사용자 정의 모델을 사용하여 시맨틱 검색 워크플로 만들기
이 튜토리얼은 Palantir에서 제공하지 않는 임베딩 모델을 사용하는 사용자를 대상으로 합니다. Palantir에서 제공하는 모델 목록과 Palantir에서 제공하는 모델 시맨틱 검색 튜토리얼을 참조하십시오.
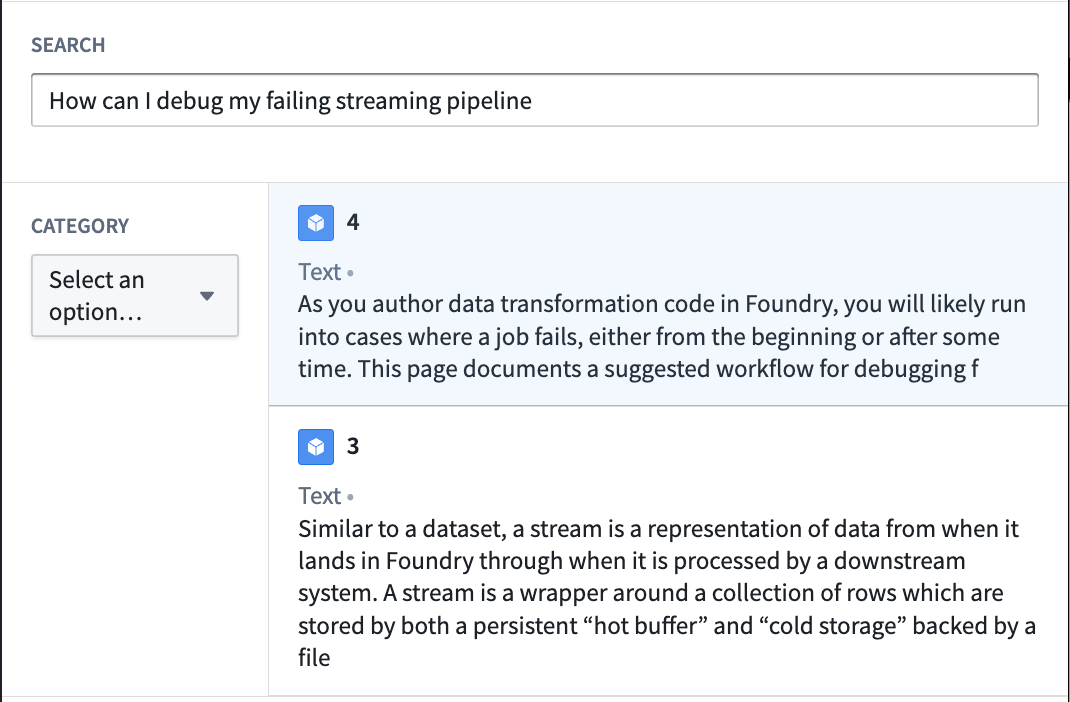
이 페이지는 프롬프트가 주어지면 관련 문서를 검색할 수 있는 가상의 end-to-end 문서 검색 서비스를 빌드하는 과정을 보여줍니다. 이 서비스는 Foundry Modelling Objective를 사용하여 문서를 임베딩하고 그 기능을 벡터로 추출합니다. 이러한 문서와 임베딩은 벡터 속성이 있는 오브젝트 유형에 저장됩니다.
이 예제에서는 Foundry에서 모델을 설정하고 임베딩을 생성하는 파이프라인을 만드는 것으로 시작합니다. 그런 다음 새로운 오브젝트 유형과 이를 자연어로 쿼리하는 function을 생성할 것입니다.
