Code Repositories에서 모델 훈련하기
모델은 Model Training Template을 사용하여 Code Repositories 애플리케이션에서 훈련할 수 있습니다.
모델을 훈련하려면 다음 단계를 완료하세요:
1. 모델 어댑터 작성하기
모델은 Foundry가 모델을 올바르게 초기화, 직렬화, 역직렬화, 추론 수행을 보장하기 위해 모델 어댑터를 사용합니다. Code Repositories에서 Model Adapter Library 템플릿 또는 Model Training 템플릿 중 하나를 사용하여 모델 어댑터를 작성할 수 있습니다.
모델 어댑터는 파이썬 변환 저장소에서 직접 작성할 수 없습니다. 기존 저장소에서 모델을 생성하려면 Model Adapter Library를 사용하고 라이브러리를 변환 저장소로 가져오거나 Model Training 템플릿으로 마이그레이션하세요.
각 모델 어댑터 저장소 유형을 언제 사용하고 어떻게 생성하는지에 대한 자세한 내용은 Model Adapter creation 문서에서 확인하세요. 아래 단계는 Model Training 템플릿 사용을 가정합니다.
모델 어댑터 구현
모델 어댑터와 모델 훈련 코드는 훈련된 모델이 하위 변환에서 사용될 수 있도록 별도의 파이썬 모듈에 있어야 합니다. 템플릿에서는 이 목적으로 model_adapters와 model_training 모듈을 따로 구성했습니다. adapter.py 파일에 모델 어댑터를 작성하세요.
모델 어댑터 정의는 훈련 중인 모델에 따라 달라집니다. 자세한 내용은 ModelAdapter API 참조를 참조하거나 예제 sklearn 모델 어댑터를 검토하고 지도 학습 튜토리얼을 읽어보세요.
