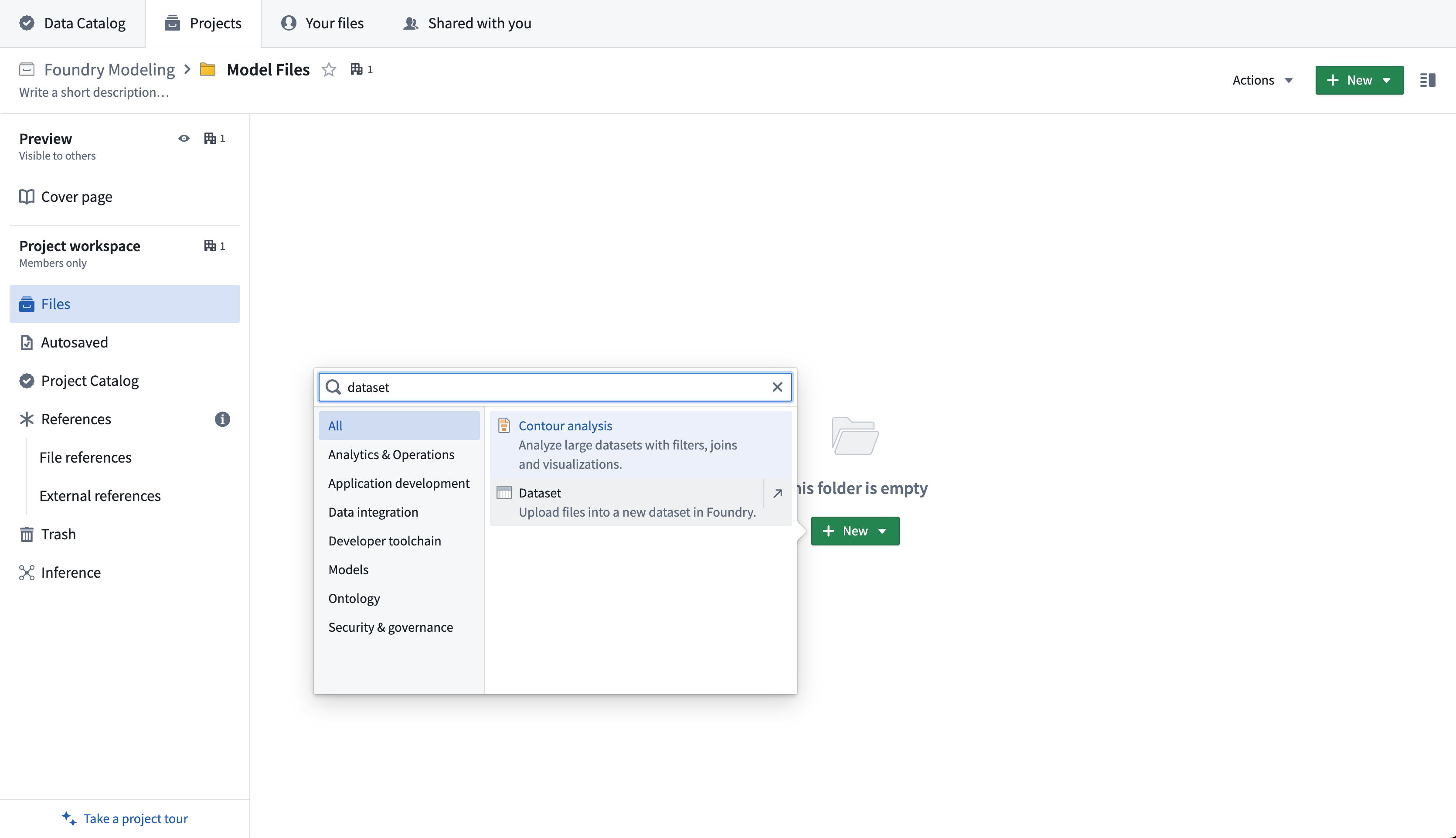
그런 다음, Import new data를 선택하고 컴퓨터에서 모델에 업로드할 파일을 선택합니다.
