Code Repositories에서의 데이터셋 모델
아래 문서는 foundry_ml 라이브러리를 설명하고 있으나, 이 라이브러리는 더 이상 플랫폼에서 사용을 권장하지 않습니다. 대신 palantir_models 라이브러리를 사용하세요.
foundry_ml 라이브러리는 2025년 10월 31일에 제거될 예정으로, Python 3.9의 예정된 폐기와 일치합니다.
데이터셋 모델은 Code Workbook과 Code Repositories에서 생성할 수 있습니다. Code Workbook은 더욱 상호 작용적이며 고급 플로팅 기능을 제공하는 반면, Code Repositories는 전체 Git 기능, PR 워크플로, 메타 프로그래밍을 지원합니다.
이 워크플로는 Code Repositories와 Python 변환에 대한 이해를 가정하고 있습니다.
Code Repositories에서 모델 작성
설정
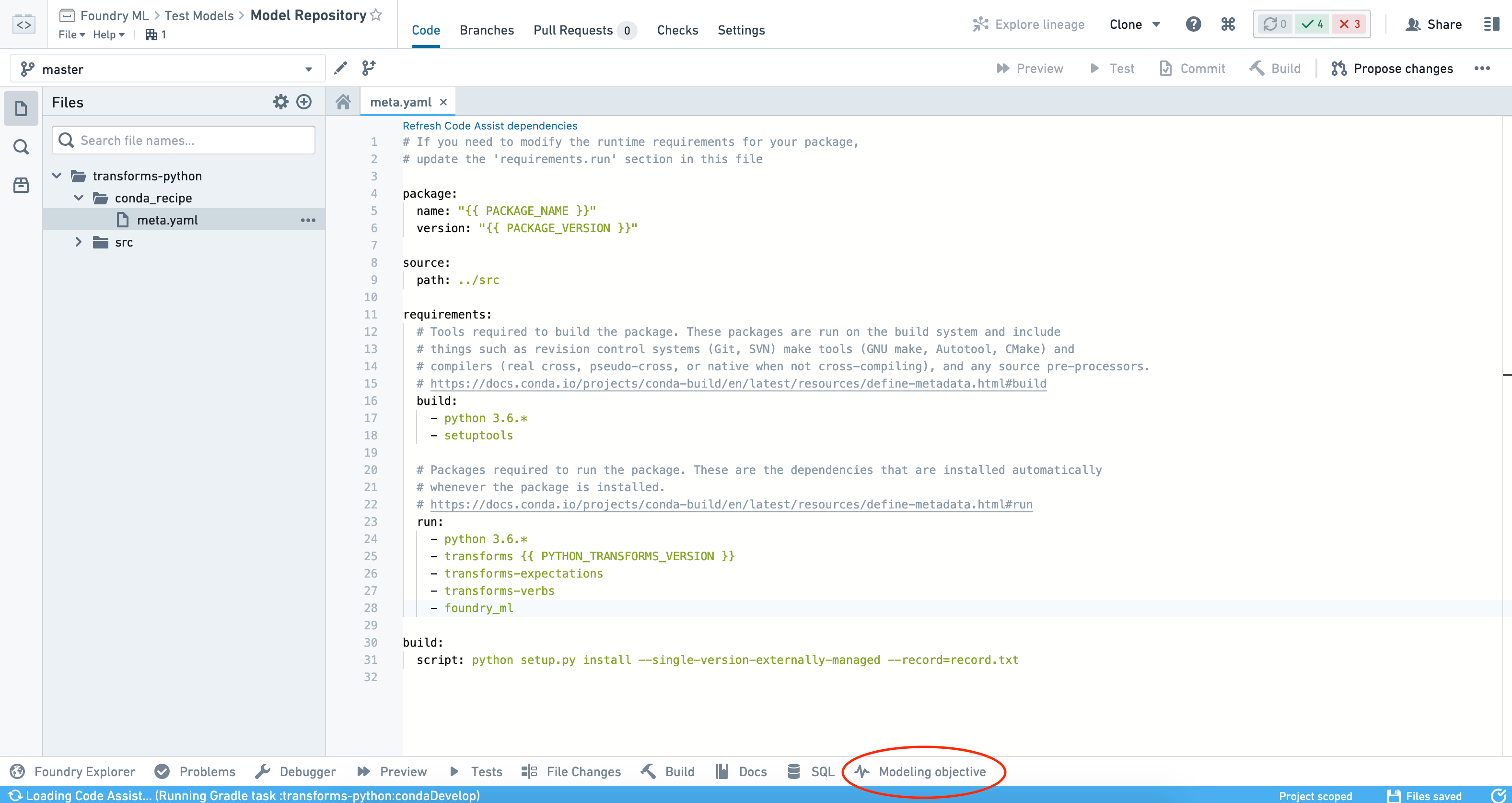
새로운 리포지토리를 만들었거나 (또는 기존의 것을 열었다면), foundry_ml과 scikit-learn이 conda 환경에서 사용 가능한지 확인하세요. meta.yaml 파일을 검사함으로써 결과를 확인할 수 있습니다. 아래의 코드를 실행하기 위해, 필요한 meta.yaml 파일의 예시는 다음과 같습니다:
![]()
로지스틱 회귀 모델 생성
transform 데코레이터를 사용하여 model.save(transform_output) 인스턴스 메소드를 통해 모델을 저장합니다.