2. 파이썬 변환 작성하여 모델 훈련하기
다음으로 Code Repositories에서 훈련 로직을 담을 새 파이썬 파일을 만드세요.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24from transforms.api import transform, Input from palantir_models.transforms import ModelOutput from model_adapter.example_adapter import ExampleModelAdapter # 이것은 사용자 지정 ModelAdapter입니다. @transform( training_data=Input("/path/to/training_data"), model_output=ModelOutput("/path/to/model") # 이것은 모델 경로입니다. ) def compute(training_data, model_output): ''' 이 함수는 Foundry에서 읽고 쓰기 위한 로직을 포함합니다. ''' trained_model = train_model(training_data) # 1. 파이썬 변환에서 모델을 학습시킵니다. wrapped_model = ExampleModelAdapter(trained_model) # 2. 학습된 모델을 사용자 지정 ModelAdapter로 래핑합니다. model_output.publish( # 3. 래핑된 모델을 Foundry에 저장합니다. model_adapter=wrapped_model # Foundry는 ModelAdapter.save를 호출하여 모델을 생성합니다. ) def train_model(training_data): ''' 이 함수는 사용자 지정 훈련 로직을 포함합니다. ''' pass
이 로직은 ModelOutput에 게시됩니다. 변경 사항을 커밋한 후에는 지정된 경로에서 Foundry가 모델 리소스를 자동으로 생성합니다. 또한 @configure 주석을 사용하여 모델 훈련에 필요한 CPU, 메모리, GPU 요구 사항과 같은 필요한 리소스를 구성할 수도 있습니다.
3. Python 변환기를 미리 보기하여 로직 테스트하기
Code Repositories 애플리케이션에서 미리보기를 선택하여 전체 빌드를 실행하지 않고 변환 로직을 테스트할 수 있습니다. 미리보기는 @configure 주석으로 구성한 것보다 작은 리소스 프로필에서 실행됩니다.
