JDBC 동기화 최적화
이 가이드는 JDBC 동기화의 속도와 신뢰성을 향상시키기 위한 팁을 제공합니다.
만약 동기화가 이미 안정적으로 작동하고 있다면, 아래에 설명된 액션을 취할 필요가 없습니다. 새로운 동기화를 설정하거나 동기화가 너무 오래 걸리거나 신뢰성있게 완료되지 않는 경우, 이 가이드를 따르는 것을 권장합니다.
JDBC 동기화를 가속화하기 위한 두 가지 주요 방법이 있습니다. 우리는 동기화를 점진적으로 만들기 시작하고, 점진적 동기화가 충분하지 않은 경우에만 SQL 쿼리를 병렬화하는 것을 추천합니다:
점진적 동기화
기본적으로, 배치 동기화는 대상 표의 모든 일치하는 행을 동기화할 것입니다. 반면에, 점진적 동기화는 가장 최근의 동기화에 대한 상태를 유지하므로 대상에서 새로운 일치하는 행만을 가져오는 데 사용할 수 있습니다. 이는 행 수가 많은 표에 대한 동기화 성능을 대폭 향상시킬 수 있습니다. 점진적 동기화는 동기화된 데이터셋에 데이터를 APPEND 트랜잭션으로 추가함으로써 작동합니다.
아래는 점진적 배치 동기화의 예제 설정입니다:
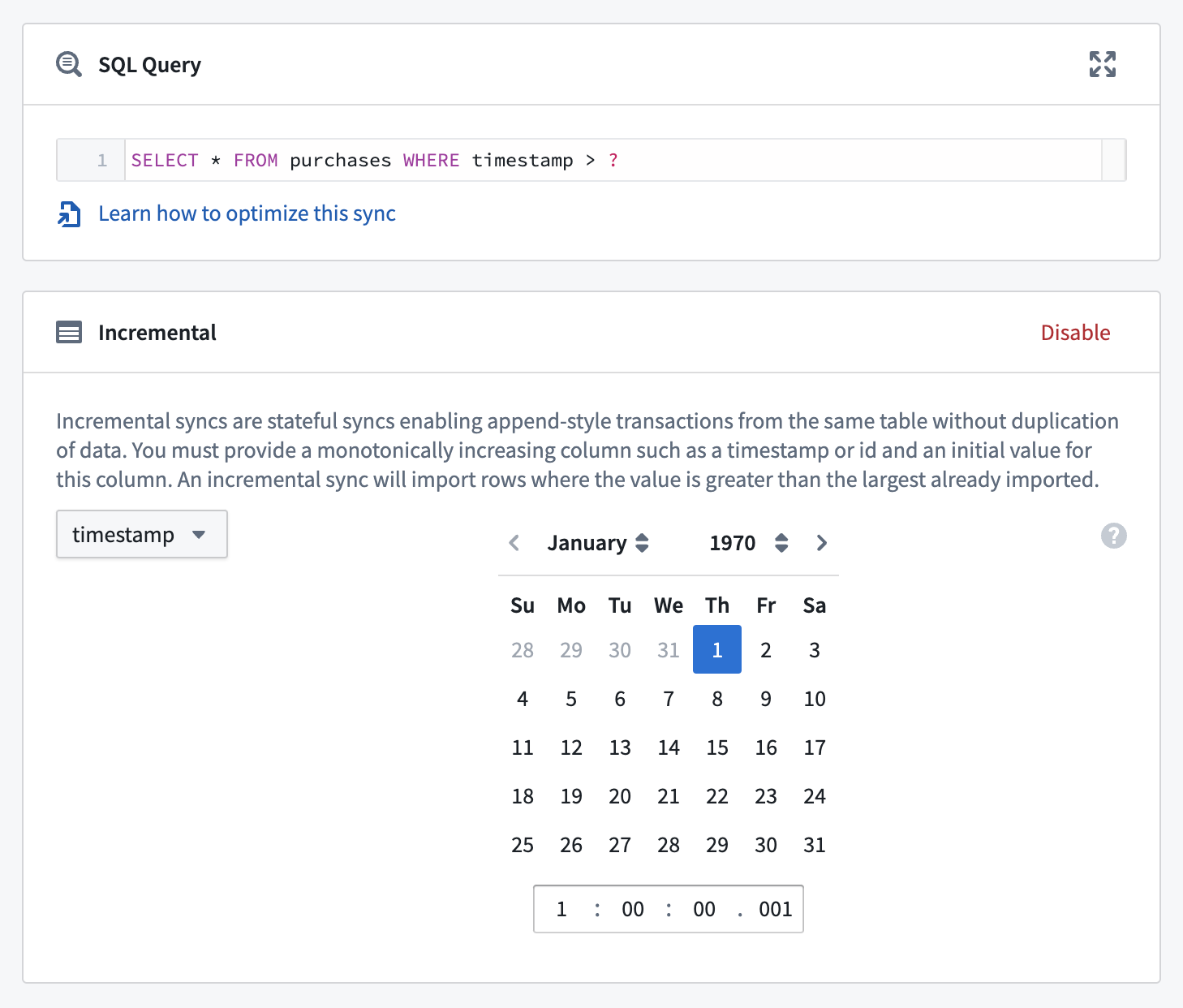
다음 단계를 수행하여 점진적 배치 동기화를 설정하세요:
-
변환하려는 동기화에 대한 설정 페이지로 이동하고, 미리보기가 작동하고 있는지 확인합니다.
