API: 언어 모델 어댑터
각각의 노코드 언어 모델에 대해, Foundry는 기본적인 모델 어댑터를 제공합니다. 이 기본 모델 어댑터는 언어 모델과 상호 작용하는데 있어 합리적인 기본 파라미터와 구조를 제공합니다. 아래에 나열된 기본 언어 모델 어댑터는 배포 인프라의 가용성에 따라 CPU와 GPU 장치로 올바르게 라우팅됩니다.
현재 사용 중인 모델 어댑터는 Modelling Objective 애플리케이션의 모델 제출 페이지에서 볼 수 있습니다.
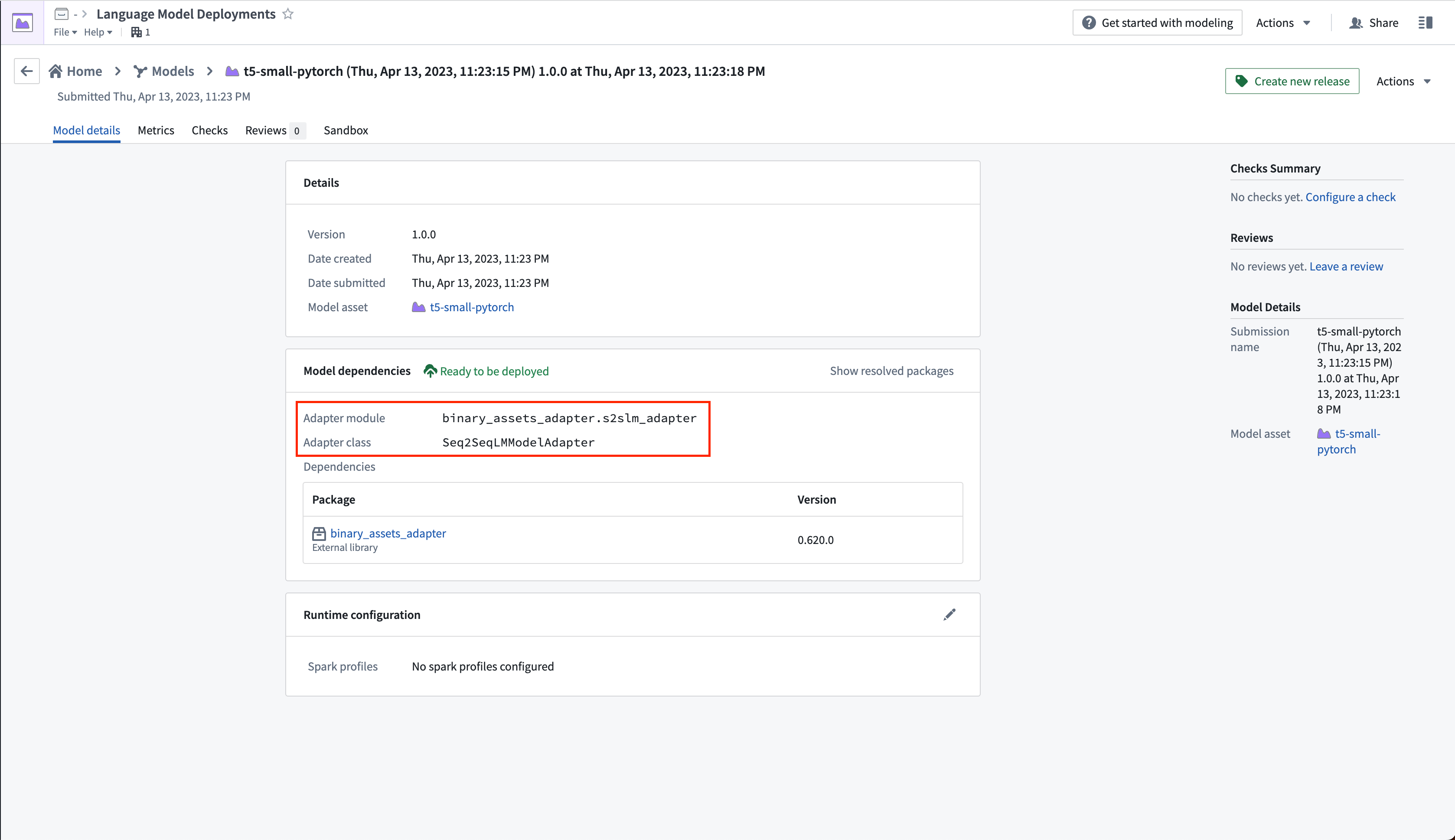
Seq2SeqLMModelAdapter
사용법
이 모델 어댑터는 시퀀스-투-시퀀스 언어 모델에 대한 지원을 추가합니다. 어댑터는 제공된 입력 텍스트에 기반하여 텍스트를 생성합니다.