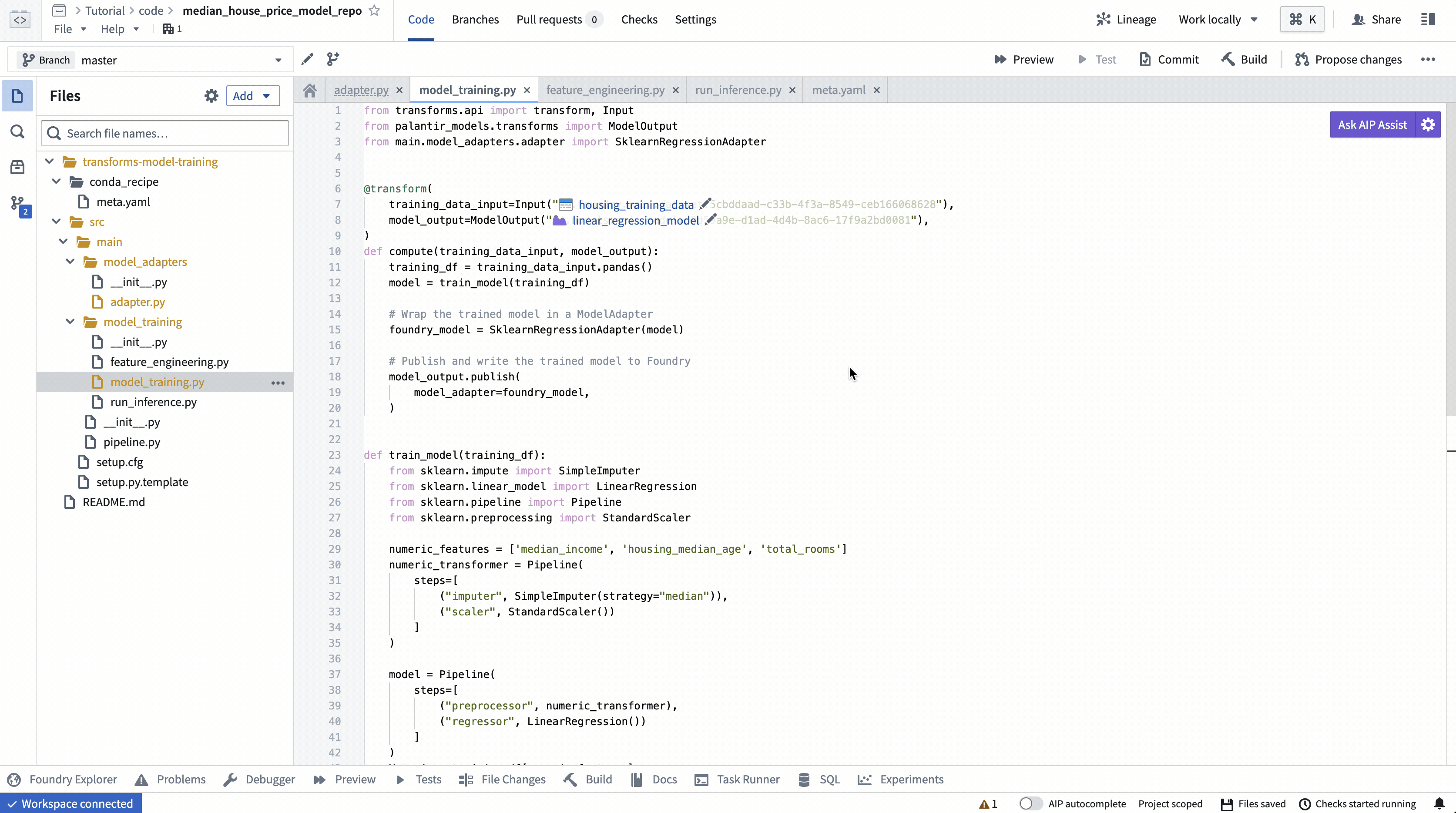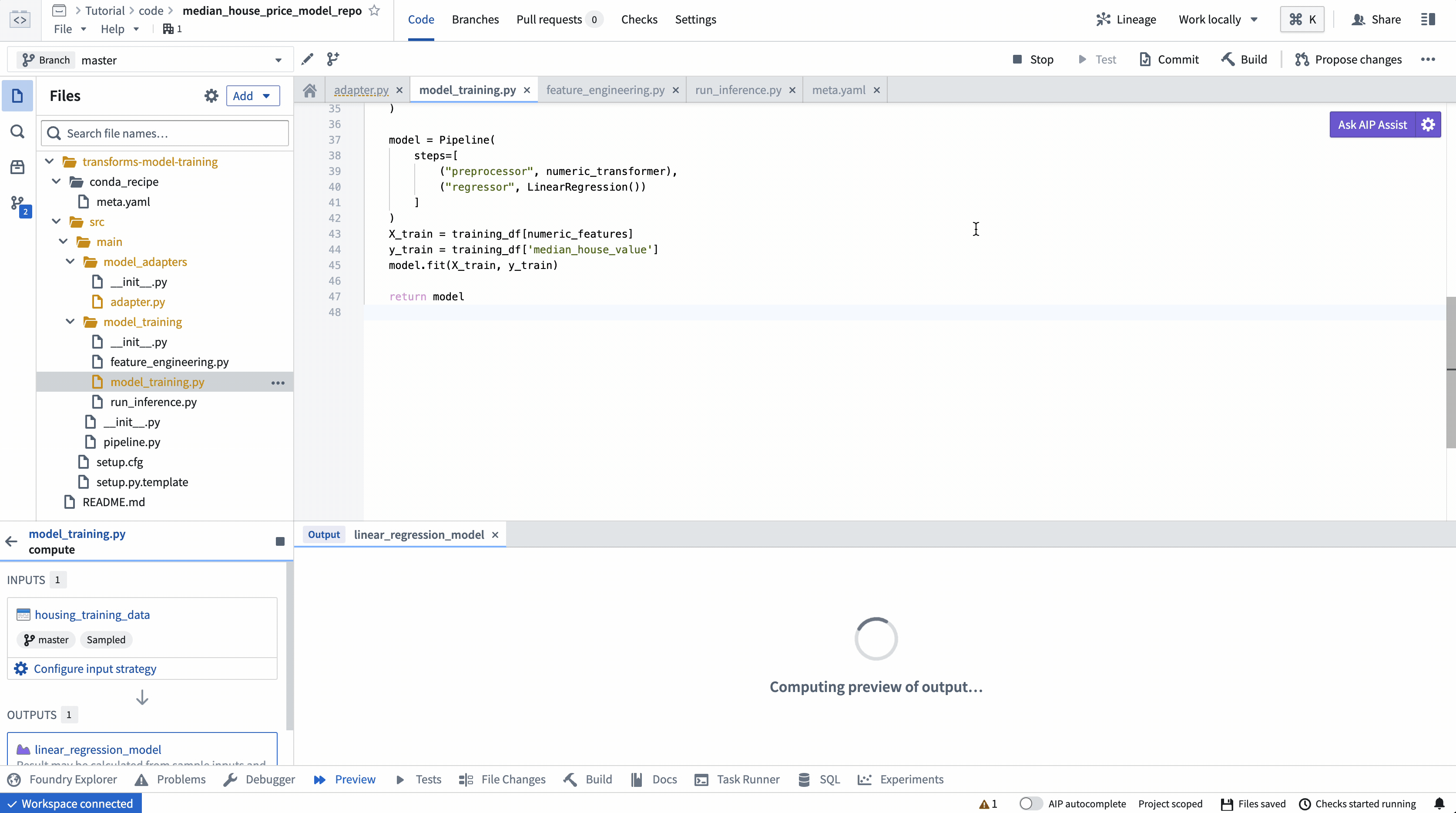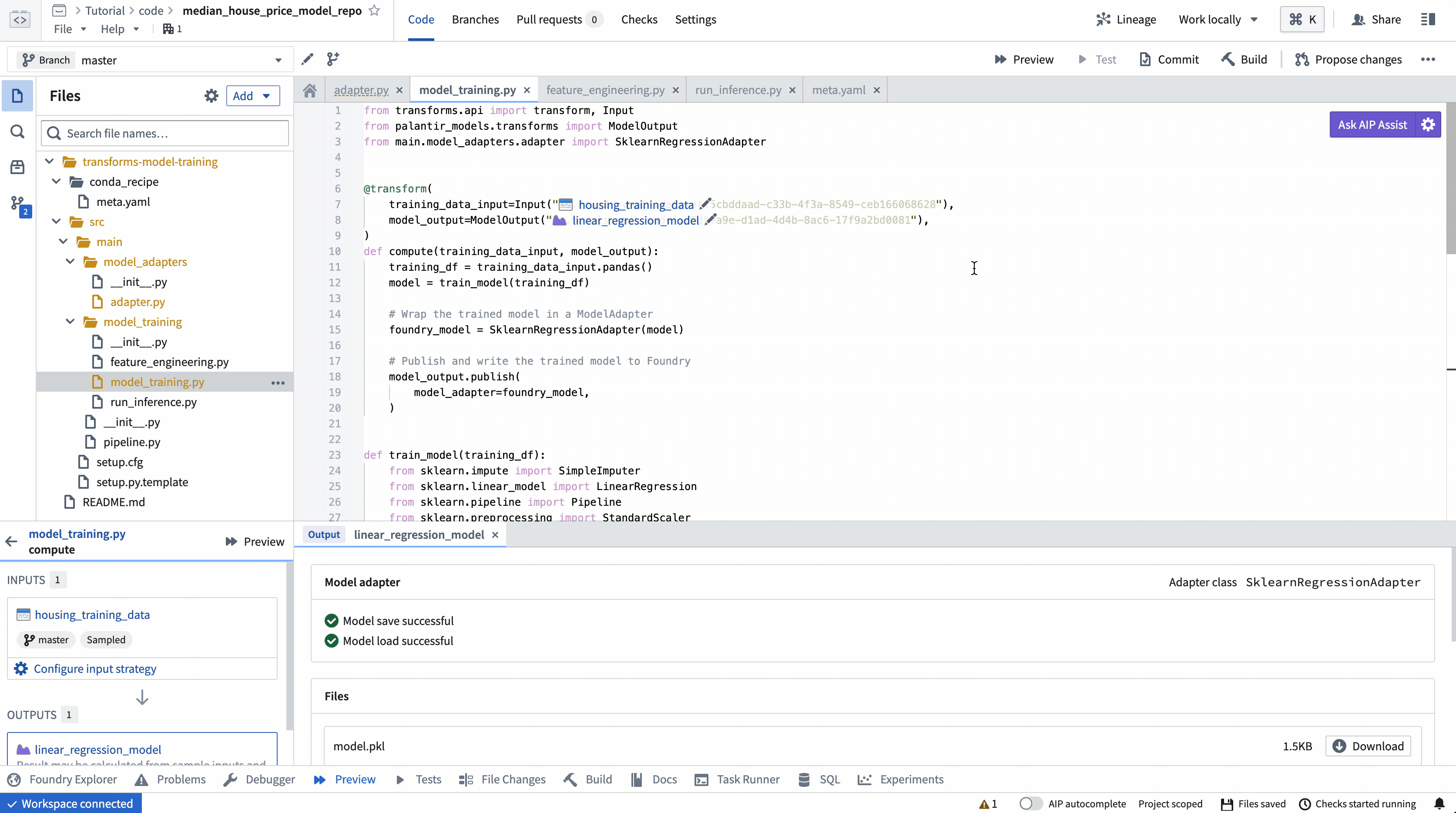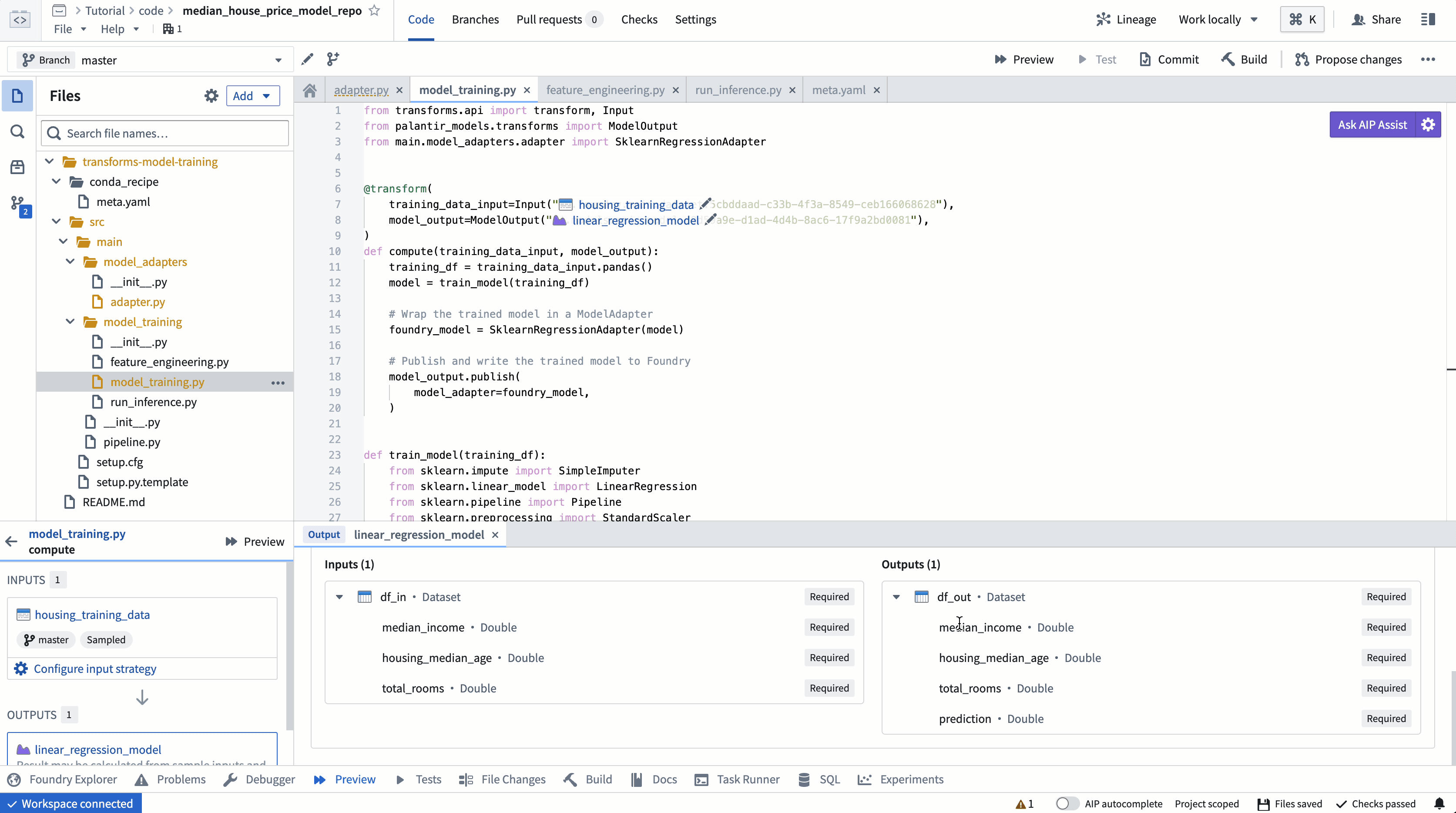
ModelOutput 미리보기
ModelOutput 미리보기를 사용하면 모델 훈련 로직과 모델 직렬화, 역직렬화 및 API 구현을 검증할 수 있습니다.
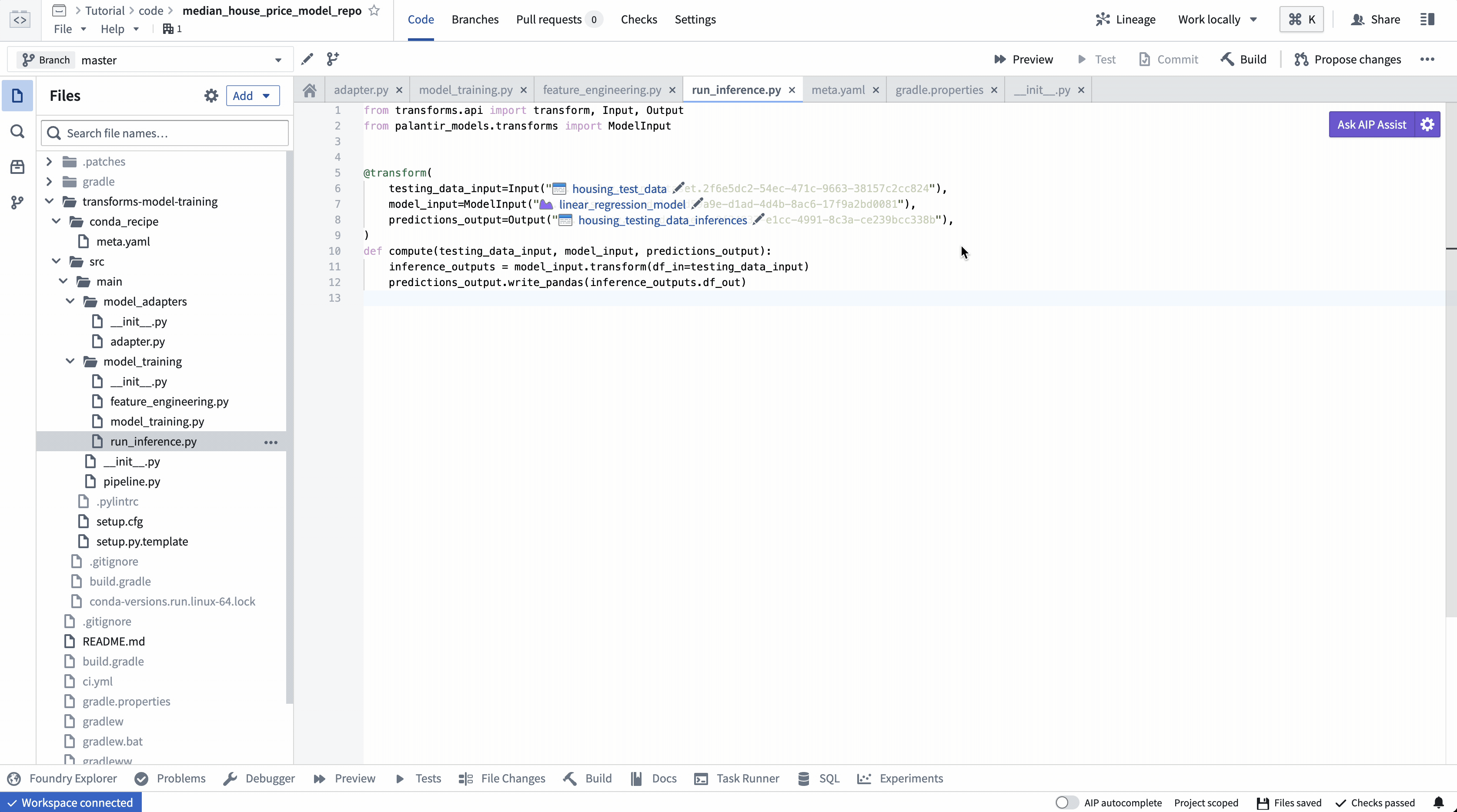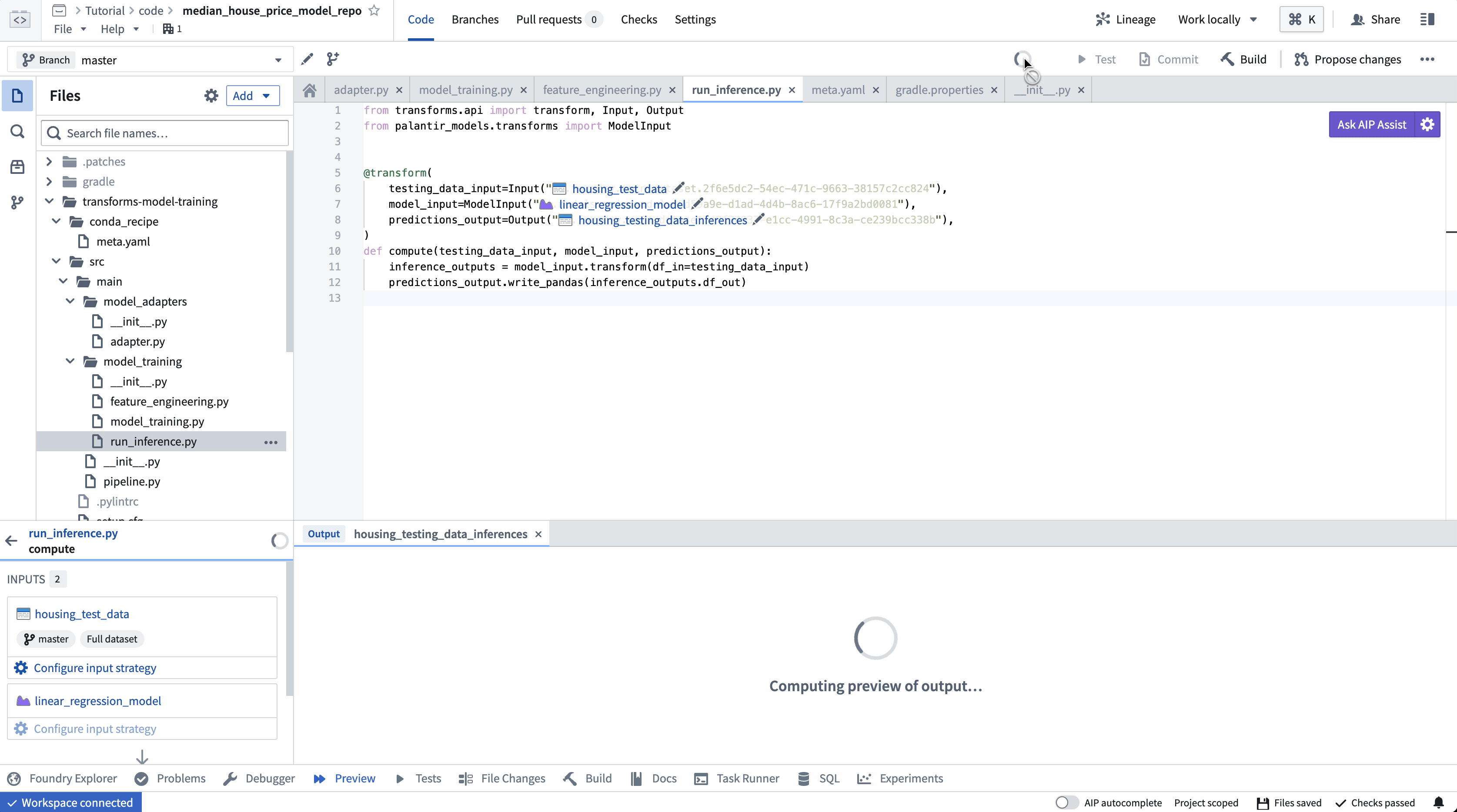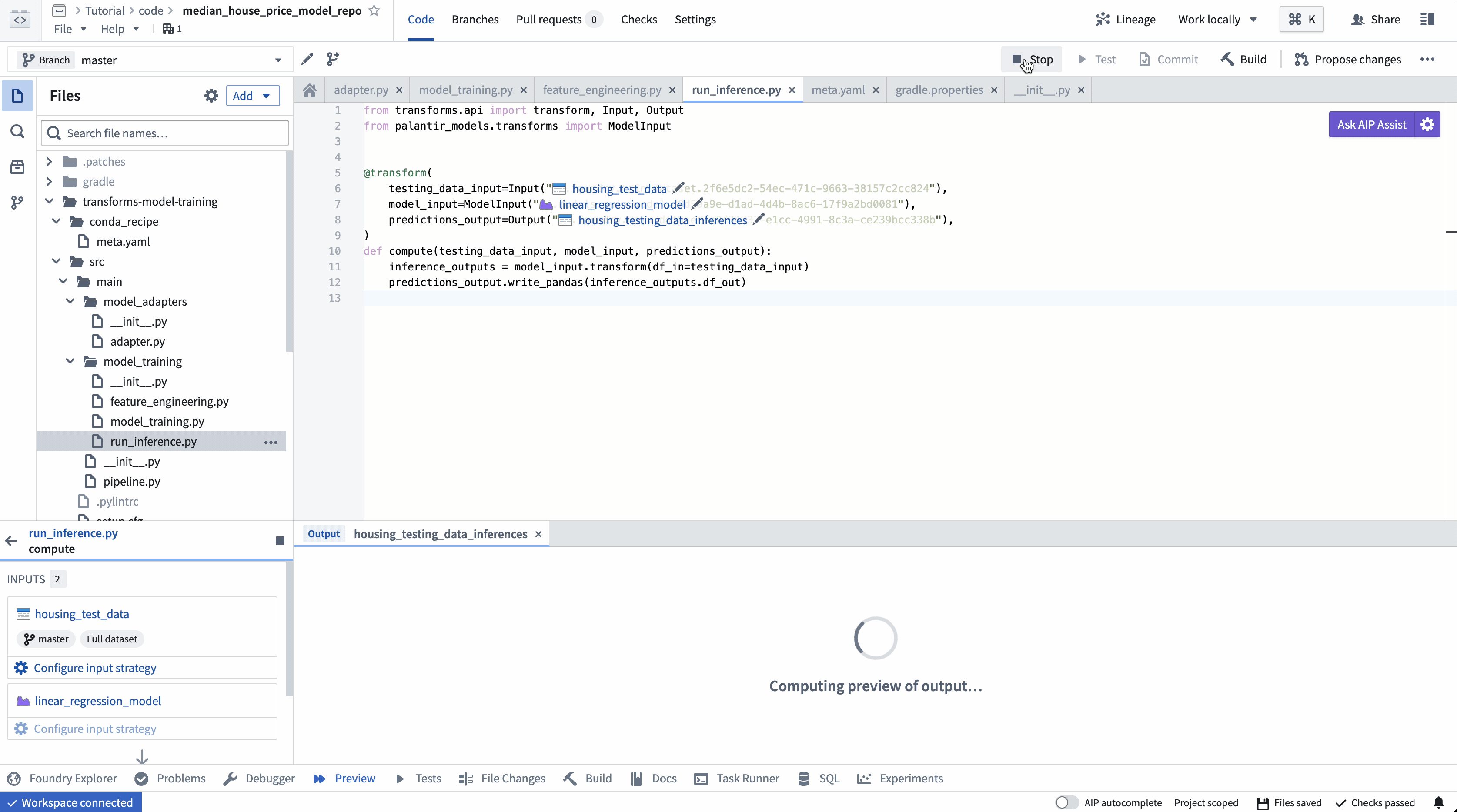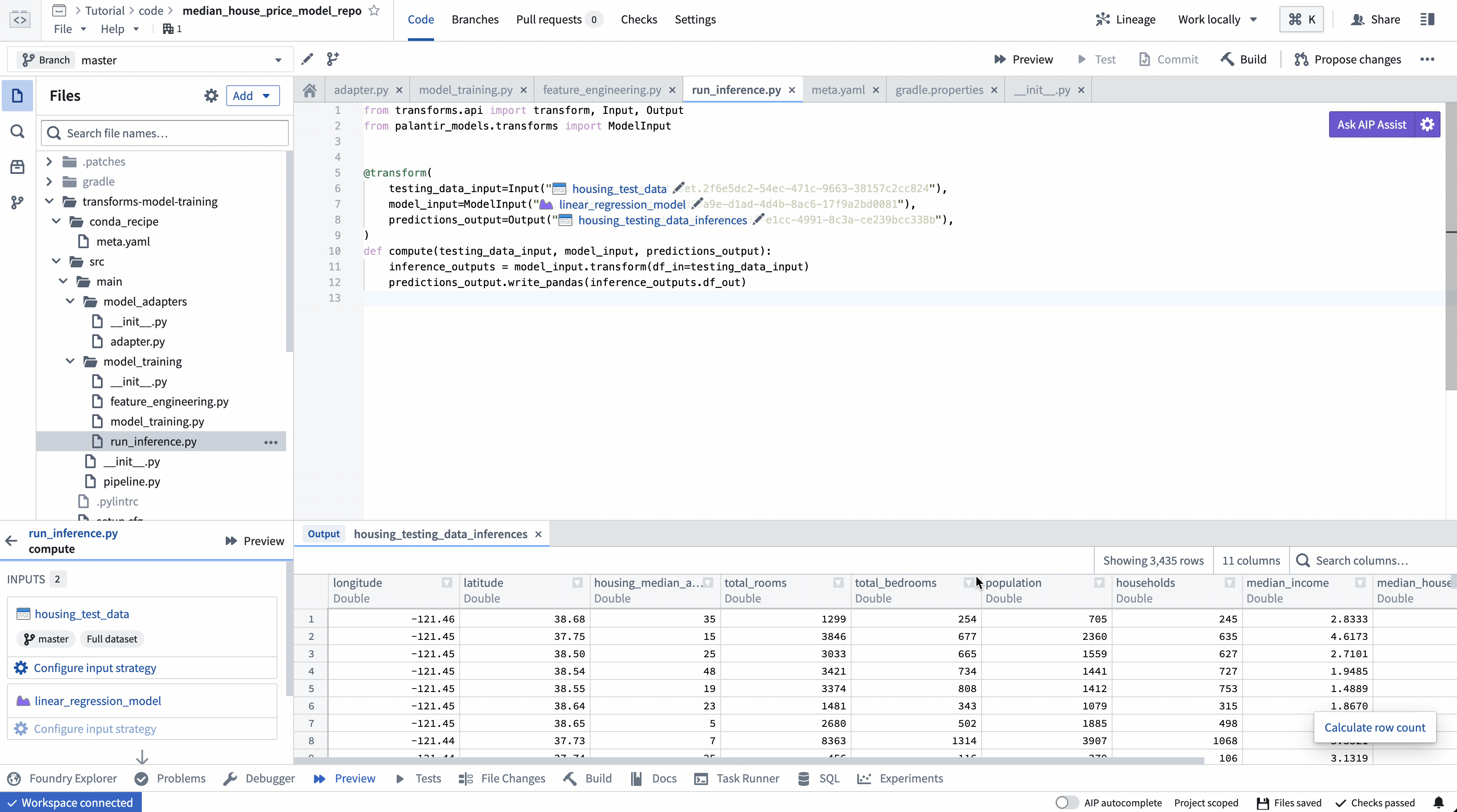
ModelInput 미리보기