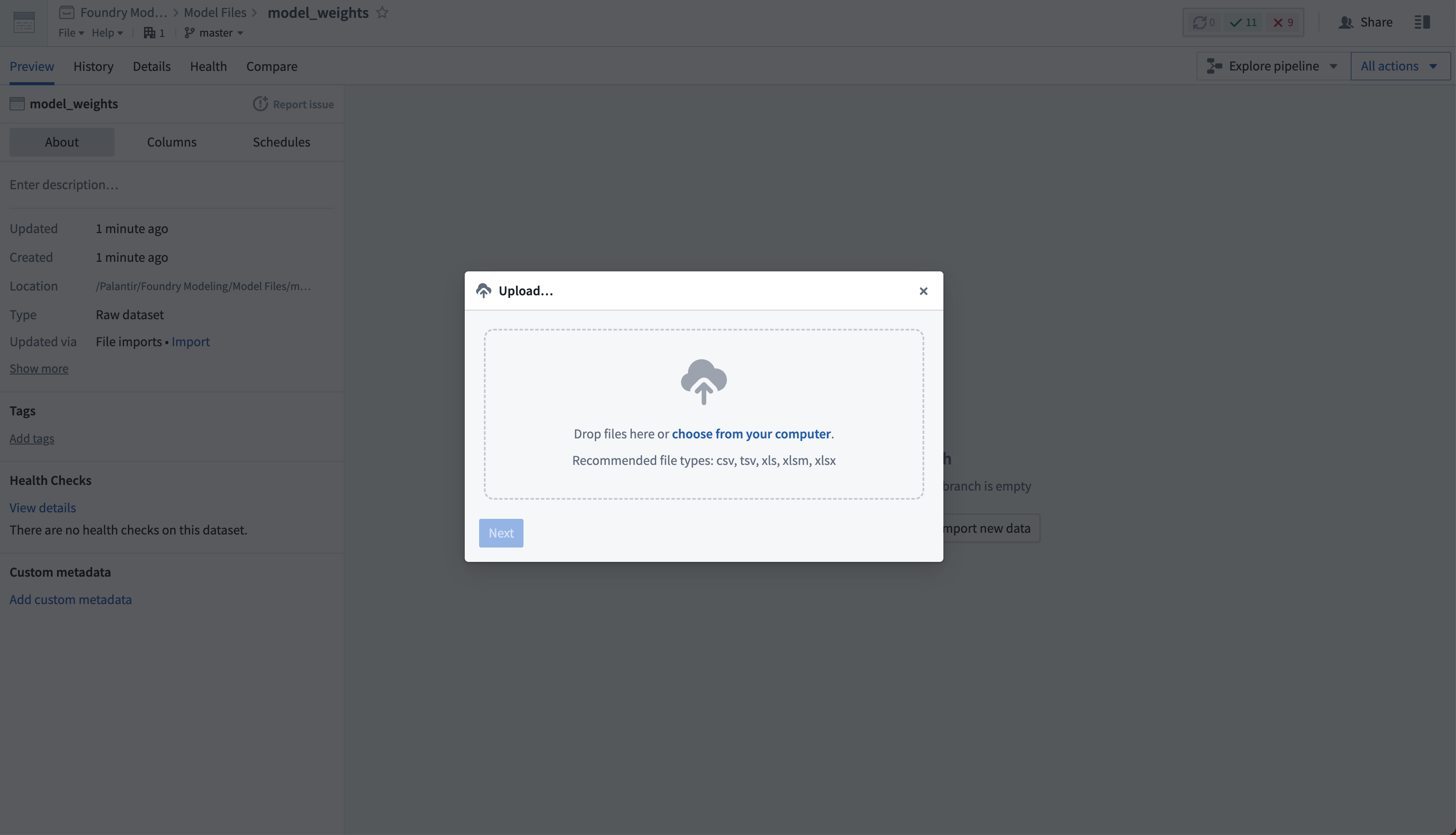
필요한 경우, 동일한 데이터셋에 여러 다른 파일을 업로드할 수 있습니다. 데이터셋은 비구조화되어 있을 것이므로, 테이블 스키마를 가지고 있지 않을 것입니다.