예시: 예상 입력 텍스트와 그 구조는 선택된 모델에 따라 달라집니다. 우리는 올바른 프롬프트 엔지니어링을 보장하기 위해 모델 상세를 읽는 것을 강력히 추천합니다. 예를 들어, flan-t5-large 모델은 번역부터 요약, 질문에 대한 답변까지 다양한 프롬프트를 수행할 수 있습니다.
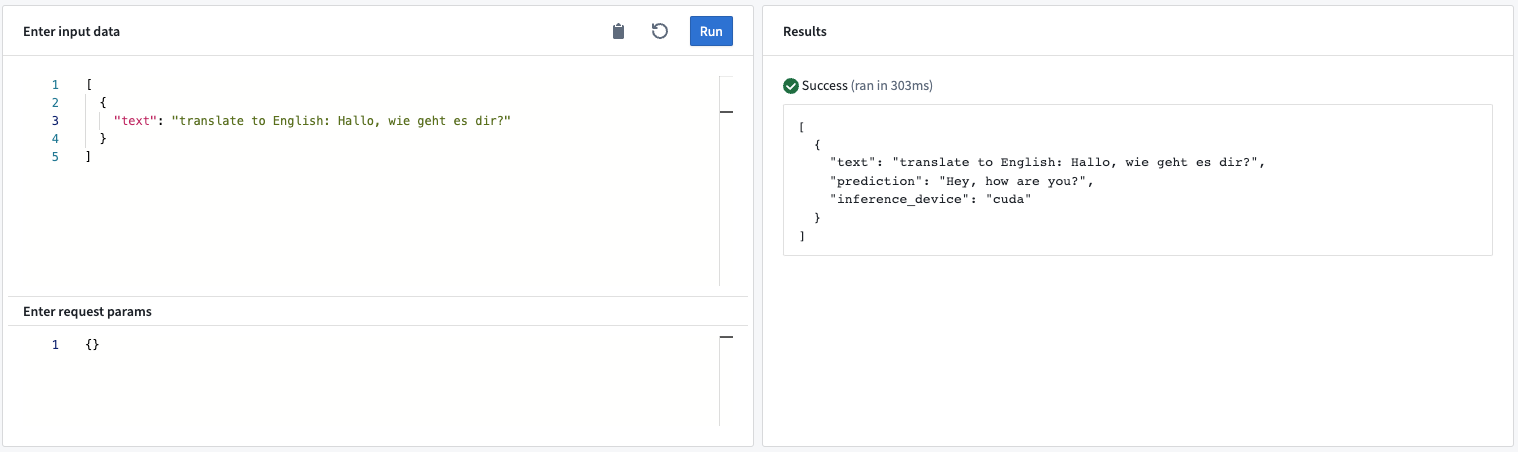
모델 API
- 입력<스트링> “텍스트”: 언어 모델이 결과물 예측을 생성하기 위한 텍스트 입력.
- 결과물<스트링> “예측”: 모델에 의해 생성된 텍스트.
NerAdapter
사용법
이 모델 어댑터는 Named Entity Recognition pipelines에 대한 지원을 추가합니다. 모델 어댑터는 텍스트 내의 엔티티를 추출하고 목록으로 반환합니다.
예시: 텍스트 "My name is Max and I live in Germany"를 샌드박스 또는 라이브 배포를 통해 모델에 보낼 때, 모델은 두 개의 엔티티를 인식합니다: Max와 Germany.