ModelInput 미리보기를 사용하면 기존 모델에 대한 추론 로직을 검증할 수 있습니다. Code Repositories에서 미리보기를 사용하면 각 ModelInput에 대해 5GB 크기 제한이 있습니다.
4. 훈련된 모델을 게시하기 위해 Python 변환기 빌드하기
Code Repositories에서 빌드를 선택하여 변환기를 실행합니다. Foundry는 Python 종속성과 모델의 종속성을 모두 해결한 후 훈련 로직을 실행합니다.
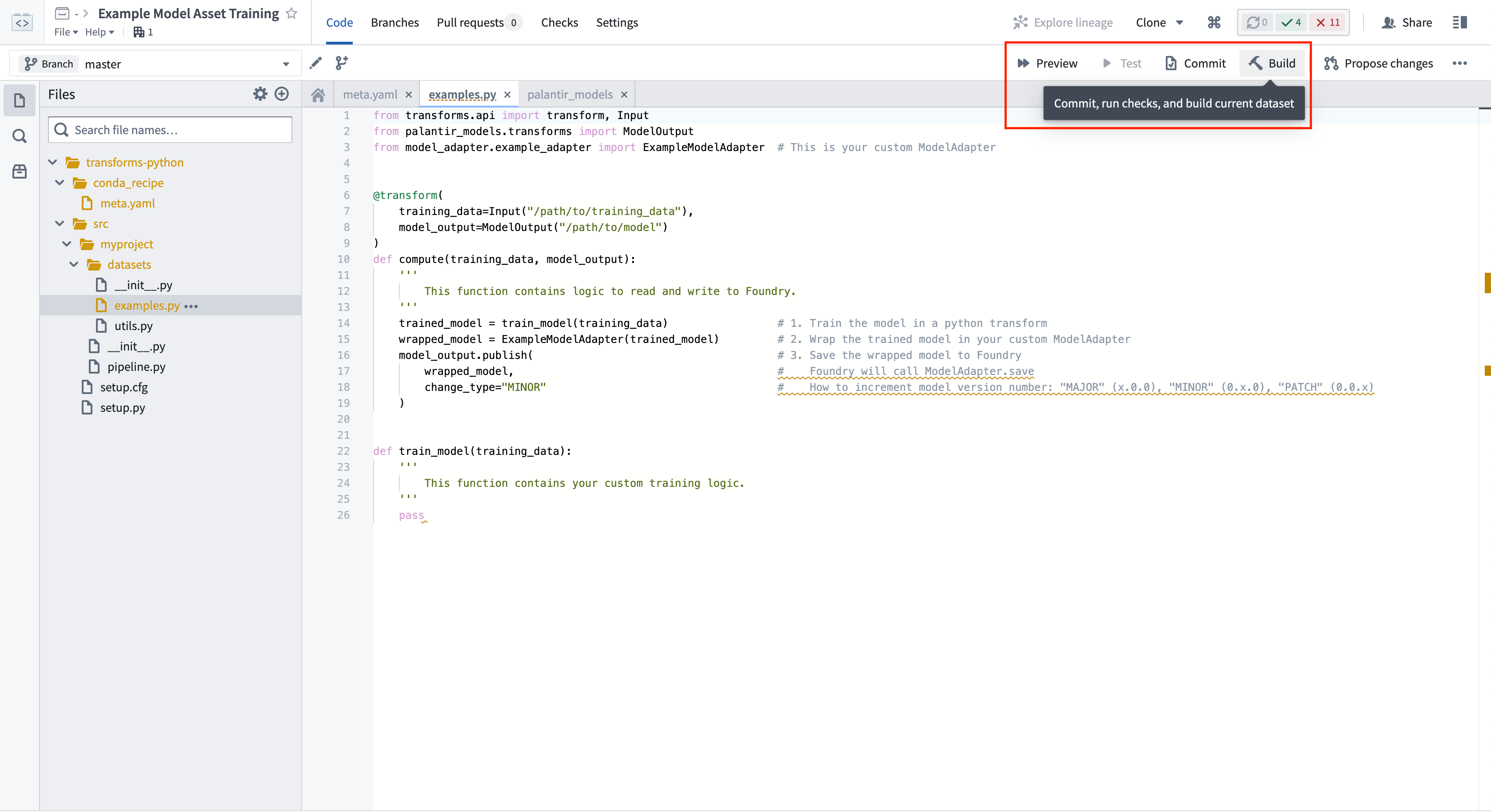
ModelOutput.publish()를 호출하면 Foundry에 모델 버전이 게시됩니다. Foundry는 ModelAdapter.save() 함수를 호출하고 ModelAdapter에 필요한 모든 필드의 직렬화를 할 수 있는 기능을 제공합니다.
