분석 최적화
아래의 제안사항을 따라 Contour 분석과 대시보드의 성능을 향상시키세요.
분석 구조화
중복 로직 최소화
분석에 다중 경로가 포함되어있고 대부분의 중복 로직을 사용하여 여러 결과물을 계산하는 경우(예: 최종 몇 가지 경로만 새로운 지표를 계산하기 위해 여러 경로에 걸쳐 동일한 필터링 기준을 적용하는 경우), 이러한 경로의 중복을 최소화하십시오. 대신 공통 입력 경로를 사용하고 해당 경로의 결과를 다른 경로의 입력으로 사용하세요.
조인
조인 전에 가능한 한 많은 데이터셋을 필터링하세요. 조인하기 전에 데이터셋을 필터링하려면 새 Contour 경로에서 데이터셋을 열고 필터 조건을 추가한 다음, 데이터셋 대신 해당 경로의 결과에 조인하십시오. 이렇게 하면 성능이 크게 향상됩니다.
"어느 것이든 일치"를 사용한 다중 조건 조인
"어느 것이든 일치"를 사용한 다중 조건 조인은 데이터의 분산 방식 때문에 Spark에서 특히 자원이 많이 소모됩니다. 작업 전에 가능한 한 규모를 줄이려면 필터를 상위 스트림으로 밀어 넣으십시오. 다중 조건 조인은 종종 분석을 다르게 설계함으로써 피할 수 있습니다. 예를 들어, 별도의 조인을 여러 개 적용하고 결과를 결합합니다.
데이터셋으로 저장
보드 또는 일련의 보드의 출력이 다운스트림 보드(동일한 경로 또는 다른 경로에서)에서 여러 번 사용되는 경우, 출력을 Foundry 데이터셋으로 저장하고 새롭게 저장된 데이터셋에서 모든 다운스트림 계산을 시작하는 것이 매우 유용할 수 있습니다. 이는 출력이 복잡한 연산(예: 조인, 피벗 테이블, 또는 정규식 필터)을 포함하는 경우 특히 그렇습니다.
파라미터 사용
사용자가 파라미터 값을 변경하면 분석의 모든 보드가 다시 계산됩니다. 시작 데이터셋, 파라미터를 사용하지 않는 많은 연산, 그리고 파라미터를 사용하는 필터가 있는 분석을 상상해보십시오. 가능하면 파라미터를 사용하지 않는 연산 후에 출력을 데이터셋으로 저장하십시오. 이렇게 하면 새 파라미터 항목에 대한 차트와 그래프를 다시 계산하는 데 걸리는 시간이 단축됩니다.
프론트엔드 성능
분석이 빠르고 반응성이 좋게 로드되도록 하려면 분석 당 경로를 15 - 20개로 제한하는 것이 좋습니다. 이 제한을 초과하는 경우 분석을 여러 개로 나누십시오.
필터 사용
가능한 한 구체적인 필터 사용
필터를 적용할 때 대/소문자 구분을 사용하고, "contains"보다는 "exact match" 필터를 선호하거나 기본 데이터를 모두 대문자 또는 모두 소문자로 만드십시오. 특히 정규 표현식 사용은 연산 비용이 많이 듭니다.
예를 들어, 데이터셋을 모두 소문자 또는 모두 대문자로 만들어 대/소문자 구분 필터링을 사용할 수 있도록 하고 필터링 기준이 가능한 한 정확하게 사용되어 정확한 일치(예: 텍스트의 경우 contains 대신 is)를 사용하여 성능을 향상시킬 수 있습니다.