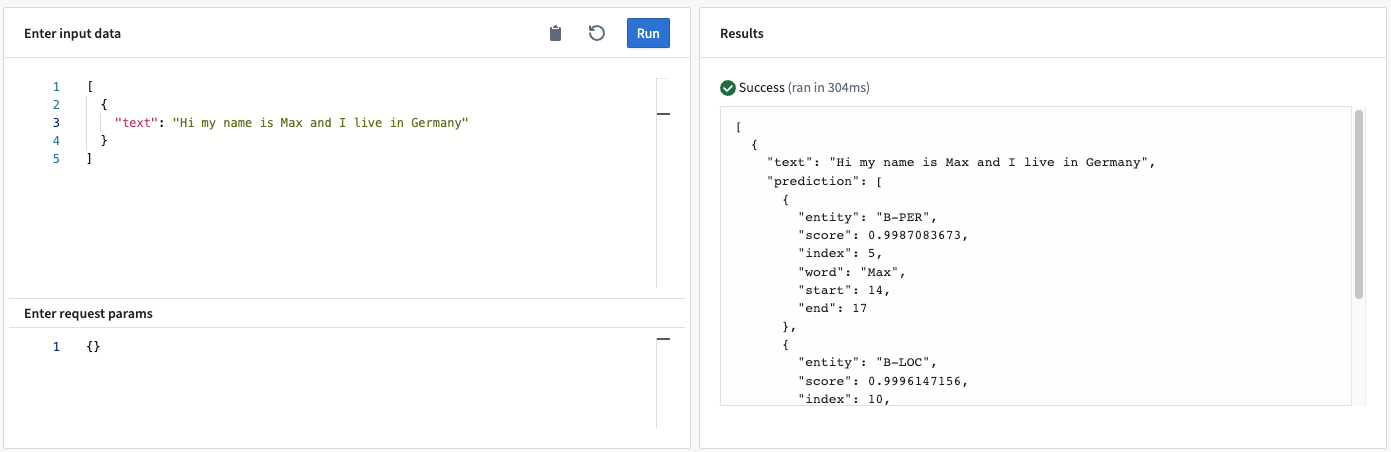
모델 API
- 입력<스트링> “텍스트”: 언어 모델이 결과물 예측을 생성하는 텍스트.
- 결과물<목록<사전>> “예측”: 모델의 결과물은 각 사전이 추출된 엔티티에 대한 상세 정보를 제공하는 사전의 목록입니다. 특히, 사전에는 다음이 포함됩니다:
- 엔티티: 인식된 엔티티의 유형.
- 점수: 특정 엔티티의 수치 점수.
- 인덱스: 엔티티의 토큰의 인덱스 (예를 들어, 인덱스
5는 인식된 엔티티가 입력 텍스트의 다섯 번째 토큰이라는 것을 의미합니다). - 단어: 인식된 엔티티의 스트링 표현.
- 시작: 입력 스트링에서 인식된 엔티티의 시작 인덱스.
- 끝: 입력 스트링에서 인식된 엔티티의 끝 인덱스.
EmbeddingAdapter
사용법
이 모델 어댑터는 모델의 attention mask에 기반하여 주어진 텍스트에 대한 임베딩을 계산합니다. 이 어댑터는 "평균 풀링"과 정규화를 수행하며, 이는 sentenced-transformers의 기본값과 일치합니다.