5. 모델 사용하기
Modelling Objective에 제출하기
모델은 다음을 위해 Modelling Objective에 게시될 수 있습니다:
Python 변환기에서 추론 실행하기
아래와 같이 파이프라인에서 Palantir 모델을 사용할 수도 있습니다.
다른 Python 변환기 리포지토리에서 모델을 사용하는 경우, 작성 Python 환경에 모델 어댑터 Python 라이브러리를 추가해야 합니다. 이는 대개 Palantir의 모델 리소스 페이지에서 찾을 수 있습니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14from transforms.api import transform, Input, Output from palantir_models.transforms import ModelInput @transform( inference_output=Output("/path/to/inference_output"), #출력 경로 지정 inference_input=Input("/path/to/inference_input"), #입력 경로 지정 model=ModelInput("/path/to/model"), # 모델 경로 지정 ) def compute(inference_output, inference_input, model): # model은 ExampleModelAdapter의 인스턴스일 것입니다. inference_results = model.transform(inference_input) # inference_results는 predict() 또는 run_inference() 메소드의 반환 결과가 될 것입니다. # "output_data"를 모델 버전의 API에서 지정된 출력으로 대체하십시오. 이는 모델 버전의 웹 페이지에서 확인할 수 있습니다. # 예를 들어, inference_results.output_data는 Hugging Face adapters에 적합한 출력입니다. inference = inference_results.output_data inference_output.write_pandas(inference) # pandas 형식으로 결과를 출력합니다.
ModelInput 및 ModelOutput API
위의 변환에서 호출된 ModelInput 및 ModelOutput 오브젝트는 Code Repositories의 모델과 직접 상호 작용하는 오브젝트입니다. 오브젝트의 요약은 다음과 같습니다:
ModelInput
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13# ModelInput은 palantir_models.transforms에서 가져올 수 있습니다. class ModelInput: def __init__(self, model_rid_or_path: str, model_version: Optional[str] = None): ''' `ModelInput`은 변환에 사용할 기존 모델을 검색합니다. 최대 두 개의 인수를 사용합니다: 1. 모델 경로 (또는 모델의 RID). 2. (선택 사항) 검색할 모델의 버전 RID. 이를 제공하지 않으면 가장 최근에 게시된 모델이 사용됩니다. 예를 들어: ModelInput("/path/to/model/asset") ''' pass
transform 함수에서 ModelInput으로 지정된 모델은 검색된 모델 버전과 관련된 모델 어댑터의 인스턴스로 인스턴스화됩니다. Foundry는 ModelAdapter.load를 호출하거나 정의된 @auto_serialize 인스턴스를 사용하여 모델을 설정한 후 변환 빌드를 시작합니다. 따라서 ModelInput 인스턴스는 연결된 로드된 모델 상태와 모델 어댑터에 정의된 모든 메서드에 접근할 수 있습니다.
모델 결과물(ModelOutput)
Copied!1 2 3 4 5 6 7 8 9 10# ModelOutput은 palantir_models.transforms에서 가져올 수 있습니다. class ModelOutput: def __init__(self, model_rid_or_path: str): ''' `ModelOutput`은 모델에 새로운 버전을 게시하는 데 사용됩니다. `ModelOuput`은 하나의 인수를 사용하며, 이는 모델의 경로(또는 모델 RID)입니다. 아직 자산이 없는 경우, 사용자가 커밋 또는 빌드를 선택하고 변환 검사(CI)가 실행될 때 ModelOutput이 자산을 생성합니다. ''' pass
transform 함수에서, ModelOutput에 할당하여 검색된 오브젝트는 publish() 메서드를 사용하여 새로운 모델 버젼을 발행할 수 있는 WritableModel입니다. 이 메서드는 모델 어댑터를 파라미터로 받아 그와 연관된 새로운 모델 버젼을 생성합니다. publish() 도중에, 플랫폼은 정의된 @auto_serialize 인스턴스를 사용하거나 구현된 save() 메서드를 실행합니다. 이를 통해 모델 어댑터는 모델 파일이나 체크포인트를 state_writer 오브젝트에 직렬화할 수 있습니다.