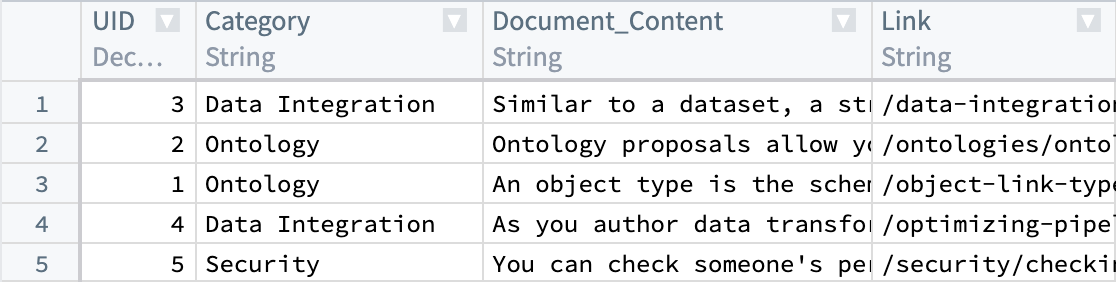
우리가 가지고 있는 데이터셋으로 시작하여, Document_Content와 Link와 같은 파싱된 문서와 메타데이터가 현재 있습니다. 다음으로, Document_Content에서 임베딩을 생성하여 시맨틱 검색을 통해 쿼리할 수 있도록 합니다.
KNN 기능의 세부 정보를 이해하려면 Foundry 문서의 KNN Functions on Objects 섹션을 검토하십시오.
이 워크플로에서는 각 인스턴스에서 일관성이 유지되는 한 원하는 값을 치환할 수 있습니다. 예를 들어, ObjectApiName의 모든 인스턴스는 항상 Document로 치환됩니다.
치환해야 하는 값은 다음과 같습니다:
ObjectApiName: 고유한 ObjectType을 위한 식별자, 이 경우Document. 참고: 식별자는 때때로 첫 글자가 소문자인objectApiName으로 나타날 수 있습니다.ModelApiName: 고유한 Model을 위한 식별자.OutputDatasetRid: 임베딩 변환에서 출력 데이터셋의 식별자.InputDatasetRid: 임베딩 변환의 입력 데이터셋 식별자.ModelRid: 임베딩 변환 및 Live Modeling Deployment 생성에 사용된 모델의 식별자.
1. Foundry에서 모델을 사용하여 임베딩 생성
Foundry에서 모델로부터 임베딩을 생성하는 몇 가지 옵션이 있습니다. 이 예제에서는 가져온 오픈소스 모델과 상호작용하는 변환을 생성하겠습니다. 우리는 all-MiniLM-L6-v2 모델을 사용할 것입니다. 이는 (크기) 384의 차원을 갖는 벡터를 생성하는 일반적인 목적의 텍스트 임베딩 모델입니다. 이 모델은 Foundry 온톨로지 vector 유형과 호환되는 벡터를 출력하는 기존 모델과 언제든지 교체될 수 있습니다. 새로운 오픈소스 모델을 가져오려면 언어 모델 문서를 검토하십시오.
이 예제에서는 이 모델을 가져와서 변환을 실행하여 임베딩을 생성하고 필요한 후처리를 수행합니다. 이 경우, 모델을 통해 데이터를 실행하여 embedding을 반환하고, 벡터 임베딩에 필요한 유형에 맞게 embedding 값 (이중 배열)을 부동수로 변환할 것입니다.
고려해야 할 몇 가지 사항은 다음과 같습니다:
schema변수의 각StructField는 처리된 입력 데이터셋(InputDatasetRid)에 존재하는 열과 모델에 의해 추가된embedding열에 관련이 있습니다.- 더 큰 규모의 데이터로 작업할 때, Pandas 데이터프레임이 과도하게 크면 변환이 실패할 수 있습니다. 이런 경우에는 변환이 Spark에서 수행되어야 합니다.
- 그래픽 처리 유닛(GPUs)은 변환이 임베딩을 생성하는 속도를 높이는 데 활용될 수 있습니다. GPUs는 변환에
@configure데코레이터를 추가함으로써 사용될 수 있습니다. 이 기능을 환경에서 활성화하려면 Palantir 담당자에게 문의하십시오.