참고: 아래에 표시된 코드에서는 여러 Stage 오브젝트가 생성되고 단일 변환 내에서 단일 Model로 결합됩니다. 이는 Getting Started 튜토리얼의 Code Workbook 기반에서 별도로 저장된 단계와는 다릅니다. 어느 방식이든 동작합니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36from sklearn.compose import make_column_transformer from sklearn.linear_model import LogisticRegression from transforms.api import transform, Input, Output from foundry_ml import Model, Stage from foundry_ml_sklearn.utils import extract_matrix @transform( iris=Input("/path/to/input/iris_dataset"), out_model=Output("/path/to/output/model"), ) def create_model(iris, out_model): df = iris.dataframe().toPandas() column_transformer = make_column_transformer( ('passthrough', ['sepal_width', 'sepal_length', 'petal_width', 'petal_length']) ) # 데이터 프레임의 열을 변환하여 벡터화 역할을 하는 column_transformer를 학습시킵니다. column_transformer.fit(df[['sepal_width', 'sepal_length', 'petal_width', 'petal_length']]) # 벡터화를 적용할 변환을 나타내는 Stage로 vectorizer를 감싸십시오. vectorizer = Stage(column_transformer) # 벡터화를 적용하여 원래의 모든 열과 벡터화된 데이터의 열이 있는 데이터 프레임을 생성합니다. 기본적으로 "features"라는 이름입니다. training_df = vectorizer.transform(df) # 벡터 열을 NumPy 행렬로 변환하고 희소성을 처리하는 데 도움이 되는 함수가 있습니다. X = extract_matrix(training_df, 'features') y = training_df['is_setosa'] # 로지스틱 회귀 모델을 학습시킵니다 - 향후 경고를 방지하기 위해 solver를 지정합니다. clf = LogisticRegression(solver='lbfgs') clf.fit(X, y) # 변환의 파이프라인이 포함된 Model 객체를 반환합니다. model = Model(vectorizer, Stage(clf, input_column_name='features')) # Model을 저장하는 구문입니다. model.save(out_model)
모델 불러오고 사용하기
transform 데코레이터를 사용하여 Model 클래스의 Model.load(transform_input) 클래스-메소드로 모델을 불러옵니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15@transform( in_model=Input("/path/to/output/model"), # 모델 저장 위치를 입력으로 받습니다. test_data=Input("/path/to/data"), # 테스트 데이터 위치를 입력으로 받습니다. out_data=Output("/path/to/output/data/from/applying/model"), # 결과를 저장할 위치를 출력으로 받습니다. ) def apply_model(in_model, test_data, out_data): # 위에서 저장한 모델을 로드합니다. model = Model.load(in_model) # 테스트 데이터셋에 모델을 적용합니다. pandas_df = test_data.dataframe().toPandas() output_df = model.transform(pandas_df) # 변환의 결과는 numpy 배열을 포함한 컬럼을 가지고 있으므로, 이를 저장하기 전에 형변환을 합니다. output_df['features'] = output_df['features'].apply(lambda x: x.tolist()) # 모델을 적용한 결과를 작성합니다. out_data.write_pandas(output_df)
MetricSets 저장 및 로드
MetricSets은 Model과 동일한 구문을 사용하여 저장 및 로드됩니다. 즉, metric_set.save(transform_output) 및 MetricSet.load(transform_input)을 사용합니다.
