청킹
이 페이지에서는 시맨틱 검색 워크플로에 기본 청킹 전략을 통합하는 방법을 설명합니다. 이러한 맥락에서 청킹이란, 큰 텍스트를 더 작은 텍스트로 나누는 것을 의미합니다. 이는 임베딩 모델이 텍스트의 최대 입력 길이를 가지고 있기 때문에, 중요하게도 더 작은 텍스트 조각이 검색 중에 시맨틱적으로 더 독특하게 되기 때문에 유리합니다. 청킹은 종종 PDF와 같은 큰 문서를 분석할 때 사용됩니다.
주로, 목표는 긴 텍스트를 더 작은 "청크"로 나누고, 각각이 원래 오브젝트에 연결된 온톨로지 오브젝트와 관련이 있는 것입니다.
청킹 예제
시작점으로, Pipeline Builder에서 코드를 사용하지 않고 기본 청킹 전략이 어떻게 달성될 수 있는지 보여 드리겠습니다. 보다 고급 전략의 경우 파이프라인의 일부로 Code Repository를 사용하는 것이 좋습니다.
예시를 위해, 두 개의 열이 있는 두 행 데이터셋인 object_id와 object_text를 사용하겠습니다. 이해하기 쉽게하기 위해 아래의 object_text 예시는 고의적으로 짧게 만들어졌습니다.
| object_id | object_text |
|---|---|
| abc | gold ring lost |
| xyz | fast cars zoom |
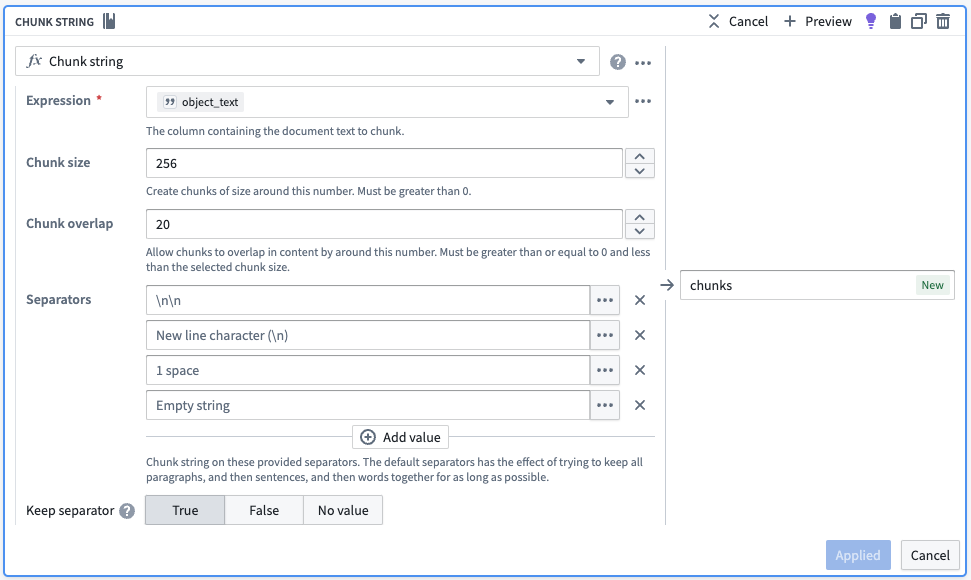
처음으로 Chunk String 보드를 사용하여 프로세스를 시작합니다. 이는 object_text가 더 작은 조각으로 분할된 배열이 포함된 추가 열을 도입합니다. 보드는 중복 및 구분자와 같은 다양한 청킹 접근 방식을 수용하여 각 시맨틱 개념이 일관되고 고유하게 유지됩니다.
아래 Chunk String 보드 스크린샷은 사용자의 유즈케이스에 맞게 변경하여 사용할 수 있는 간단한 전략을 보여줍니다. 아래 구성은 대략 256자 크기의 청크를 반환하려고 시도합니다. 기본적으로, 보드는 각 청크가 청크 크기보다 작거나 같을 때까지 텍스트를 최우선 구분자로 분할합니다. 더 이상 최우선 구분자가 없고 일부 청크는 여전히 너무 큰 경우 다음 구분자로 이동하여 청크 크기보다 작거나 같거나 더 이상 사용할 구분자가 없을 때까지 청크 크기보다 작거나 같습니다. 마지막으로, 보드는 각 청크가 이전 청크의 마지막 20자를 포함하는 겹침을 가진 청크를 확인합니다.
| object_id | object_text | chunks |
|---|---|---|
| abc | gold ring lost | [gold,ring,lost] |
| xyz | fast cars zoom | [fast,cars,zoom] |
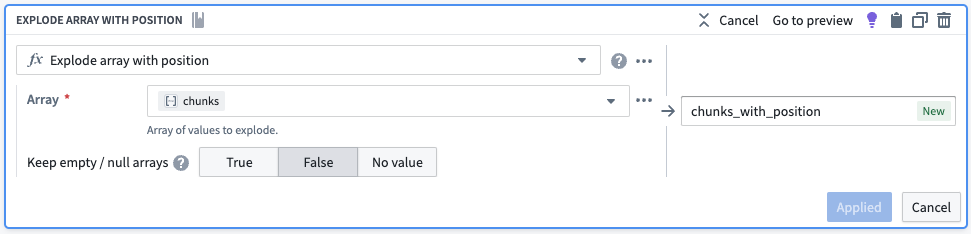
다음으로 배열의 각 요소가 자체 행을 갖도록 하고 싶습니다. Explode Array with Position 보드를 사용하여 데이터셋을 여섯 개의 행이 있는 것으로 변환하겠습니다. 새 열의 각 행(아래에서 볼 수 있음)은 배열의 위치와 배열의 요소 두 가지 키-값 쌍이 있는 구조체(맵)입니다.