-
트랜잭션 유형을
APPEND로 설정합니다. 이는 이전 동기화에서의 행을 덮어쓰는 것을 피하기 위해 필요합니다. -
Incremental 상자에서 Enable을 선택합니다. 미리보기가 이 동기화에서 성공적으로 실행되었는지 확인합니다. 작동하는 미리보기가 있는 경우, Incremental 상자는 동기화에 대한 초기 점진적 상태를 설정할 수 있게 확장될 것입니다.
-
동기화의 점진적 상태를 설정합니다. 이 상태는 incremental column 및 initial value로 구성되며, 사용자 인터페이스에서 설정할 수 있습니다. 이러한 값들을 설정할 때 다음 중요한 고려사항들을 염두에 두세요:
- incremental column은 동기화 사이에서 _엄격하게 증가_해야 합니다. 만약 행이 불변하다면 (즉, 기존 행을 그 자리에서 업데이트할 수 없다면), 일관되게 증가하는 열 (예: 자동 증가 ID 또는 행이 추가될 때의 타임스탬프)이면 충분합니다. 만약 행이 가변하다면 (즉, 표가 기존 행을 업데이트하는 것을 허용하고, 새로운 행을 삽입하는 것만 허용하지 않는다면), 데이터의 모든 변이와 함께 증가하는 열이 필요합니다 (예:
update_time열). - 행을 한 번 이상 가져오지 않기 위해, incremental column의 initial value는 이전 실행에서 동기화된 _모든 행들_보다 커야 합니다. 예를 들어, 가장 최근의
SNAPSHOT동기화가 정수id열의 값이1999까지 범위의 행을 가져왔다면, initial value를2000으로 설정할 수 있습니다.
- incremental column은 동기화 사이에서 _엄격하게 증가_해야 합니다. 만약 행이 불변하다면 (즉, 기존 행을 그 자리에서 업데이트할 수 없다면), 일관되게 증가하는 열 (예: 자동 증가 ID 또는 행이 추가될 때의 타임스탬프)이면 충분합니다. 만약 행이 가변하다면 (즉, 표가 기존 행을 업데이트하는 것을 허용하고, 새로운 행을 삽입하는 것만 허용하지 않는다면), 데이터의 모든 변이와 함께 증가하는 열이 필요합니다 (예:
기존 행의 업데이트 버전을 가져올 때, Foundry 데이터셋은 여전히 행의 이전 버전을 포함하게 될 것입니다 (기억하세요, 우리는 APPEND 트랜잭션 유형을 사용하고 있습니다). 만약 각 행의 최신 버전만 원한다면, Foundry의 다른 도구, 예를 들어 Transforms,를 사용하여 데이터를 정리해야 할 것입니다. 더 알아보려면 incremental pipelines에 대한 지침을 참조하세요.
- 마지막으로, 와일드카드 심볼
?를 사용하여 쿼리를 업데이트합니다. 와일드카드를 쿼리에 어떻게 포함하는지는 쿼리 로직에 따라 다릅니다. 아래의 간단한 예제를 참조하고, 다음 사항을 주의하세요:- 첫 번째 점진적 실행에서, 이 와일드카드는 이전 단계에서 지정한 initial value로 대체될 것입니다.
- 그 후의 어떤 실행에서도, 와일드카드는 이전 실행에서 incremental column의 최대 동기화 값으로 대체될 것입니다.