Model을 생성하는 동일한 변환에서 MetricSets를 생성할 수 있으며(예: 훈련 시간 동안 보류 중인 지표), Model을 로드하고 실행하는 하위 변환에서 생성할 수도 있습니다.
모델 자동 제출
이 기능은 현재 활발하게 개발 중인 실험적인 기능입니다. 사용자 인터페이스는 다가오는 버전에서 변경될 수 있습니다.
Code Repositories에서는 빌드 시 Modelling Objective에 자동으로 제출되도록 모델을 설정할 수 있습니다. 이렇게 설정하면 Modelling Objective가 모델을 구독하고 해당 모델에 트랜잭션이 성공적으로 커밋될 때마다 새로운 제출을 생성합니다.
사전 요구 사항
이 기능을 사용하려면 먼저 다음을 수행해야 합니다.
- Transforms 파이썬 Code Repositories를 생성합니다. 저장소 설정에 대한 정보는 Python transforms tutorial을 참조하세요.
meta.yaml파일에foundry_ml패키지를 런타임 종속성으로 추가하고 변경 사항을 커밋합니다. 커밋 후 인터페이스 하단의 다른 패널 옆에 Modeling objective 도움말 패널이 표시됩니다(아래 스크린샷 참조).
- 위에서 설명한대로 모델 데이터셋을 출력하는 변환을 작성합니다.
- 데이터셋을 최소한 한 번 빌드합니다. 이렇게 하면 도움말 패널에서 저장소의 모델을 감지하고 자동 제출을 설정할 수 있습니다.
자동 제출 설정
자동 제출은 각 모델 개별로 설정할 수 있으며, 한 번에 하나의 모델을 선택하여 설정할 수 있습니다. 여러 모델이 선택된 경우 모델이 제출되는 목표 목록을 볼 수 있지만 일괄로 자동 제출을 설정할 수는 없습니다.