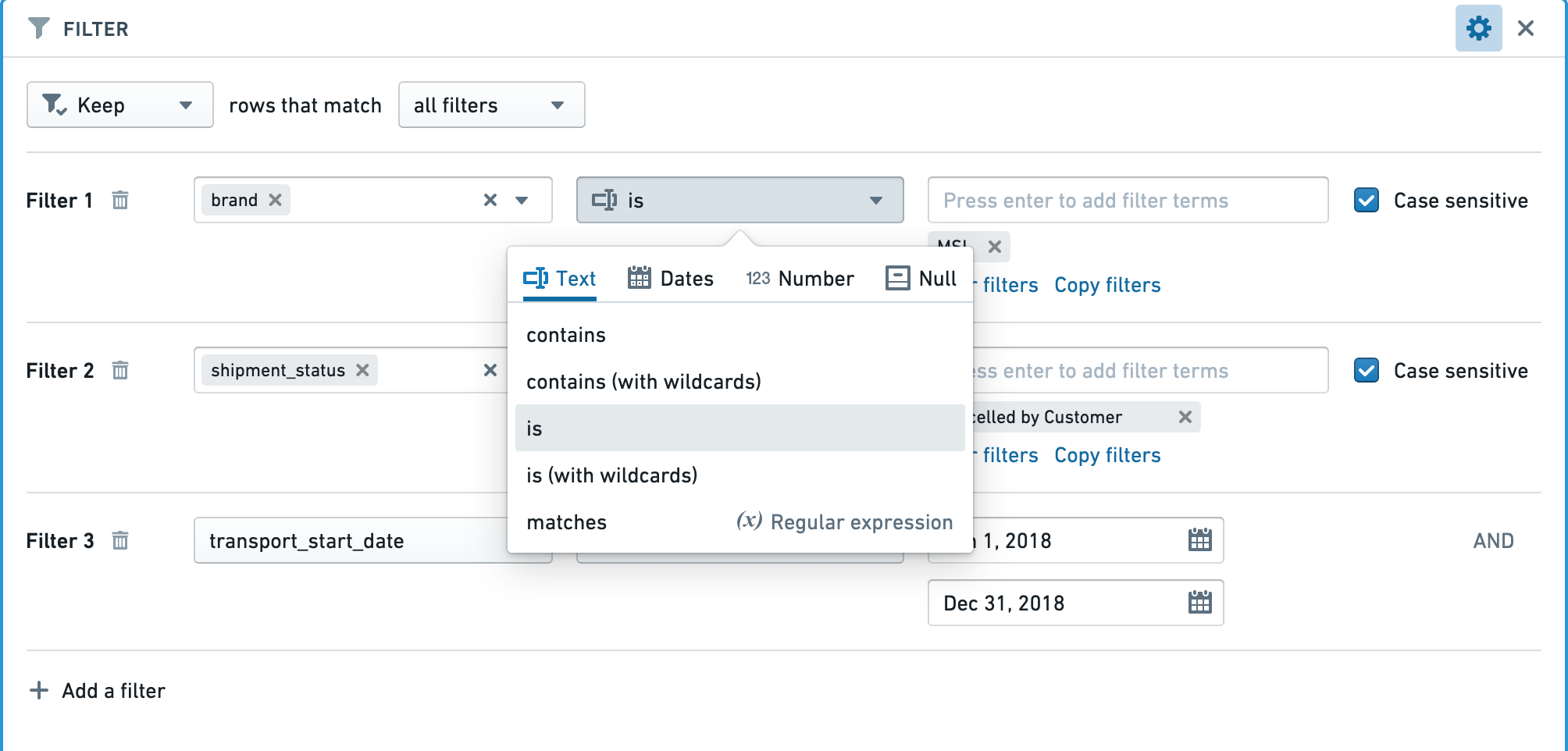
열 유형에 맞는 필터 적용
열 유형에 맞는 필터를 사용하십시오.
예를 들어, integer, long 또는 double 유형 열에서 정확한 숫자에 대한 필터를 적용할 때 "Number equal to" 필터를 사용하면 "String exact match" 필터보다 훨씬 빠릅니다.

입력 데이터셋
파티셔닝
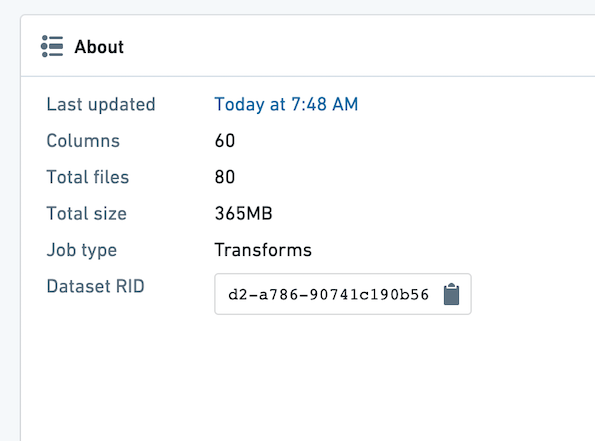
Contour 분석에서 사용하는 데이터셋이 잘 파티셔닝되어 있는지 확인하세요. 데이터셋 내 파일의 평균 파일 크기는 최소한 128MB여야 합니다. 데이터셋을 열고 "About" 탭을 선택하여 데이터셋의 파일 수와 크기를 확인할 수 있습니다.
아래 예에서 파일이 80개 있고 데이터셋이 365MB입니다. 이는 잘못된 파티셔닝이므로 최대 세 개의 파일만 있어야 합니다.
입력 데이터셋이 잘못 파티셔닝된 것으로 확인되면 상위 변환에서 파티셔닝할 수 있습니다.
상위 파이썬 변환에서 파티션을 나누려면 이 코드 줄을 추가하세요:
# Repartition – df.repartition(num_output_partitions)
# 재분할 – df.repartition(출력 파티션 수)
df = df.repartition(3)
Partitioning 및 Spark에서의 효과에 대한 자세한 정보는 Spark 최적화 개념을 검토하십시오.
Projections
데이터셋 소유자는 데이터셋에서 다양한 유형의 쿼리 성능을 향상시키기 위해 프로젝션 구성을 할 수 있습니다.