| object_id | object_text | chunks | chunks_with_position |
|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} |
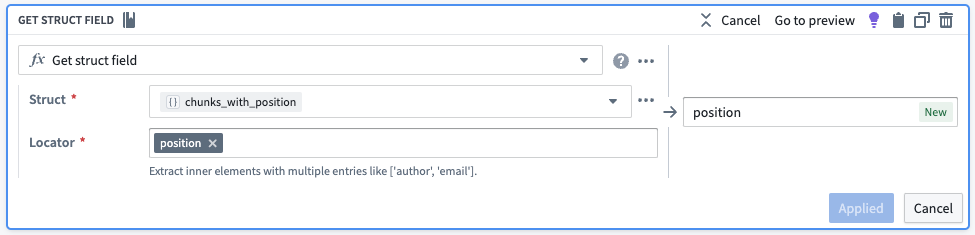
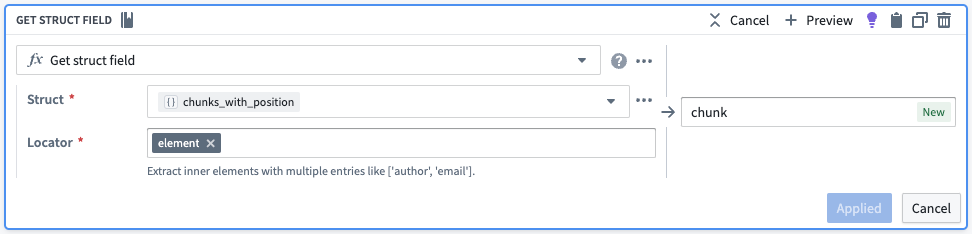
거기에서, 위치와 요소를 각각 자체 열로 추출하겠습니다.
| object_id | object_text | chunks | chunks_with_position | position | chunk |
|---|---|---|---|---|---|
| abc | gold ring lost | [gold,ring,lost] | {position:0, element} | 0 | gold |
| abc | gold ring lost | [gold,ring,lost] | {position:1, element} | 1 | ring |
| abc | gold ring lost | [gold,ring,lost] | {position:2, element} | 2 | lost |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:0, element} | 0 | fast |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:1, element} | 1 | cars |
| xyz | fast cars zoom | [fast,cars,zoom] | {position:2, element} | 2 | zoom |
각 청크에 대해 고유한 식별자를 생성하기 위해 청크의 배열 위치를 문자열로 변환한 다음 원래 오브젝트 ID에 연결하겠습니다. 또한 불필요한 열을 삭제하겠습니다.
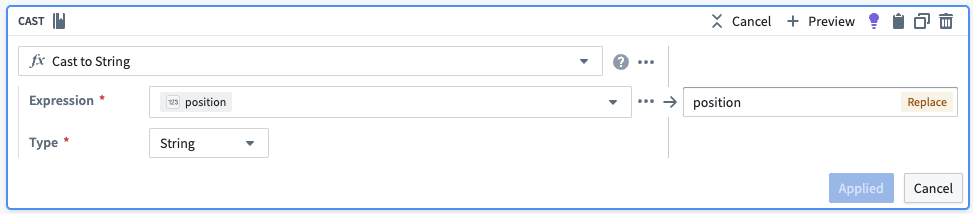
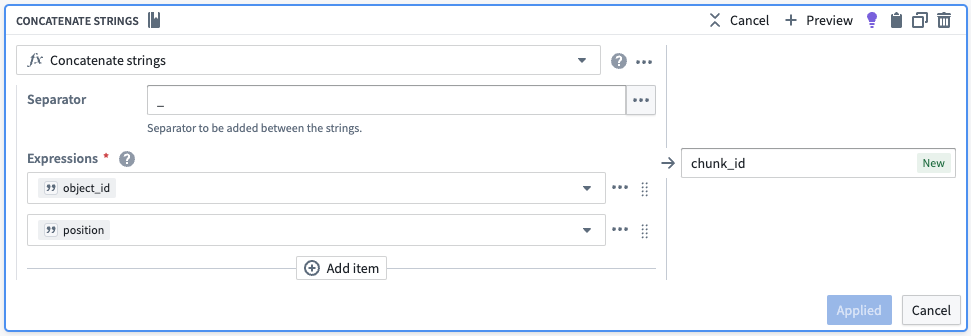

| object_id | chunk | chunk_id |
|---|---|---|
| abc | gold | abc_0 |
| abc | ring | abc_1 |
| abc | lost | abc_2 |
| xyz | fast | xyz_0 |
| xyz | cars | xyz_1 |
| xyz | zoom | xyz_2 |
이제 여섯 개의 행이 여섯 개의 다른 청크를 나타내고, object_id(링크용), 새로운 chunk_id가 새로운 기본 키가 되고, chunk가 시맨틱 검색 워크플로에서 설명한대로 임베디드됩니다. 결과적으로 다음과 같은 테이블이 생성됩니다.
| object_id | chunk | chunk_id | embedding |
|---|---|---|---|
| abc | gold | abc_0 | [-0.7,...,0.4] |
| abc | ring | abc_1 | [0.6,...,-0.2] |
| abc | lost | abc_2 | [-0.8,...,0.9] |
| xyz | fast | xyz_0 | [0.3,...,-0.5] |
| xyz | cars | xyz_1 | [-0.1,...,0.8] |
| xyz | zoom | xyz_2 | [0.2,...,-0.3] |