위에서 언급한 바와 같이, 점진적 상태 인터페이스는 동기화의 미리보기가 성공적으로 실행된 경우에만 작동합니다. 이는 새로운 점진적 동기화를 처음부터 생성하거나 기존의 점진적 동기화를 복제하는 경우, 쿼리에 와일드카드 ? 연산자가 없는 상태로 미리보기를 실행해야 한다는 것을 의미합니다.
예제
테이블 employees를 가져온다고 가정해 봅시다. 이 테이블은 트랜잭션 유형이 SNAPSHOT으로 설정되어 있고, 다음과 같은 간단한 SQL 쿼리가 있습니다:
Copied!1 2 3 4SELECT * -- 모든 열을 선택합니다. FROM employees -- "employees" 테이블에서 데이터를 가져옵니다.
시간 T1에 표는 다음과 같습니다:
| id | name | surname | update_time | insert_time |
|---|---|---|---|---|
1 | Jane | Smith | 1478862205 | 1478862205 |
2 | Erika | Mustermann | 1478862246 | 1478862246 |
그리고 이 표가 변경 가능하다고 가정하여 나중 시간인 T2에 다음과 같이 보입니다:
| id | name | surname | update_time | insert_time |
|---|---|---|---|---|
1 | Jane | Doe | 1478862452 | 1478862205 |
2 | Erika | Mustermann | 1478862246 | 1478862246 |
3 | Juan | Perez | 1478862438 | 1478862438 |
이 동기화를 점진적으로 변경하려고 하므로 트랜잭션 유형을 APPEND로 업데이트합니다.
점진적 열로 무엇을 사용해야 할까요? id 또는 insert_time 열은 점진적 열로 적절하지 않다는 점을 주목해야 합니다. 왜냐하면 이 열들은 Jane 행의 surname 열 변경과 같은 업데이트를 놓칠 수 있기 때문입니다. 대신 update_time을 점진적 열로 사용해야 합니다.
초기 값으로 선택하는 것은 이 표에서 이미 행을 동기화했는지 여부에 따라 다릅니다. 시간 T1에 SNAPSHOT 동기화를 실행하고 update_time 값이 1478862246까지의 행을 이미 동기화한 경우, 중복을 피하기 위해 초기 값으로 1478862247을 사용해야 합니다. 이 표에서 행을 동기화하지 않은 경우 초기 값으로 0(또는 날짜를 설정할 경우 01/01/1970)을 사용할 수 있습니다.
마지막으로 SQL 쿼리를 변경합니다.
Copied!1 2 3 4 5 6SELECT * -- 모든 열을 선택합니다. FROM employees -- employees 테이블에서 데이터를 가져옵니다. WHERE update_time > ? -- update_time이 ?보다 큰 데이터만 필터링합니다.
변환 완료되었습니다. 앞서 언급한 바와 같이 동기화를 점진적으로 실행한 후 데이터 세트에 여러 개의 Jane 행이 있게 됩니다(각 업데이트에 대해 하나씩). Contour 또는 Transforms와 같은 하류 로직에서 이 중복을 처리해야 합니다.
점진적인 JDBC 동기화 문제가 발생한 경우, 문제 해결 가이드의 이 섹션이 도움이 될 수 있습니다.
SQL 쿼리 병렬화
병렬 기능은 대상 데이터베이스에 대해 별도의 쿼리를 실행하므로, 약간 다르게 타이밍이 설정된 쿼리에 의해 다르게 처리되는 실시간 업데이트 테이블의 경우를 주의 깊게 고려해야 합니다.
병렬 기능을 사용하면 에이전트가 병렬로 실행할 여러 개의 작은 쿼리로 SQL 쿼리를 쉽게 분할할 수 있습니다.
이러한 동작을 달성하려면 SQL 문을 다음 구조로 변경해야 합니다:
Copied!1 2 3 4 5 6 7 8 9SELECT /* 강제_병렬성_열({{column}}), 강제_병렬성_크기({{size}}) */ column1, column2 FROM {{table_name}} WHERE {{condition}} /* 이미_있는_조건절(TRUE) */
쿼리의 핵심 부분은 다음과 같습니다:
FORCED_PARALLELISM_COLUMN({{column}})- 이것은 테이블이 나눠질 열을 지정합니다.
- 가능한 한 _균일한 분포_를 가진 숫자 열 (또는 숫자 열을 생성하는 열 표현식)이어야 합니다.