모델에 대해 자동 제출을 설정하려면 인터페이스 왼쪽의 Models 패널에서 모델을 선택하고 Select modeling objective 버튼을 클릭한 다음 모델이 제출할 목표를 선택합니다.
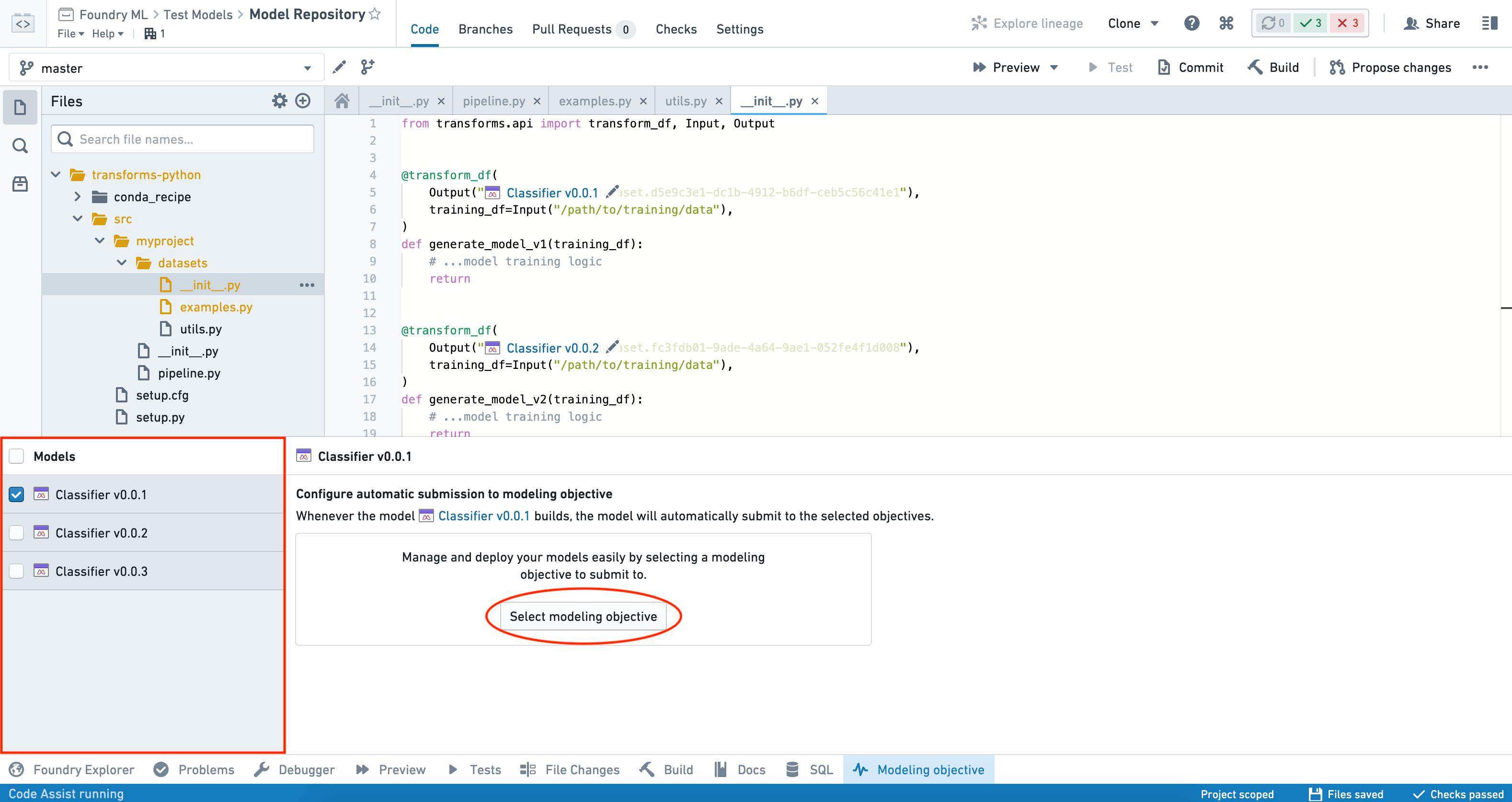
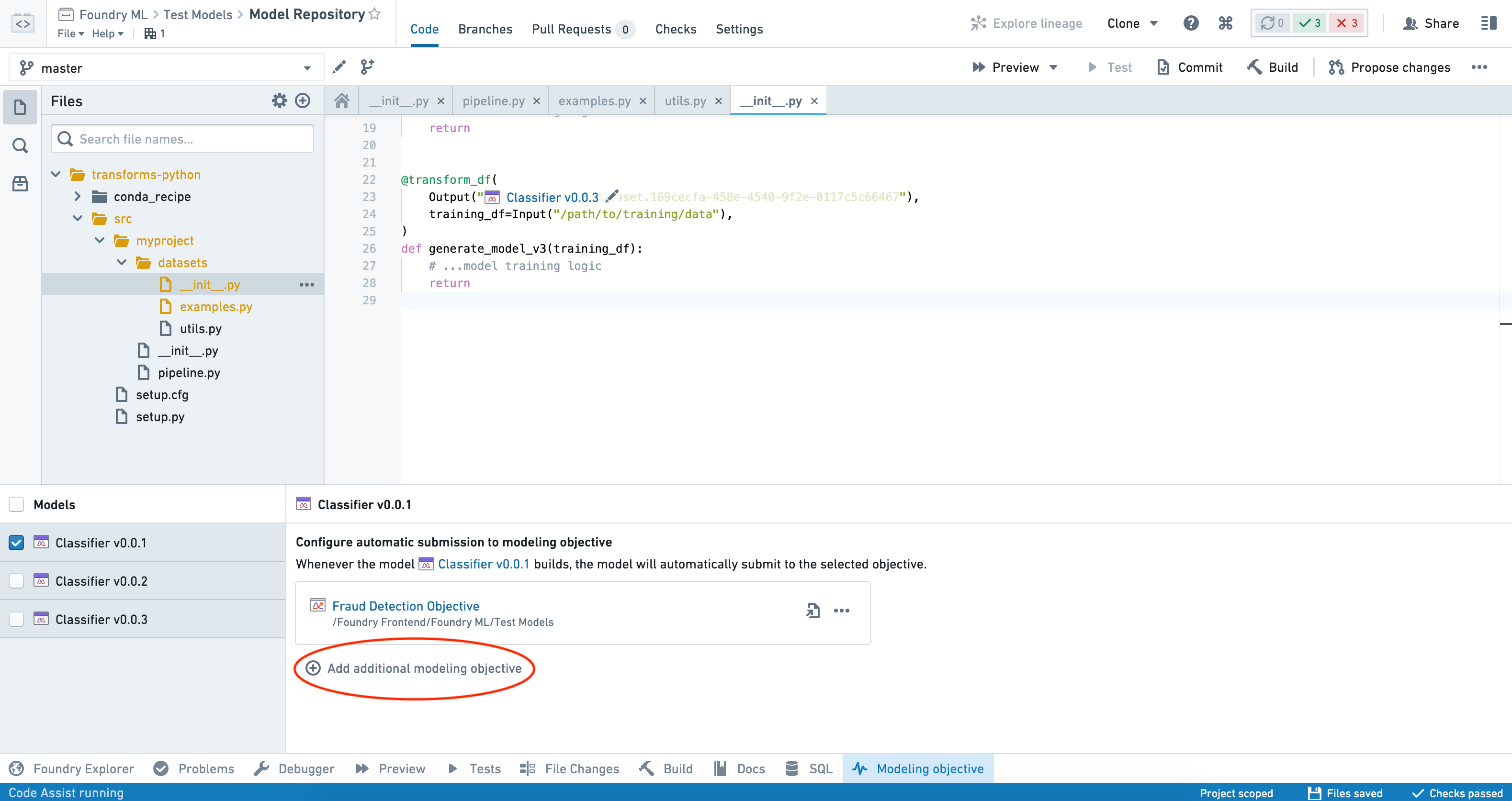
이제 모델이 빌드되면 해당 목표로 자동 제출됩니다. 추가 목표를 제출할 수 있도록 설정하려면 Add additional modeling objective를 클릭하고 이러한 단계를 반복합니다.
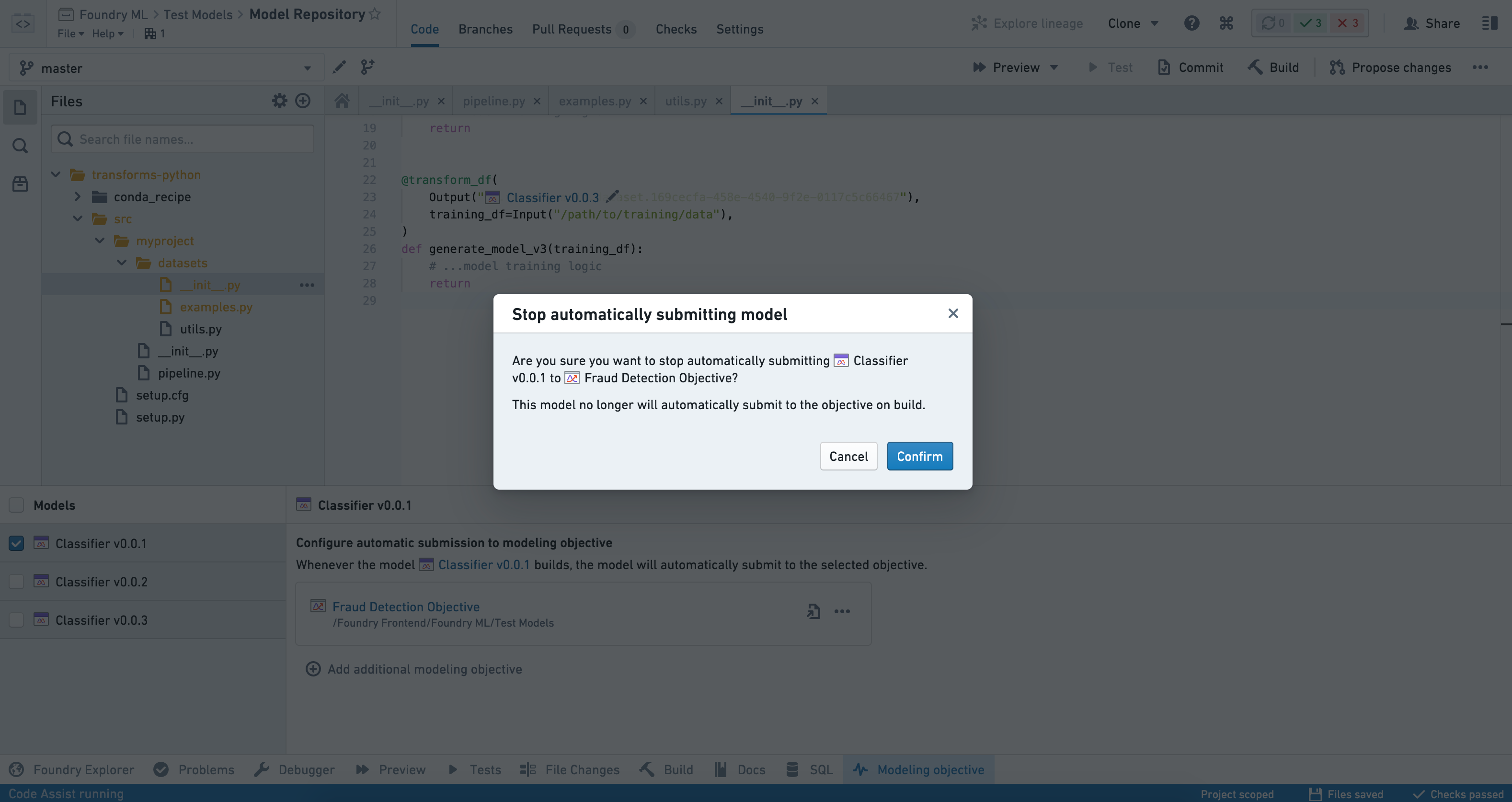
자동 제출 비활성화
특정 모델의 목표로의 제출을 중지하려면 인터페이스 왼쪽의 Models 패널에서 모델을 선택하고 제거할 목표 옆에 있는 세 개의 점(...)을 클릭합니다.