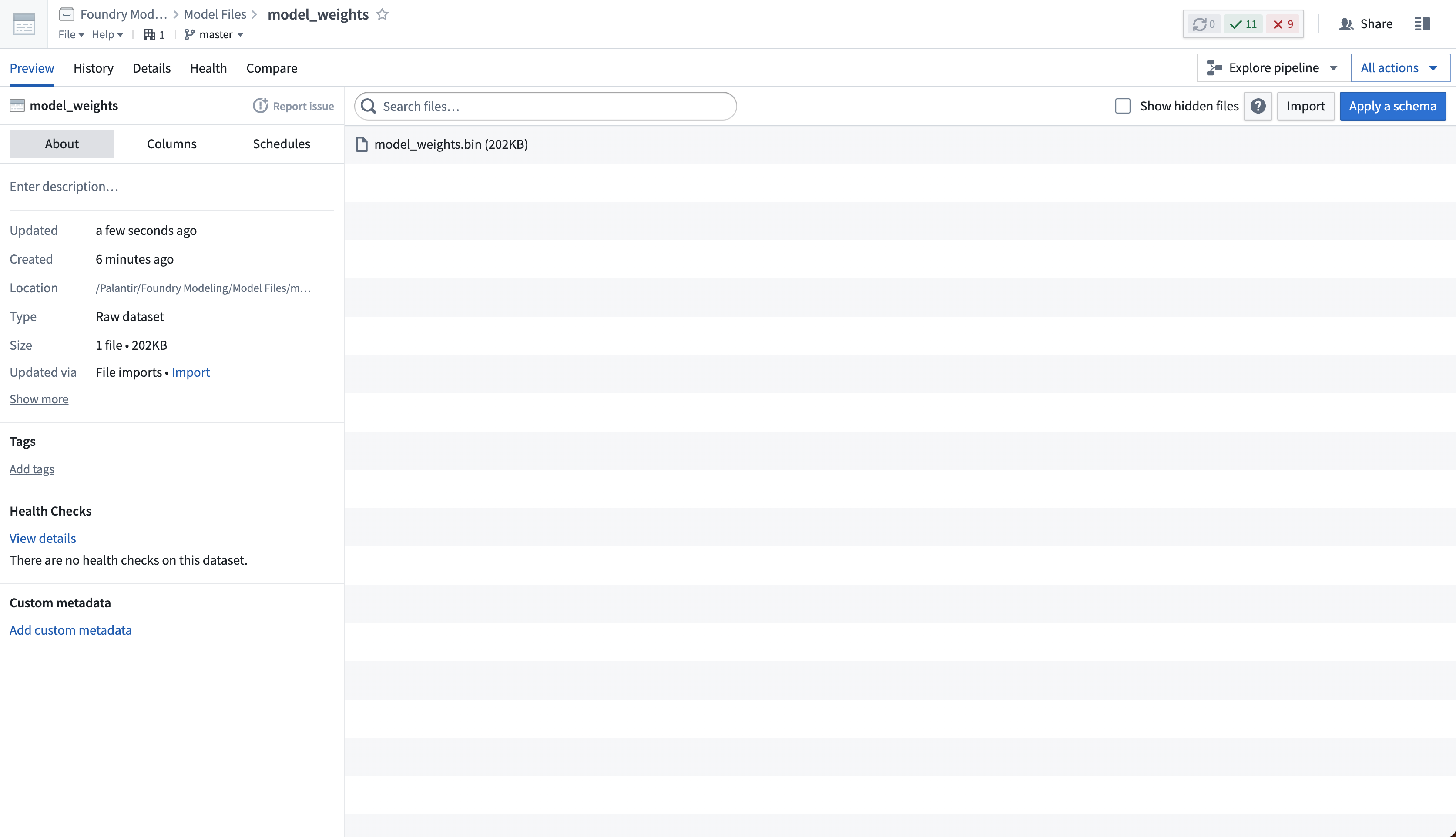
2. 모델 어댑터 로직을 정의하기 위해 모델 훈련 저장소 생성하기
비구조화된 데이터셋에서 모델 파일을 읽는 로직을 관리할 새로운 Code Repositories를 생성합니다. 이 로직은 해당 파일들을 모델 어댑터로 감싸고 모델로 발행합니다. Code Repositories 애플리케이션에서, Model Training 언어 템플릿을 사용하여 Model Integration 저장소를 초기화하도록 선택합니다.