입력 데이터셋에 프로젝션이 구성되어 있다면, 프로젝션은 아래 그림과 같이 시작 보드의 Optimized 섹션에 나열됩니다. 나열된 열 중 하나에 정확한 일치 필터를 구성하여 프로젝션을 활용할 수 있습니다. 현재 Contour에서는 입력 데이터셋의 모든 열이 포함된 필터 최적화 프로젝션에 대한 정보만 표시됩니다.
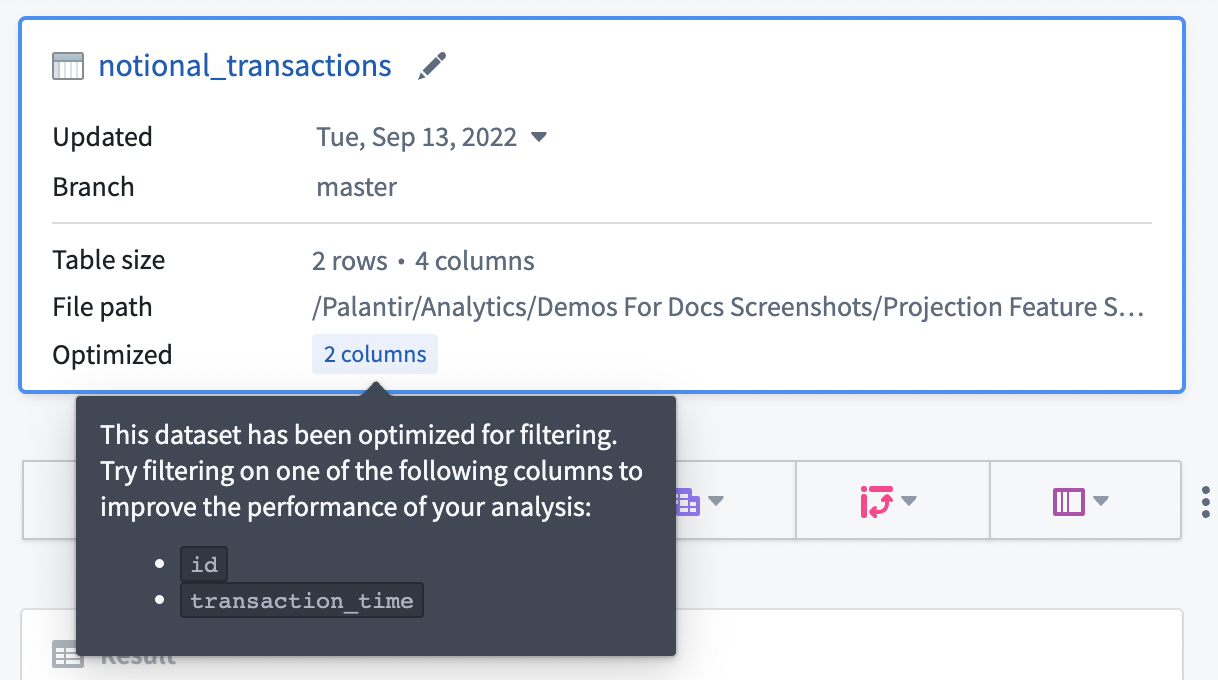
일반적으로, Contour에서 성능을 향상시키기 위해 예측 가능한 쿼리 패턴이 있는 데이터셋에 프로젝션을 구성하는 것이 좋습니다. 컴퓨팅 사용량을 줄이기 위해 데이터셋이 자주 사용되는 경우(즉, 쓰기 당 특정 패턴이 10-100번 읽히는 경우)에만 프로젝션을 설정하는 것이 좋습니다. 프로젝션을 구축하고 저장하려면 데이터셋이 작성될 때마다 추가 계산이 필요하므로, 계산이 하류에서 일관되게 활용될 때만 절약이 실현됩니다.
분석 유지 및 공유하기
위에서 언급한 모든 최적화는 Contour 분석이 대규모 관객에게 소비되는 경우 특히 중요합니다.
빌드 일정 설정하기
Contour에서 빌드된 데이터셋에 대한 일정을 설정할 때는 빈도를 충분히 고려해 계획하십시오. 일정을 설정한 후 빌드를 모니터링하여 필요한 빈도로 데이터가 표면화되어 자원을 불필요하게 빌드하지 않도록 합니다. 예를 들어, Contour에서 빌드된 데이터셋이 일일 업데이트되는 데이터셋을 가져올 경우, 데이터셋을 매시간 빌드할 필요가 없습니다.
파라미터 제한하기
Contour 분석이 대규모 관객에게 보고서로 소비되는 경우, 파라미터 수를 최소한으로 제한하는 것이 좋습니다.
이상적인 보고서 위젯은 사용자가 입력한 파라미터 값에 따라 일부 필터링을 수행하고, 사용자에게 관련된 시각화를 보여주기 위해 집계를 수행합니다. 이상적으로, 다른 복잡한 로직(조인 및 피벗)은 Foundry의 데이터셋에서 사전 계산되므로 각 파라미터 변경에 따라 다시 계산할 필요가 없습니다.