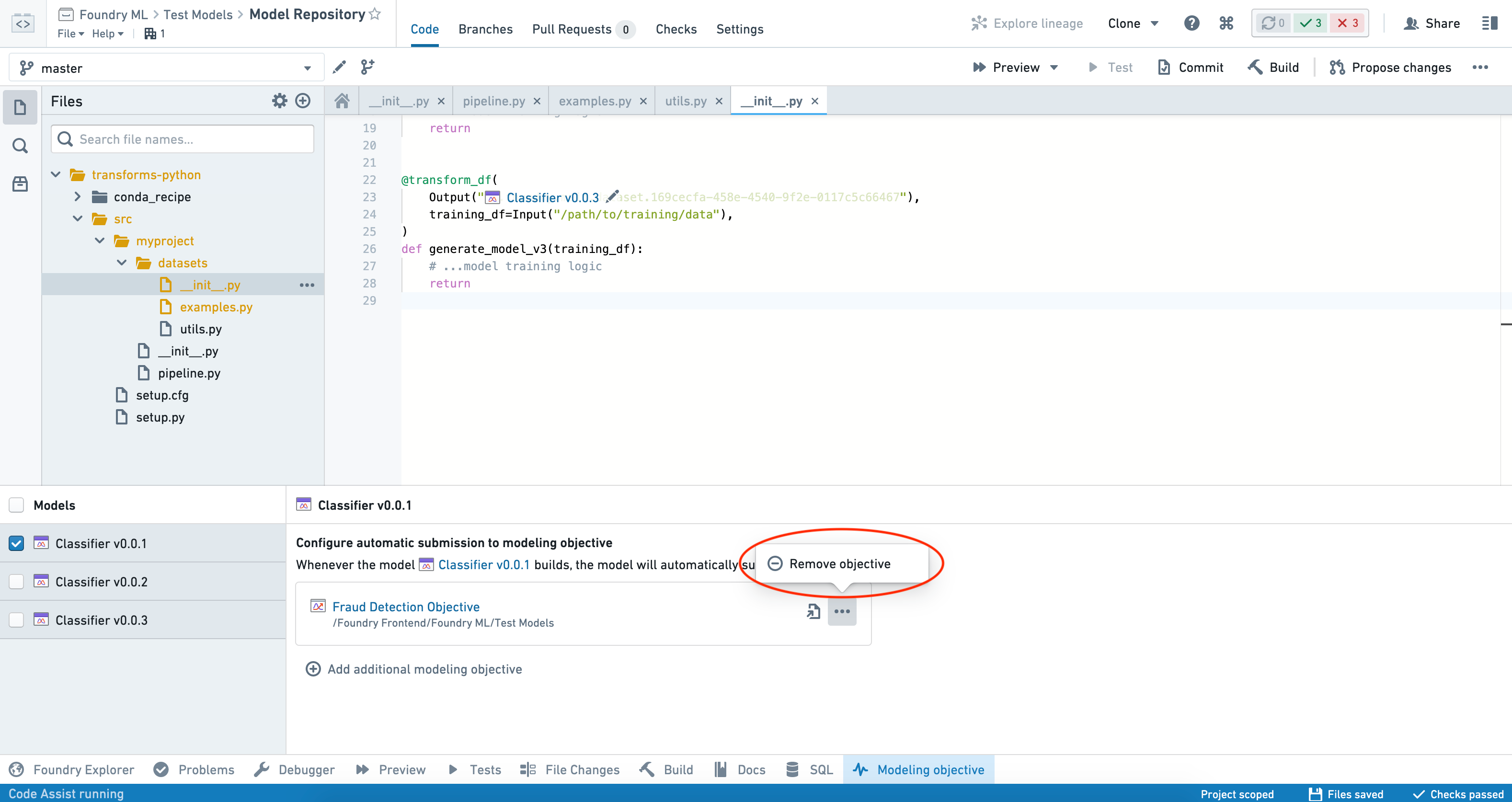
Remove objective를 선택하고 결정 사항을 확인합니다.
기준 기반 자동 제출
설정된 경우 모델은 해당 모델에 트랜잭션이 성공적으로 커밋될 때마다 자동으로 제출됩니다. 그러나 모든 재교육 후에 모델을 다시 제출하는 것이 항상 원하는 것이 아니기 때문에 원하는 기준에 따라 모델 재교육 및 자동 제출을 중단할 수 있습니다.
예를 들어, 훈련 시간 동안 이전 제출보다 낮은 보류 중인 지표를 가진 모델에 대한 자동 제출을 중단하려면 모델 재교육 변환에서 다음 단계를 수행합니다.
- 위에서 설명한대로 모델을 다시 교육하고 새로운 보류 중인 지표를 생성합니다.
- Foundry의 incremental transform behavior를 사용하여 이전 보류 중인 지표를 읽습니다.
- 새로운 보류 중인 지표를 이전 보류 중인 지표와 비교합니다.
- 새로운 보류 중인 지표가 이전 지표보다 선호되는 경우
model.save(transform_output)를 사용하여 모델을 저장합니다. - 새로운 보류 중인 지표가 이전 지표보다 나쁜 경우 모델 훈련 변환을 중단합니다. 이렇게 하면 모델 자동 제출이 중단됩니다.
- 새로운 보류 중인 지표가 이전 지표보다 선호되는 경우
위 단계는 모델 재교육 중 많은 실시간 검사를 수행하는 데 쉽게 재사용할 수 있습니다.
자동 재교육 설정
자동 제출과 빌드 일정을 결합하면 체계적인 모델 재교육을 설정할 수 있습니다.
모델에 자동 제출을 설정한 후 동일한 모델에 일정을 추가합니다. 필요한 경우 상위 데이터셋을 포함할 수도 있습니다. 예를 들어:
- 모델을 생성하는 변환에 별도로 교육된 단계가 포함되어 있는 경우 일정에 이를 포함할 수 있습니다.