Model Training template 및 model adapter API에 대한 전체 문서를 참고하세요.
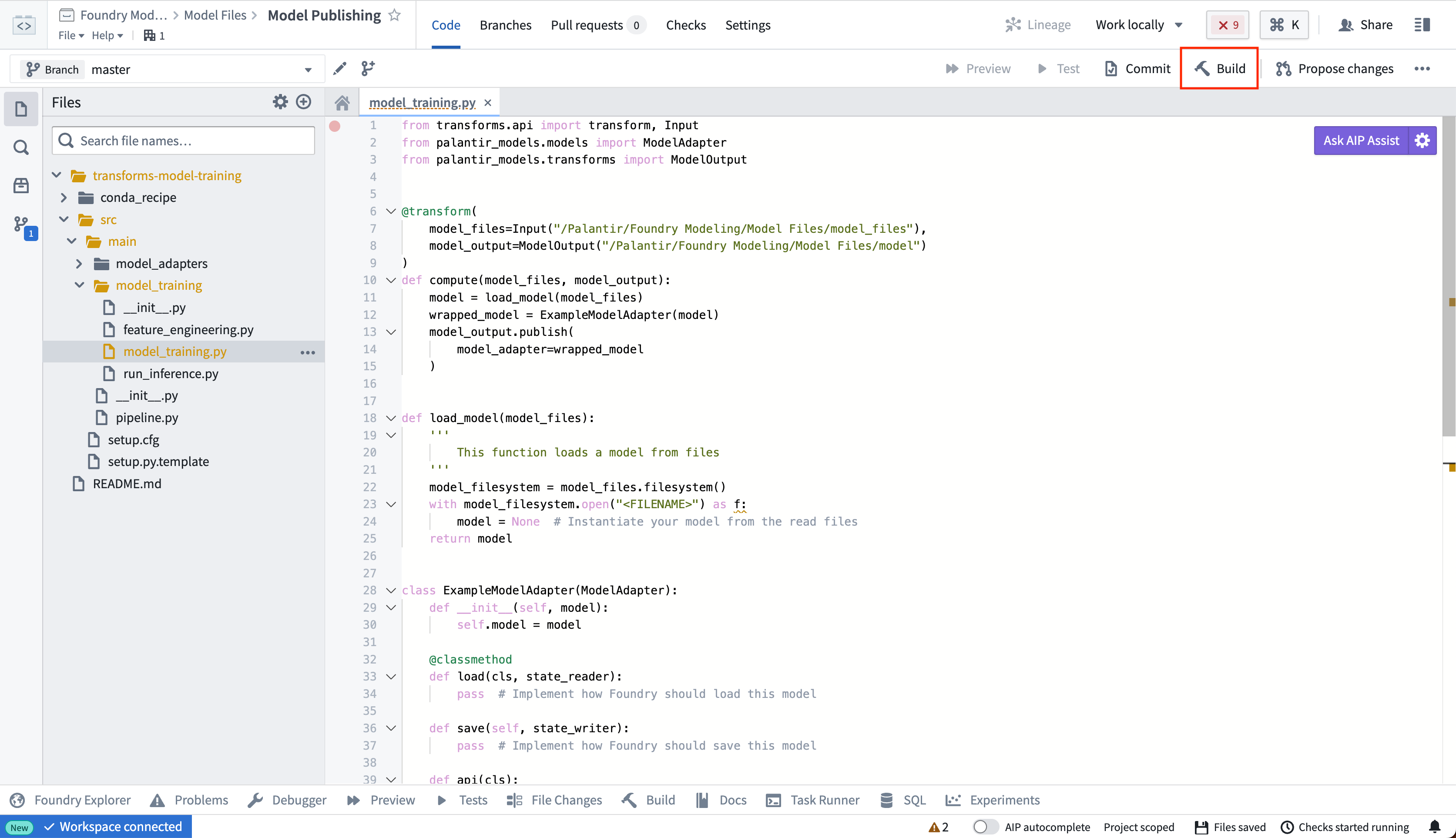
3. 모델에 가중치 발행하기
비구조화된 데이터셋의 모델 파일을 Palantir 모델로 발행하려면, 다음을 완료하는 변환을 작성해야 합니다:
- 비구조화된 데이터셋에서 저장된 모델 파일 로드하기
- 모델 어댑터 인스턴스화하기
- 모델 어댑터를 모델 리소스로 발행하기
모델 로드 및 발행 로직을 저장소 내의 model_training 폴더에 위치시킬 수 있습니다.
추가 정보를 위해, 다음 문서를 검토하는 것을 추천합니다:
- 전체 Model Adapter API 정의
- 비구조화된 데이터셋에서 파일 읽는 방법
- Model Training template를 사용하여 모델 어댑터 생성 및 발행하는 방법
- 로컬에서 훈련된 모델의 예시 감싸기
모델 훈련 로직을 정의한 후, Build를 선택하여 모델 파일을 읽고 모델을 발행하는 로직을 실행합니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36# Palantir Foundry에서 사용되는 모듈을 import합니다. from transforms.api import transform, Input from palantir_models.transforms import ModelOutput, copy_model_to_driver import palantir_models as pm import palantir_models_serializers as pms # 'transform' 데코레이터를 이용해 데이터셋을 트랜스폼합니다. @transform( model_files=Input("<Model Files Dataset>"), # 입력받을 모델 