예시:
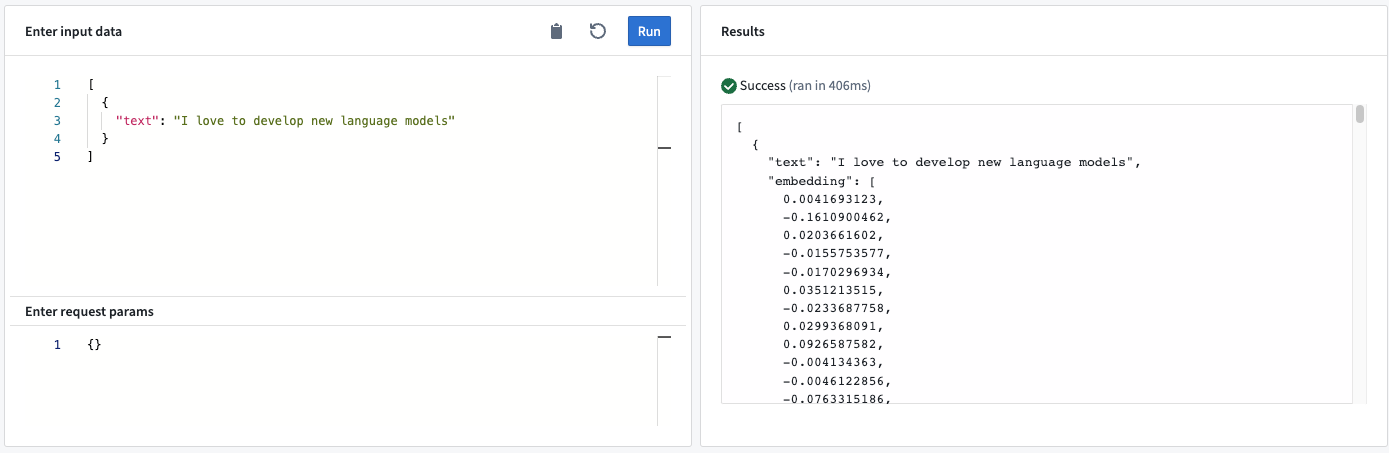
모델 API
- 입력<스트링> “텍스트”: 임베딩 모델에 대한 입력 텍스트.
- 결과물<목록<실수>> “임베딩”: 입력 텍스트를 나타내는 n-차원 벡터.
TextClassificationAdapter
사용법
이 모델 어댑터는 사전 정의된 클래스 세트에 대한 입력 텍스트를 분류합니다. 텍스트 분류의 일반적인 예시로는 감성 또는 언어 감지가 있습니다.
예시:
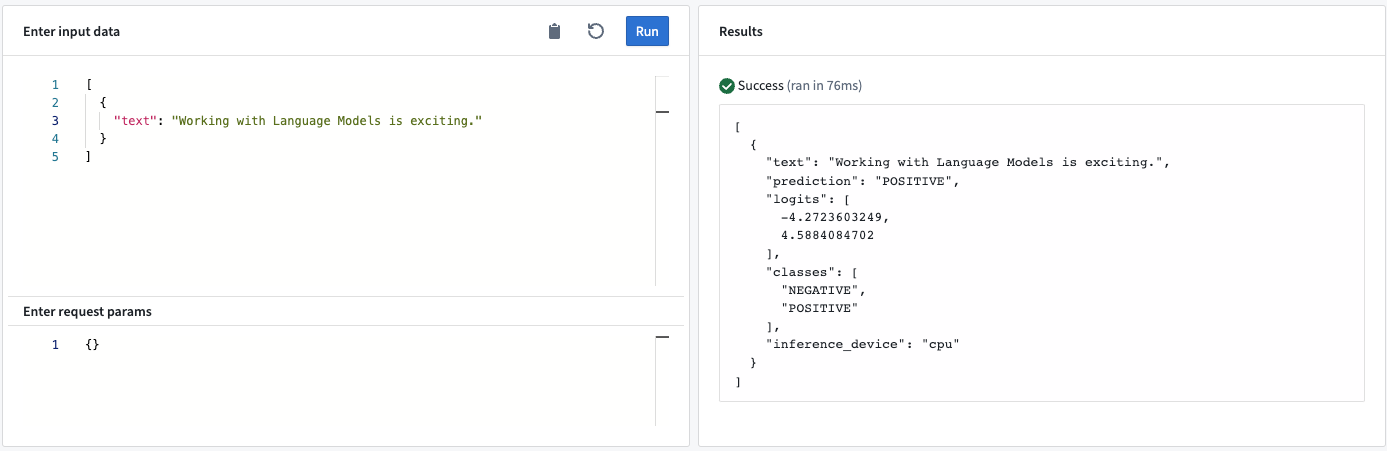
모델 API
- 입력<스트링> “텍스트”: 언어 모델이 결과물 예측을 생성하기 위한 입력 텍스트.