아래에 변환 예제가 표시되어 있습니다:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39from transforms.api import configure, transform, Input, Output from palantir_models.transforms import ModelInput from pyspark.sql.functions import pandas_udf, PandasUDFType from pyspark.sql.types import StructType, StructField, IntegerType, StringType, FloatType, ArrayType import numpy as np @configure(profile=["DRIVER_GPU_ENABLED"]) # 만약 GPU가 환경에서 활성화되지 않았다면 이 줄을 삭제하세요. @transform( dataset_out=Output("OutputDatasetRid"), dataset_in=Input("InputDatasetRid"), embedding_model=ModelInput("ModelRid") ) def compute(ctx, dataset_out, dataset_in, embedding_model): # 모델의 입력 열과 일치시키기 spark_df = dataset_in.dataframe().withColumnRenamed("Document_Content", "text") def embed_df(df): # 임베딩 생성 output_df = embedding_model.transform(df).output_data # 실수 배열로 변환 output_df["embedding"] = output_df["embedding"].apply(lambda x: np.array(x).astype(float).tolist()) # 불필요한 열 삭제 return output_df.drop('inference_device', axis=1) # 업데이트된 스키마 schema = StructType([ StructField("UID", IntegerType(), True), StructField("Category", StringType(), True), StructField("text", StringType(), True), StructField("Link", StringType(), True), StructField("embedding", ArrayType(FloatType()), True) ]) udf = pandas_udf(embed_df, returnType=schema, functionType=PandasUDFType.GROUPED_MAP) output_df = spark_df.groupBy('UID').apply(udf) # 출력 DataFrame 쓰기 dataset_out.write_dataframe(output_df)
다음으로, 기존 벡터에 대해 검색하기 위해 사용자 쿼리를 기반으로 임베딩을 생성하는 라이브 모델링 배포가 필요합니다. 이 부분에서 사용되는 모델은 현재 단계에서 초기 임베딩을 생성하기 위해 사용된 것과 동일해야 합니다.
2. 오브젝트 유형 생성하기
이제, Foundry의 모델을 사용해 생성된 float 벡터 임베딩이 포함된 새로운 데이터셋이 있어야 합니다(이전 단계에서 참조). 다음으로 오브젝트 유형을 생성하겠습니다.
오브젝트 유형의 이름을 Document로 지정하고, embedding 속성을 Vector 속성 유형으로 설정합니다. 이때 두 가지 값을 설정해야 합니다:
- Dimension:
embedding컬럼에서 생성된 배열의 길이입니다. - Similarity Function: 두 개의
embedding값 사이의 거리가 어떻게 계산될지에 대한 방법입니다.
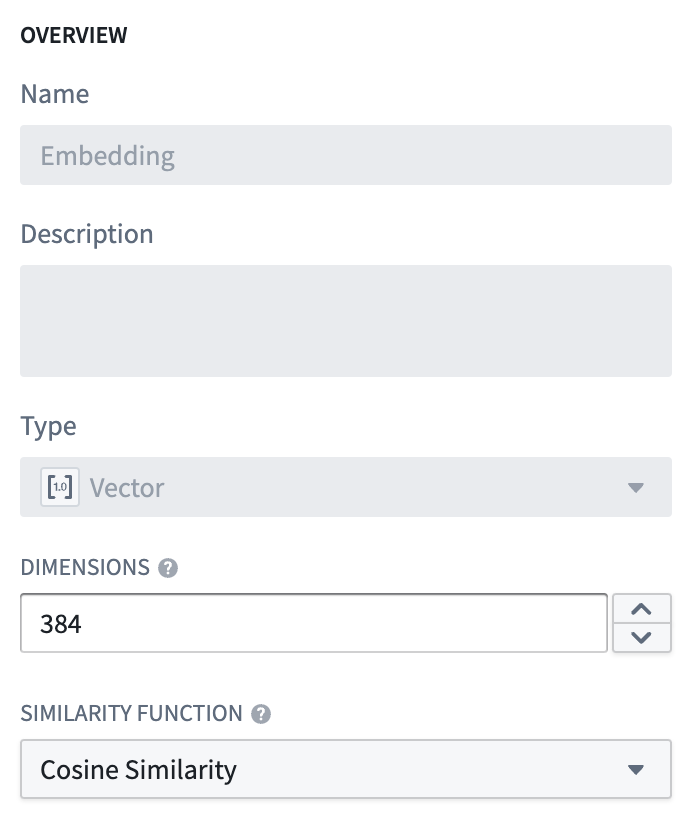
이 오브젝트 유형이 생성되면, Documentation 오브젝트를 시맨틱 검색하는 데 사용될 수 있는 속성(embedding)이 생깁니다.