FORCED_PARALLELISM_SIZE({{size}})- 병렬 처리 정도를 지정합니다. 예를 들어,
4는 지정된 병렬 처리 열에 대한 값이 분할된 4개의 동시 쿼리와 NULL 값에 대한 쿼리가 있는 병렬 처리 열로 총 5개의 동시 쿼리를 생성합니다.
- 병렬 처리 정도를 지정합니다. 예를 들어,
ALREADY_HAS_WHERE_CLAUSE(TRUE)- 이미
WHERE절이 있는지 또는 생성할 필요가 있는지를 지정합니다. 이 값이FALSE인 경우, 생성된 각 쿼리에WHERE column%size = X가 추가됩니다. 이 값이TRUE인 경우, 이 조건은 대신AND로 추가됩니다.
- 이미
예제
employees라는 테이블을 동기화한다고 가정하고, 다음 데이터가 포함되어 있다고 가정합니다:
| id | name | surname |
|---|---|---|
1 | Jane | Smith |
2 | Erika | Mustermann |
3 | Juan | Perez |
NULL | Mary | Watts |
기본 쿼리는 다음과 같이 보일 것입니다:
Copied!1 2 3 4 5 6SELECT id, -- 아이디 name, -- 이름 surname -- 성 FROM employees -- 직원 테이블
이 작업은 데이터베이스에서 단일 쿼리를 실행하고 테이블의 모든 레코드를 검색하려고 시도합니다.
병렬 메커니즘을 활용하려면 쿼리를 다음과 같이 변경할 수 있습니다:
Copied!1 2 3 4 5 6SELECT /* 강제_병렬화_열(id), 강제_병렬화_크기(2) */ id, name, surname FROM employees /* 이미_조건_절이_있음(FALSE) */
다음 세 가지 쿼리가 병렬로 실행됩니다:
Copied!1 2 3 4 5 6SELECT id, name, surname FROM employees WHERE id % 2 = 1 -- 홀수 id만 선택
추출:
| id | name | surname |
|---|---|---|
1 | Jane | Smith |
3 | Juan | Perez |
그리고
Copied!1 2 3 4 5 6SELECT id, name, surname -- id, 이름, 성을 선택합니다 FROM employees -- 직원 테이블에서 WHERE id % 2 = 0 -- 짝수 id를 가진 직원들만 필터링합니다
추출:
| id | name | surname |
|---|---|---|
2 | Erika | Mustermann |
그리고
Copied!1 2 3 4 5 6 7 8SELECT id, -- 아이디 name, -- 이름 surname -- 성 FROM employees -- 직원 테이블 WHERE id % 2 IS NULL -- 아이디가 짝수인 직원 검색
추출하기:
| id | name | surname |
|---|---|---|
NULL | Mary | Watts |
OR 조건을 포함한 WHERE 절과 병렬성
OR 조건을 포함한 WHERE 절을 사용하여 병렬성을 사용할 때 괄호를 사용하여 조건이 어떻게 평가되어야 하는지를 나타내야 합니다. 예를 들어 아래에 제공된 동기화를 살펴보세요:
Copied!1 2 3 4 5 6 7SELECT /* 강제 병렬성 열(col1), 강제 병렬성 크기(32) */ col1, col2 FROM tbl WHERE condition1 = TRUE OR condition2 = TRUE /* 이미 WHERE 절이 있음(TRUE) */
이 예제 동기화는 다음과 같이 변환됩니다:
Copied!1condition1 = TRUE OR condition2 = TRUE AND col1 % X = 0 -- 조건1은 참이거나 조건2가 참이고 col1을 X로 나눈 나머지가 0일 때
그러나 해당 문은 condition1 = TRUE OR (condition2 = TRUE AND col1 % X = 0)처럼 논리적으로 해석될 수 있으며, 원하는 (condition1 = TRUE OR condition2 = TRUE) AND col1 % X = 0와 다릅니다. WHERE 절 전체를 괄호로 묶음으로써 의도한 해석을 보장할 수 있습니다. 위의 예시에서는 다음과 같이 됩니다:
Copied!1 2 3 4 5 6 7SELECT /* 강제 병렬 처리 열(col1), 강제 병렬 처리 크기(32) */ col1, col2 FROM tbl WHERE (condition1 = TRUE OR condition2 = TRUE) /* 이미 WHERE 절이 있음(TRUE) */