- 결과물<스트링> “예측”: 가장 가능성이 높은 클래스.
- 결과물<목록<실수>> “로그값”: 각 클래스에 대한 로그값.
- 결과물<목록<스트링>> “클래스”: 모델이 예측할 수 있는 클래스. 순서는 로그값의 순서와 동일합니다 (예를 들어, 첫 번째 로그값 항목은 클래스 목록의 첫 번째 항목에 해당합니다).
ZeroShotClassificationAdapter
사용법
이 모델 어댑터는 예측 시간에 제공된 클래스 목록에 기반하여 입력 텍스트를 분류합니다. 이 동작은 특정 유즈케이스에 언어 모델을 세부 조정할 필요 없이 텍스트를 분류하게 해주는 모델 어댑터를 가능하게 합니다.
예시: 텍스트 “I love to develop new language models”와 후보 레이블 “Travel”, “Sports”, “Work”, and “Entertainment”를 보낼 때, 모델은 레이블을 점수화하고 "Work"를 가장 가능성이 높은 분류로 순위를 매깁니다.
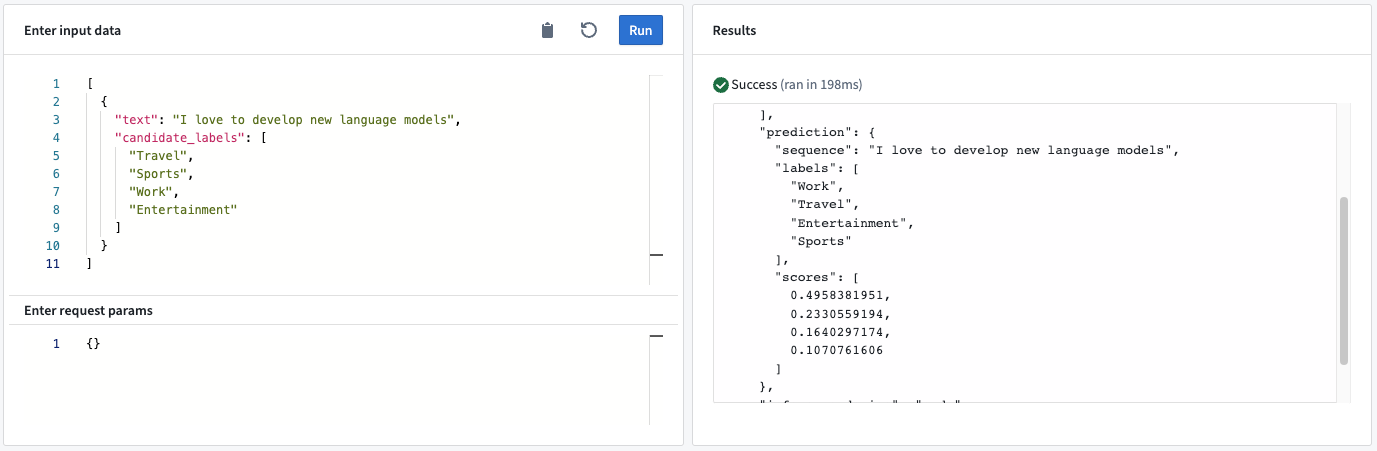
모델 API
- 입력<스트링> “텍스트”: 언어 모델이 결과물 예측을 생성하기 위한 입력 텍스트.
- 입력<목록<스트링>> “후보_레이블”: 모델이 점수를 매기는 입력 텍스트에 대한 가능한 레이블의 목록.
- 결과물<사전> “예측”:
- 시퀀스: 제로샷 분류에 사용된 텍스트.
- 레이블: 모델 점수에 기반하여 내림차순으로 정렬된 후보 레이블.
- 점수: 후보 레이블에 대한 분류 점수를 나타내는 실수. 점수의 순서는 레이블의 순서와 일치합니다.