ObjectApiName 값은 오브젝트 유형이 저장된 후에 사용할 수 있으며, 생성된 오브젝트 유형의 설정 페이지에서 찾을 수 있습니다. 이에 대한 자세한 정보는 오브젝트 유형 생성하기 문서의 해당 섹션에서 확인할 수 있습니다.
3. 라이브 모델링 배포 생성하기
이제 오브젝트에 임베딩이 속성으로 있으므로, 사용자 쿼리에 대해 임베딩을 저지연으로 생성해야 합니다. 이 임베딩은 유사한 임베딩 값을 가진 오브젝트를 찾는 데 사용됩니다. 이를 위해 Functions와 함께 빠른 저지연 접근이 가능한 라이브 모델 배포를 생성합니다.
라이브 모델링 배포 설정 지침을 검토하거나, Modeling 섹션의 자주 묻는 질문을 참조하십시오.
라이브 배포 API 이름에 설정한 값은 위에서 언급된 ModelApiName 대체 값과 동일합니다.
4. 모델의 Functions를 이용해 임베딩 생성하기
계속 진행하기 전에, "enableVectorProperties": true와 "useDeploymentApiNames": true 항목이 Functions Code Repositories의 functions.json 파일에 모두 있는지 확인합니다. 이 항목들이 없는 경우, functions.json에 추가하고 변경 사항을 커밋하여 진행합니다. 추가 도움이 필요한 경우 Palantir 담당자에게 문의하십시오.
마지막 단계는 이 오브젝트 유형을 쿼리하는 function을 생성하는 것입니다. 검색 단계의 전체 목표는 사용자 입력을 받아, 라이브 모델링 배포를 사용하여 벡터를 생성하고, 그런 다음 오브젝트 유형에 대해 KNN 검색을 수행하는 것입니다. 이 유즈케이스에 대한 샘플 function을 아래에 보여주며, 파일 구조도 함께 표시됩니다.
벡터 속성에 대한 수정은 액션과 Functions를 통해 적용할 수 있습니다.
자세한 정보는 모델의 Functions 문서에서 확인할 수 있습니다.
파일 구조
|-- functions-typescript
| |-- src
| | |-- tests
| | | |-- index.ts // 테스트 메인 파일
| | |-- index.ts // 메인 파일
| | |-- semanticSearch.ts // 의미론적 검색 함수
| | |-- service.ts // 서비스 관련 함수
| | |-- tsconfig.json // 타입스크립트 설정 파일
| | |-- types.ts // 타입 정의 파일
| |-- functions.json // 함수 설정 파일
| |-- jest.config.js // Jest 테스트 설정 파일
| |-- package-lock.json // 패키지 종속성 버전 파일
| |-- package.json // 패키지 설정 파일
|-- version.properties // 버전 속성 파일
functions-typescript/src/types.ts
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21import { Double } from "@foundry/functions-api"; // IEmbeddingModel 인터페이스 정의 // 내장(embed) 메서드를 가지고 있으며, 이는 문자열을 받아서 IEmbeddingResponse 타입의 프로미스를 반환한다. export interface IEmbeddingModel { embed: (content: string) => Promise<IEmbeddingResponse>; } // IEmbeddingResponse 인터페이스 정의 // 텍스트와 임베딩 배열, 그리고 선택적으로 추론 디바이스를 문자열로 가지고 있다. export interface IEmbeddingResponse { text: string embedding: Double[] inference_device?: string } // IEmbeddingRequest 인터페이스 정의 // 텍스트를 문자열로 가지고 있다. export interface IEmbeddingRequest { text: string }
functions-typescript/src/service.ts
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16import { ModelApiName } from "@foundry/models-api/deployments"; import { IEmbeddingRequest, IEmbeddingResponse } from "./types"; // 모델에 요청을 보내는 서비스 export class EmbeddingService { public async embed(content: string): Promise<IEmbeddingResponse> { // 요청을 만듭니다. const request: IEmbeddingRequest = { "text": content, }; // 요청을 보내고 응답을 반환합니다. return await ModelApiName.transform([request]) // 첫 번째 출력값을 가져옵니다. .then((output: any) => output[0]) as IEmbeddingResponse; } }
functions-typescript/src/semanticSearch.ts
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51import { Function, Integer, Double } from "@foundry/functions-api"; import { Objects, ObjectApiName } from "@foundry/ontology-api"; import { EmbeddingService } from "./service"; import { IEmbeddingResponse, IEmbeddingModel } from './types'; export class SuggestedDocs { embeddingService: IEmbeddingModel = new EmbeddingService; // 사용자 쿼리에 대한 추천 문서를 가져오는 함수 @Function() public async fetchSuggestedDocuments(userQuery: string, kValue: Integer, category: string): Promise<ObjectApiName[]> { const embedding: IEmbeddingResponse = await this.embeddingService.embed(userQuery); const vector: Double[] = embedding.embedding; return Objects.search() .objectApiName() .filter(obj => obj.category.exactMatch(category)) .nearestNeighbors(obj => obj.embedding.near(vector, {kValue: kValue})) .orderByRelevance() .take(kValue); } /** * 다음은 fetchSuggestedDocuments의 대안으로, 임계 유사성을 적용합니다. * 그렇지 않으면, kValue 개수의 문서가 얼마나 비슷한지에 관계없이 항상 반환됩니다. * 거리 함수의 계산은 임베딩 속성에 대해 정의된 거리 함수에 따라 다릅니다. * 여기서는 정규화된 벡터를 생성하는 임베딩 모델로 간단한 벡터 내적으로 계산할 수 있는 코사인 유사도라고 가정합니다. */ @Function() public async fetchSuggestedDocumentsWithThreshold(userQuery: string, kValue: Integer, category: string, thresholdSimilarity: Double): Promise<ObjectApiName[]> { const embedding: IEmbeddingResponse = await this.embeddingService.embed(userQuery); const vector: Double[] = embedding.embedding; return Objects.search() .objectApiName() .filter(obj => obj.category.exactMatch(category)) .nearestNeighbors(obj => obj.embedding.near(vector, {kValue: kValue})) .orderByRelevance() .take(kValue) .filter(obj => SuggestedDocs.dotProduct(vector, obj.embedding! as number[]) >= thresholdSimilarity); } // 두 벡터의 내적을 계산하는 함수 private static dotProduct<K extends number>(arr1: K[], arr2: K[]): number { if (arr1.length !== arr2.length) { throw EvalError("Two vectors must be of the same dimensions"); } return arr1.map((_, i) => arr1[i] * arr2[i]).reduce((m, n) => m + n); } }
functions-typescript/src/index.ts
Copied!1 2// "./semanticSearch"에서 SuggestedDocs를 export합니다. export { SuggestedDocs } from "./semanticSearch";
5. 함수 발행 및 예제에서 사용하기
이 시점에서는 자연어를 사용하여 오브젝트를 쿼리하는 시맨틱 검색을 실행할 수 있는 Function을 가지고 있습니다. 마지막 단계는 Function을 발행하고 워크플로에서 사용하는 것입니다. 문서 검색 예제를 계속 구축하기 위해, 이 Function을 호출하여 사용자에게 상위 두 개의 일치하는 문서를 반환하는 텍스트 입력을 사용하여 Workshop 애플리케이션을 생성하겠습니다.
예제에서 문서 서비스에 대한 시맨틱 검색을 생성하는 과정은 다음과 같습니다:
- Workshop 애플리케이션을 생성하는 것으로 시작합니다.