파일 데이터셋 model_output=ModelOutput("<Your Model Path>") # 모델 결과물을 저장할 경로 ) def compute(model_files, model_output): model = copy_model_to_driver(model_files.filesystem()) # 모델 파일을 드라이버에 복사합니다. wrapped_model = ExampleModelAdapter(model) # 모델을 ExampleModelAdapter로 감싸서 사용합니다. model_output.publish( # 모델 결과물을 publish합니다. model_adapter=wrapped_model ) # ExampleModelAdapter 클래스는 모델을 감싸서 사용하기 위한 클래스입니다. class ExampleModelAdapter(pm.ModelAdapter): # '__init__' 메소드는 객체 초기화를 위해 사용되며, 'auto_serialize' 데코레이터를 이용해 객체를 직렬화합니다. @pm.auto_serialize( model=pms.DillSerializer() # DillSerializer를 이용해 모델을 직렬화합니다. ) def __init__(self, model): self.model = model # 모델을 초기화합니다. # 'api' 메소드는 이 모델의 API를 구현하기 위해 사용됩니다. def api(cls): pass # 여기에 모델의 API를 구현합니다. # 'predict' 메소드는 입력 데이터에 대한 추론 로직을 구현하기 위해 사용됩니다. def predict(self, df_in): pass # 여기에 추론 로직을 구현합니다.
4. 발행된 모델 사용하기
모델을 성공적으로 발행한 후, 추론을 위해 모델을 사용할 수 있습니다. 아래 관련 문서를 참고하세요: