성능 최적화
이 섹션에서는 사용자가 Functions와 함께 가장 흔히 경험하는 성능 문제를 설명하고, 병목 현상을 피하기 위해 코드를 최적화하는 방법을 문서화합니다.
Function 성능 개선을 위해 성능 탭 사용
성능 탭은 Functions의 성능 문제를 분석하고 파악하는 도구를 제공합니다. 이는 Function이 실행된 후 Functions 헬퍼에서 찾을 수 있습니다.
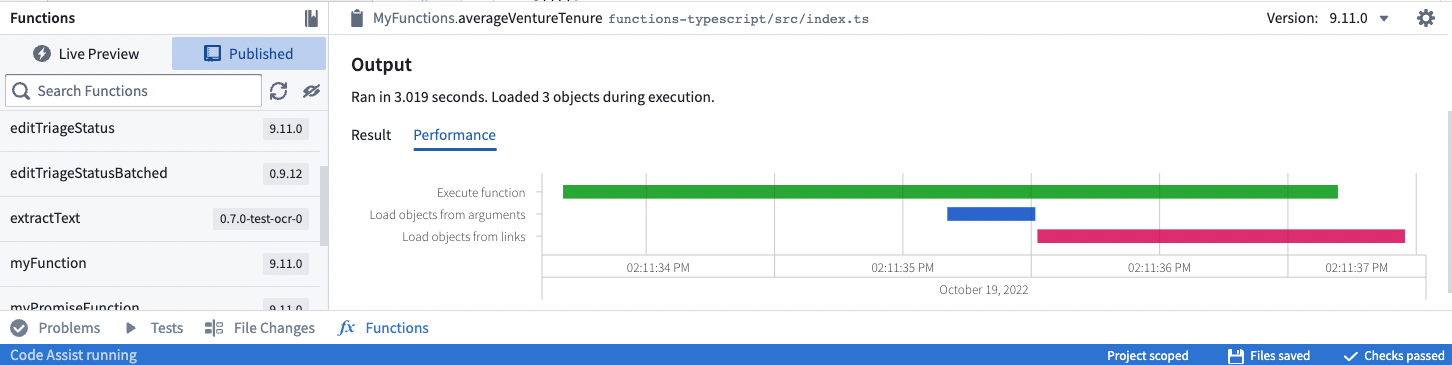
폭포수 그래프는 X축 시간에 걸쳐 가로 막대로 표시된 연산을 나타냅니다. 각 연산에는 시간이 어떻게 사용되는지 나타내는 마커가 있습니다.
- Function 실행은 Function 코드를 실행하는 데 소요된 CPU 시간을 나타냅니다.
- 인수에서 오브젝트 로드와 링크에서 오브젝트 로드는 기본 온톨로지 백엔드 데이터베이스 서비스(OSS)를 호출하는 데 소요된 시간을 나타냅니다.
성능을 개선하기 위해, 다음을 수행할 수 있습니다:
- Objects API를 사용하여 Typescript보다 더 빠르게 집계하고 링크를 순회합니다(아래 설명).
- 순차적인 로드를 피하기 위해 온톨로지 백엔드 서비스 호출을 병렬로 수행해야 합니다. 여러
async/await호출이 있는 경우,Promise.all을 사용하여 모든 호출을 병렬로await합니다.- 예를 들어, 일반적인 패턴은 목록의 각 오브젝트가
.map()을 사용하여 호출을 해당 Promise에 매핑하고, 결과 목록에서Promise.all을 사용하는 것입니다.
- 예를 들어, 일반적인 패턴은 목록의 각 오브젝트가
- 불필요한 중첩 루프를 피하면 실행 시간이 증가할 수 있습니다.
가능한 한 Objects API 사용 선호
Workshop의 파생 속성을 사용하는 일반적인 패러다임은 각 오브젝트의 링크를 집계하여 속성 값을 계산하는 것입니다(예: 관련 오브젝트의 수를 세는 등).
아래 코드는 작동하지만, Function 자체가 모든 연결된 오브젝트를 검색한 다음 집계를 수행해야 합니다(이 경우, 길이를 계산하는 것):
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16@Function() // 직원들의 프로젝트 수를 얻는 비동기 함수 public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> { // 각 직원의 작업 기록을 얻기 위해 비동기 함수를 실행하고 그 결과를 promises 배열에 저장 const promises = employees.map(employee => employee.workHistory.allAsync()); // 모든 직원의 작업 기록을 얻기 위해 Promise.all을 사용하여 대기 const allEmployeeProjects = await Promise.all(promises); // 직원과 프로젝트 수를 저장할 FunctionsMap 객체 생성 let functionsMap = new FunctionsMap(); // 각 직원에 대해 FunctionsMap에 직원과 그들의 프로젝트 수를 설정 for (let i = 0; i < employees.length; i++) { functionsMap.set(employees[i], allEmployeeProjects[i].length); } // 직원과 프로젝트 수가 저장된 FunctionsMap 객체 반환 return functionsMap; }
위의 내용은 비동기 API와 비동기 함수를 활용합니다(참조: 링크 순회 최적화), 그러나 종종 Objects API에 의해 제공되는 집계 방법을 사용하는 것이 유익합니다:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25@Function() public async getEmployeeProjectCount(employees: Employee[]): Promise<FunctionsMap<Employee, Integer>> { const result: FunctionsMap<Employee, Integer> = new FunctionsMap(); // employees 매개변수에서 일치하는 employeeId를 가진 모든 프로젝트 가져오기, 각 employeeId에 매핑된 프로젝트 개수 세기 const aggregation = await Objects.search().project() .filter(project => project.employeeId.exactMatch(...employees.map(employee => employee.id))) .groupBy(project => project.employeeId.byFixedWidths(1)) .count(); const map = new Map(); aggregation.buckets.forEach(bucket => { // 각 버킷 크기가 1이므로 bucket.key.min은 employeeId를 나타냅니다. map.set(bucket.key.min, bucket.value); }); employees.forEach(employee => { const value = map.get(employee.primaryKey); if (value === undefined) { return; } result.set(employee, value); }); return result; }
이렇게 하면 먼저 연결된 프로젝트를 모두 가져올 필요 없이 한 단계에서 집계를 수행할 수 있습니다.
집계의 일반적인 제한 사항이 여전히 적용된다는 점에 유의하세요. 특히, 문자열 ID에 대한 .topValues()는 상위 1000개 값만 반환합니다. 집계는 현재 최대 10K 버킷으로 제한되어 있으므로 원하는 결과를 검색하기 위해 여러 번의 집계를 수행해야 할 수도 있습니다. 자세한 내용은 집계 계산을 참조하세요.
링크 순회 최적화
Functions에서 성능 문제의 가장 일반적인 원인은 링크를 비효율적인 방식으로 순회하는 것입니다. 종종 이것은 많은 오브젝트를 순회하는 루프를 작성하고 루프의 각 반복에서 관련 오브젝트를 로드하는 API를 호출할 때 발생합니다.
Copied!1 2 3 4for (const employee of employees) { // 직원의 과거 프로젝트 조회 const pastProjects = employee.workHistory.all(); }
이 예에서 각 루프의 반복은 개별 직원의 과거 프로젝트를 로드하여 데이터베이스로의 왕복을 일으킵니다. 이런 지연을 피하기 위해, 많은 링크를 한 번에 순회할 때 비동기 링크 순회 API(getAsync() 및 allAsync())를 사용할 수 있습니다. 아래는 링크를 비동기로 로드하도록 작성된 Function의 예입니다:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23@Function() public async findEmployeeWithMostProjects(employees: Employee[]): Promise<Employee> { // 각 직원에 대한 프로젝트를 로드하는 Promise를 생성합니다 const promises = employees.map(employee => employee.workHistory.allAsync()); // 모든 약속을 전달하여 모든 링크를 병렬로 로드합니다 const allEmployeeProjects = await Promise.all(promises); // 결과를 순회하면서 가장 많은 프로젝트를 가진 직원을 찾습니다 let result; let maxProjectsLength; for (let i = 0; i < employees.length; i++) { const employee = employees[i]; const projects = allEmployeeProjects[i]; if (!result || projects.length > maxProjectsLength) { result = employee; maxProjectsLength = projects.length; } } return result; }
이 예제는 ES6 async function을 사용하여, .getAsync() 및 .allAsync() 메서드에서 반환되는 Promise 반환 값 처리가 편리하게 됩니다.