- 경우에 따라 훈련 데이터셋을 일정의 일부로 포함하는 것이 적절할 수 있습니다.
이제 일정 내에서 시간 및 이벤트 기반 트리거 조합을 설정할 수 있습니다.
일반적인 구성은 다음과 같습니다.
- 순수 시간 기반 트리거(예: 24시간마다 재교육).
- 순수 이벤트 기반 트리거(예: 훈련 세트가 업데이트될 때마다 재교육).
- 위의
AND또는OR조합을 사용한 고급 구성.
고급 재교육 트리거
고급 재교육 트리거를 진행하기 전에 incremental transforms에 익숙해지는 것이 좋습니다.
일부 경우에는 계산 비용이 많이 드는 훈련 작업과 같이 다른 데이터셋을 기반으로 모델 빌드 일정을 트리거하여 모델을 선택적으로 재교육할 수 있습니다. 이를 통해 기능 이동, 점수 이동, 관찰된 모델 저하, 사용자 피드백 또는 기타 지표에 기초하여 재교육을 트리거할 수 있습니다.
이 작업을 수행하려면 "알림" 데이터셋을 생성하고 일정을 설정하는 것이 좋습니다. 이를 위해 사용 사례에 적합한 여러 요소를 조합할 수 있습니다.
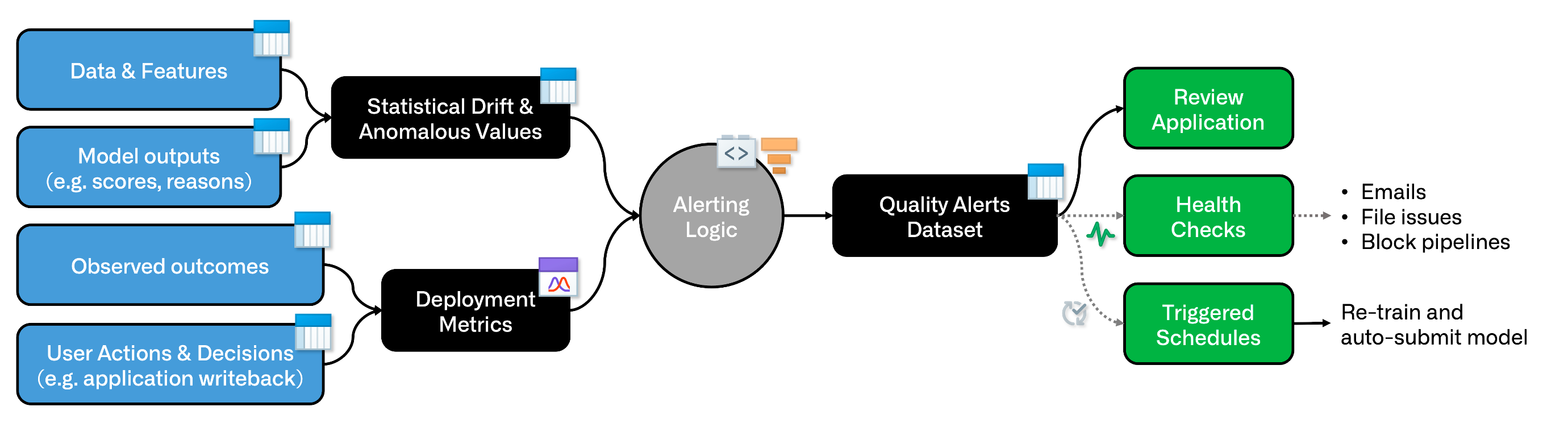
로직을 인코딩하는 데 코드 기반 또는 저/무 코드 도구(Contour 등)를 사용할 수 있습니다.
알림 로직 하류에서 Code Repositories 내의 Python 변환을 사용하여 추가 전용 증분 "알림" 데이터셋을 생성합니다. 변환 로직에서 새로운 알림이 없을 때마다 트랜잭션을 중단합니다.
이제 모델 재교육 일정을 "Transaction committed" 이벤트 트리거로 설정할 수 있습니다.
알림 데이터셋에 건강 검사를 설정할 수도 있으며, 사용자 지정 검토 애플리케이션에서 사용할 수 있습니다.