- 텍스트 입력과 스트링 셀렉터를 추가합니다. 스트링 셀렉터는 필터링 할 문서 카테고리를 선택하는 데 사용됩니다. 텍스트 입력과 스트링 셀렉터 모두 발행된 KNN 문서 가져오기 Function의 입력으로 사용됩니다.
- 마지막으로, Function과 선택한 입력에서 생성된 입력 오브젝트셋을 가진 오브젝트 리스트 위젯을 추가합니다. 아래에 표시된 것처럼:
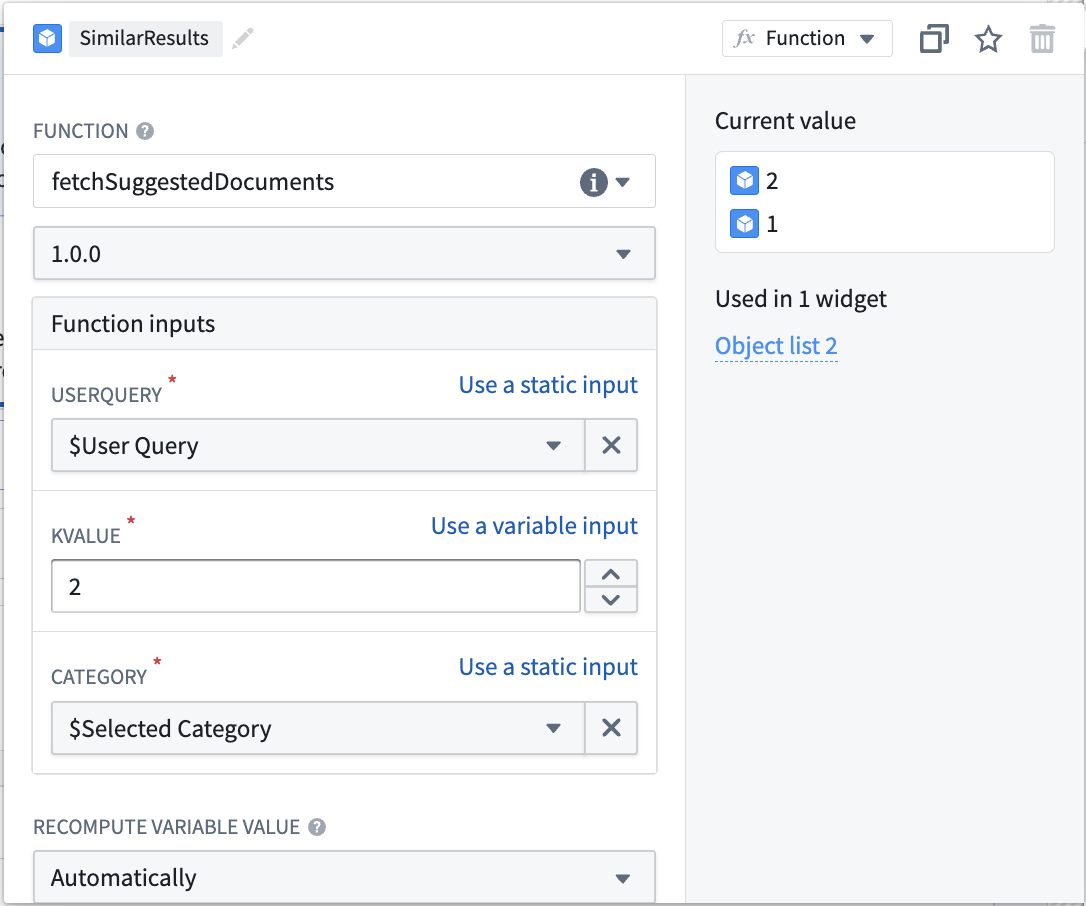
이 시점에서 입력값은 오브젝트 유형의 문서를 시맨틱 검색하고 가장 관련성이 높은 두 개를 반환하는 데 사용됩니다. 이것은 벡터 속성과 시맨틱 검색의 간단한 유즈케이스 중 하나입니다. 아래 스크린샷에서 결과 Workshop 애플리케이션의 예를 확인하세요: