표현식 보드 사용하기
히스토그램과 차트와 같은 시각 도구 외에도 Contour는 표현식 보드를 제공하여 데이터에서 새로운 열을 도출하거나 복잡한 필터링을 수행하거나 복잡한 집계를 수행하는 데 Contour의 풍부한 표현 언어를 사용할 수 있습니다. Contour의 표현 언어는 SparkSQL의 여러 함수를 포함하는 커스텀 언어입니다.
- 표현식 에디터를 사용할 때 ? 아이콘을 사용하여 표현 언어에 대한 빠른 참조를 확인하세요.
- 입력하면 드롭다운에 제안된 함수가 표시됩니다. 클릭하거나 엔터 키를 사용하여 함수를 선택하세요.
열 이름은 대소문자를 구분합니다. 또한 열을 선택할 때 열 이름을 큰따옴표를 사용하여 작성하거나 큰따옴표 없이 작성할 수 있습니다. 예를 들어, year("birthdate_col")은 year(birthdate_col)와 동일합니다. 일관성을 위해 이 문서에서는 열 이름을 큰따옴표로 작성했습니다.
표현식 보드 추가하기
툴바에서 Contour 분석에 표현식 보드를 추가할 수 있습니다. 이 개요에서 설명한 것처럼 진행하세요:

이 예제는 미국 교통통계국의 오픈 소스 데이터를 Foundry Reference Project에 저장하여 사용합니다.
표현식 보드 구성하기
표현식 보드에는 저장된 표현식의 라이브러리와 에디터 두 가지 모드가 있습니다.
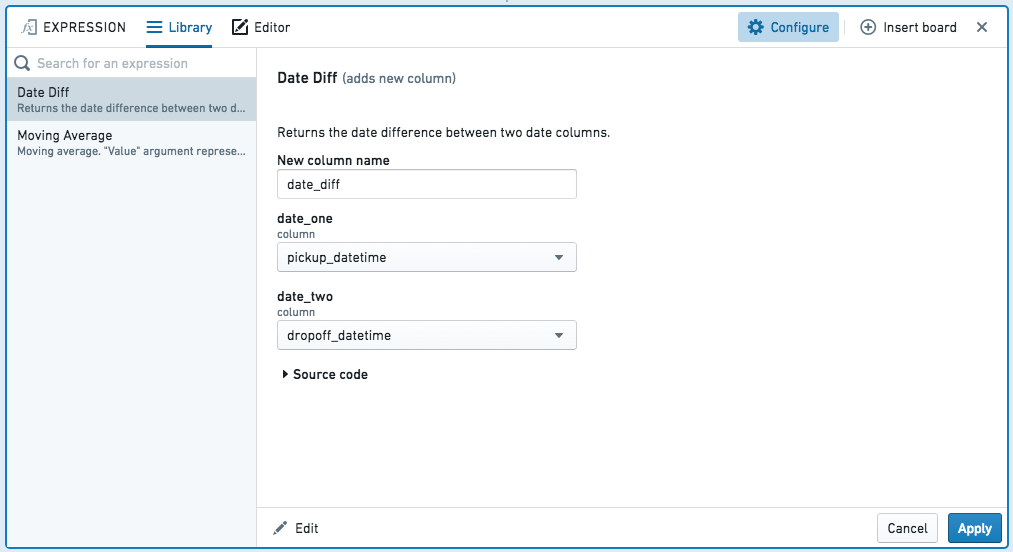
라이브러리
라이브러리를 사용하면 인수와 함께 작성한 표현식을 다시 사용할 수 있습니다:
에디터
에디터 내에서 작성할 수 있는 표현식에는 네 가지 카테고리가 있습니다:
- 새 열 추가
- 열 교체
- 필터
- 집계
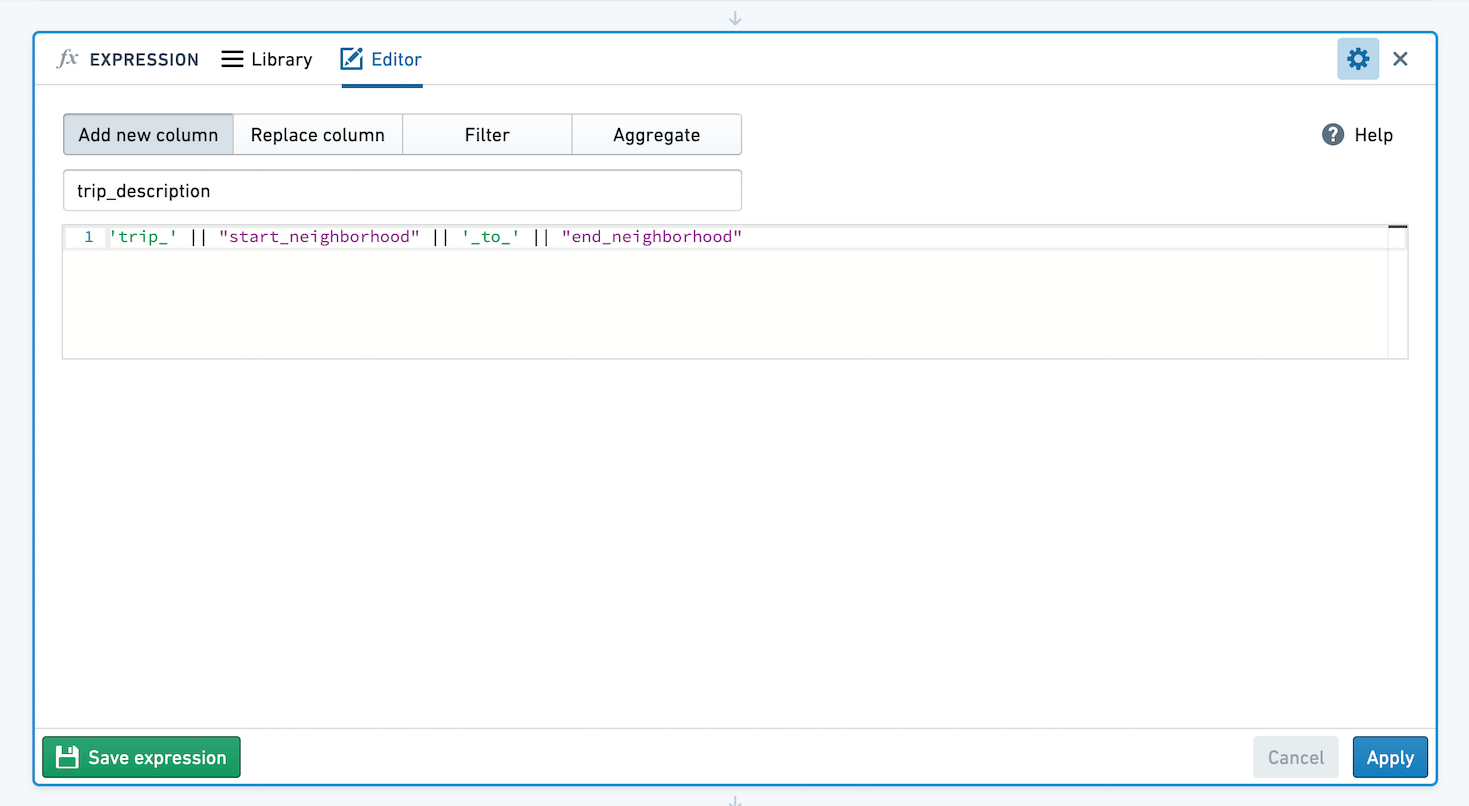
새 열 추가하기
새 열의 이름과 해당 열을 구성하는 표현식을 입력하세요. 예를 들어, 생일에서 년도를 추출하여 새 열을 만들기 위해 year("birthdate_col")을 사용하거나, 다른 열의 값들을 연결하여 택시 여행 설명 스트링이 포함된 열을 생성하세요:
열 교체하기
교체할 열을 선택하고 교체할 표현식을 입력하세요.
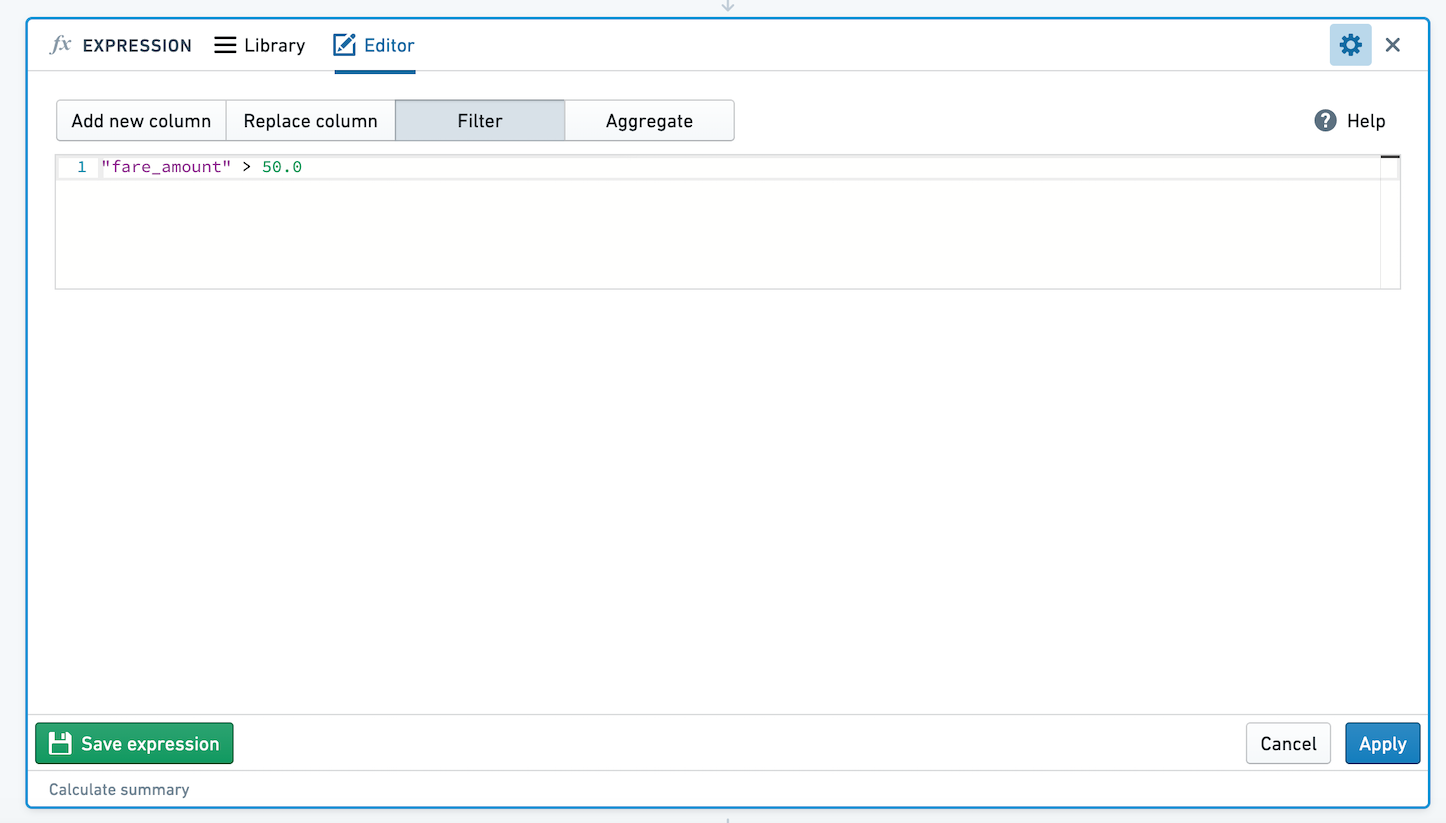
표현식으로 데이터 필터링하기
Boolean으로 평가되는 표현식을 입력하여 필터 조건을 정의하세요. 표현식이 true로 평가되는 모든 행의 데이터가 필터링됩니다. 예를 들어, year("birthdate_col") == 1981을 사용하여 1981년에 태어난 사람만 필터링하거나, 요금이 $50 이상인 택시 여행만 필터링하는 테이블을 사용하세요:
SparkSQL의 제한으로 인해 필터 표현식에서 window 함수(OVER 구문)를 사용할 수 없습니다. 나중에 설명하는 것처럼 새 열을 생성하는 데 사용할 수 있습니다.
다음 섹션에는 Contour에서 사용할 수 있는 필터 표현식 예제가 포함되어 있습니다.
일반 예제
열을 정적 값과 비교하기
"taxi_fare" < 25.0 # 택시 요금이 25.0보다 작은지 확인
"birth_date" == '1776-07-04' # "birth_date" 는 '1776-07-04'와 같은가요?
표현식 보드 에디터에서, null = null은 true를 생성합니다. 이것은 SparkSQL에서 null = null이 null로 처리되는 것과 다릅니다.
같지 않음 연산자를 사용하여 필터링
league_id가 'NHL'과 같지 않은 모든 행을 필터링합니다:
league_id != 'NHL' # league_id가 'NHL'이 아닌 경우
두 열 비교
"age" < "average_age" # "age"는 "average_age"보다 작다
팁 비율(팁 나누기 요금)이 average_tip_percentage보다 크거나 같은 행으로 필터링:
("tip" / "fare") >= "average_tip_percentage" # "팁" / "요금"이 "평균_팁_비율"보다 크거나 같은지 확인
널 값이 있는 행 제거
category가 널이 아닌 모든 행으로 필터링:
not isnull("category") # "category"가 널값이 아닌지 확인
특수 문자를 사용하여 열 분할하기
|를 사용하여 categories 열을 분할합니다. |는 특수 문자의 예시이므로, 문자 그대로 취급하기 위해 이스케이프 처리해야 합니다.
SPLIT("categories", '\|') # "categories" 문자열을 '|' 문자를 기준으로 분리합니다.
LIKE를 사용하여 패턴 검색
열 값의 패턴을 검색하기 위해 SQL LIKE 연산자를 사용하십시오.
A로 끝나는 모든 국가 이름과 일치:
"country_name" LIKE '%a' -- 국가 이름이 'a'로 끝나는 경우
여러 조건으로 필터링
두 개 이상의 필터 표현식을 AND 또는 OR로 결합하세요:
("start_borough" == 'Queens') AND ("end_borough" == 'Queens') # 'start_borough' 가 퀸즈이고, 'end_borough' 도 퀸즈인 경우
"department"은 'sales' 이거나 "department"은 'r&d'
최소값 또는 최대값 행 찾기
데이터 분석에서 일반적인 작업은 파티션 내에서 특정 열의 최소값 또는 최대값을 가진 행을 찾는 것입니다. 예를 들어, 환자 기록을 포함한 데이터셋이 있고 각 환자가 처음으로 사무실을 방문한 날짜를 찾고 싶을 수 있습니다. 이러한 행을 찾기 위해 두 개의 표현식을 사용할 수 있습니다.
새로운 열을 먼저 파생시키고 그것을 사용하여 필터링해야 합니다. 이는 SparkSQL의 제한으로 인해 필터 표현식에서 창 함수를 사용할 수 없기 때문입니다.
먼저, 새로운 열을 파생시켜 파티션의 최소값 또는 최대값을 찾습니다. 다음 예에서는 각 택시(메달리온 번호로 식별)가 가장 최근에 탑승한 시간을 결정하고, 새로운 열 most_recent_ride를 생성합니다:
max("pickup_datetime") OVER (PARTITION BY "medallion") -- "medallion" 별로 그룹화하여 가장 최근의 "pickup_datetime" 찾기
OVER를 사용하는 윈도우 함수에 대한 리프레셔가 필요하면 고급 표현식: 윈도우 함수를 참조하십시오.
그런 다음 각 행의 픽업 날짜 값을 해당 파티션의 최대 값과 비교하는 필터 표현식을 추가하십시오:
"pickup_datetime" == "most_recent_ride" # "pickup_datetime"은 "most_recent_ride"와 같은 의미입니다.
표현식으로 데이터 집계하기
이 모드는 group by 표현식과 집계 표현식을 사용하여 데이터를 집계할 수 있습니다. group by 표현식은 0개, 1개 또는 여러 개가 있을 수 있으며, 집계 표현식은 1개 또는 여러 개가 있을 수 있습니다. 각 group by 및 집계 표현식에는 이름을 부여해야 하며, 결과 표는 각 표현식에 대한 하나의 열로 구성된 새로운 스키마를 갖게 됩니다.
예를 들어, 시작 이웃에 따른 평균 택시 여행 거리를 집계하는 다음 표현식이 주어진 경우:
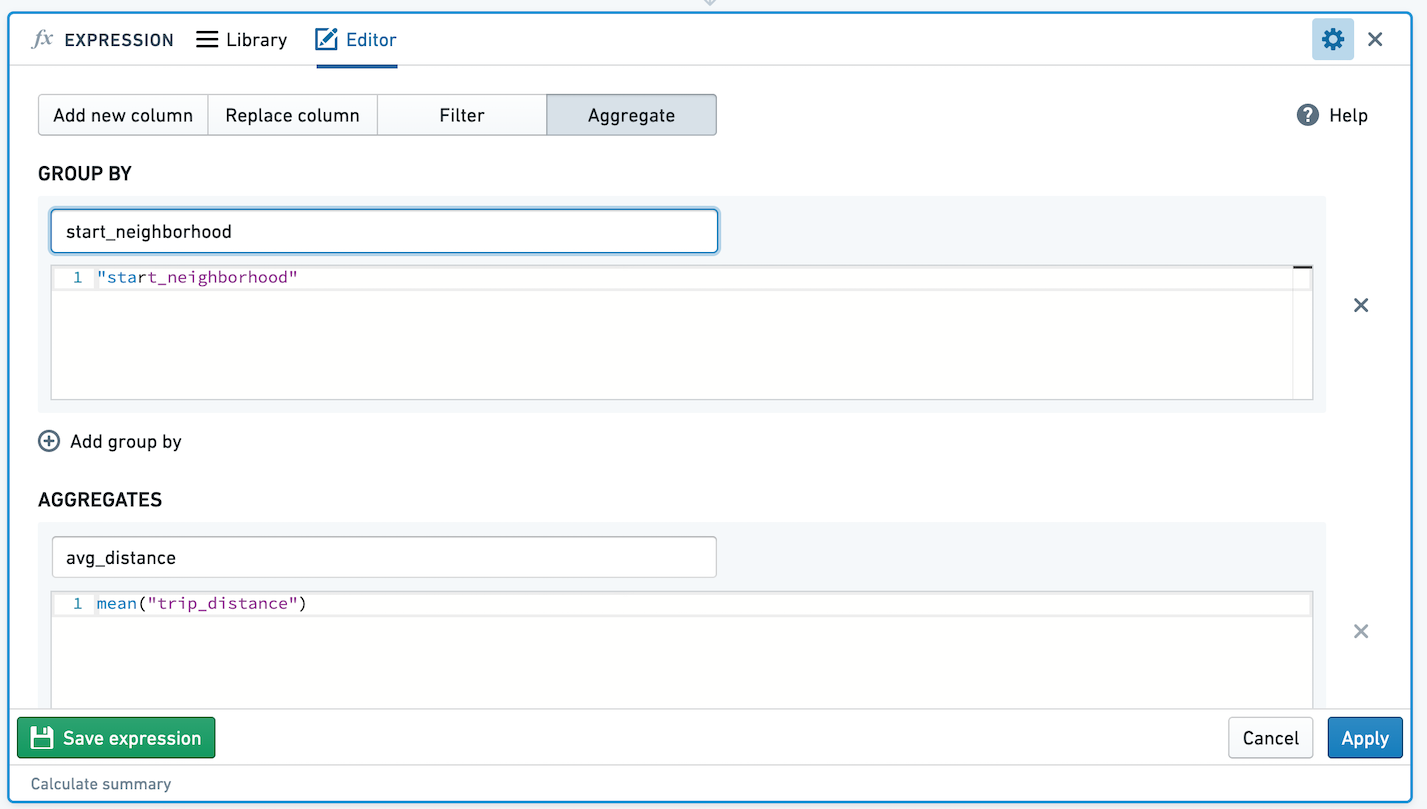
결과 표는 다음과 같습니다:
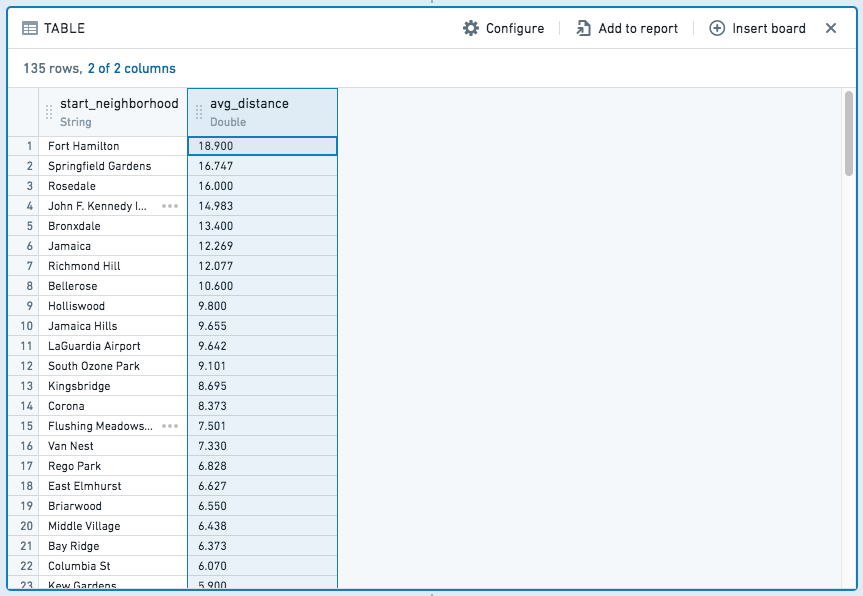
add-column 및 filter 표현식과 달리, 집계 표현식은 집계 및 그룹별 파티션에 대한 열이 있는 완전히 새로운 표를 생성합니다.
예를 들어, 다음과 같은 가상의 데이터셋이 주어진 경우:
| id | name | sport | birthday | number_of_gold_medals |
|---|---|---|---|---|
| 1 | Jane | Swimming | 6/29/1985 | 6 |
| 2 | John | Gymnastics | 2/19/1971 | 3 |
| 3 | Mike | Swimming | 3/23/1971 | 7 |
| 4 | Michelle | Gymnastics | 9/12/1971 | 5 |
총 금메달 개수를 알고 싶다면, 다음을 사용하십시오:

그러면 다음 표가 생성됩니다:
| sum |
|---|
| 21 |
출생 연도와 종목별로 총 금메달 수와 평균 금메달 수를 알고 싶다면, 다음을 사용하십시오:

그러면 다음을 얻을 수 있습니다:
| birth_year | sport | sum | average |
|---|---|---|---|
| 1971 | Swimming | 7 | 7 |
| 1971 | Gymnastics | 8 | 4 |
| 1985 | Swimming | 6 | 6 |
집계 결과로 생성된 새 표에서 분석을 수행하려면, 집계된 데이터로 전환할 수 있습니다.
저장된 표현식
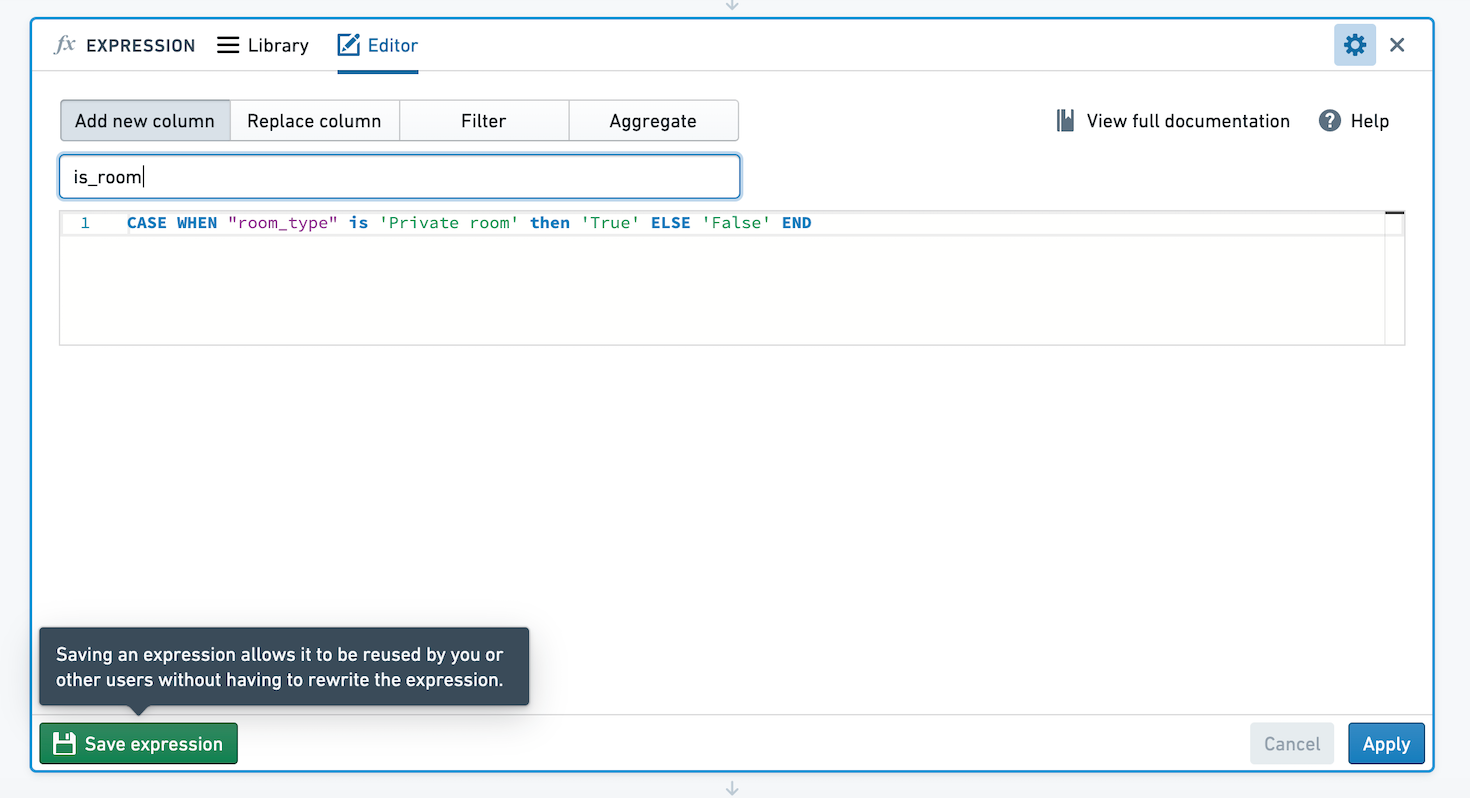
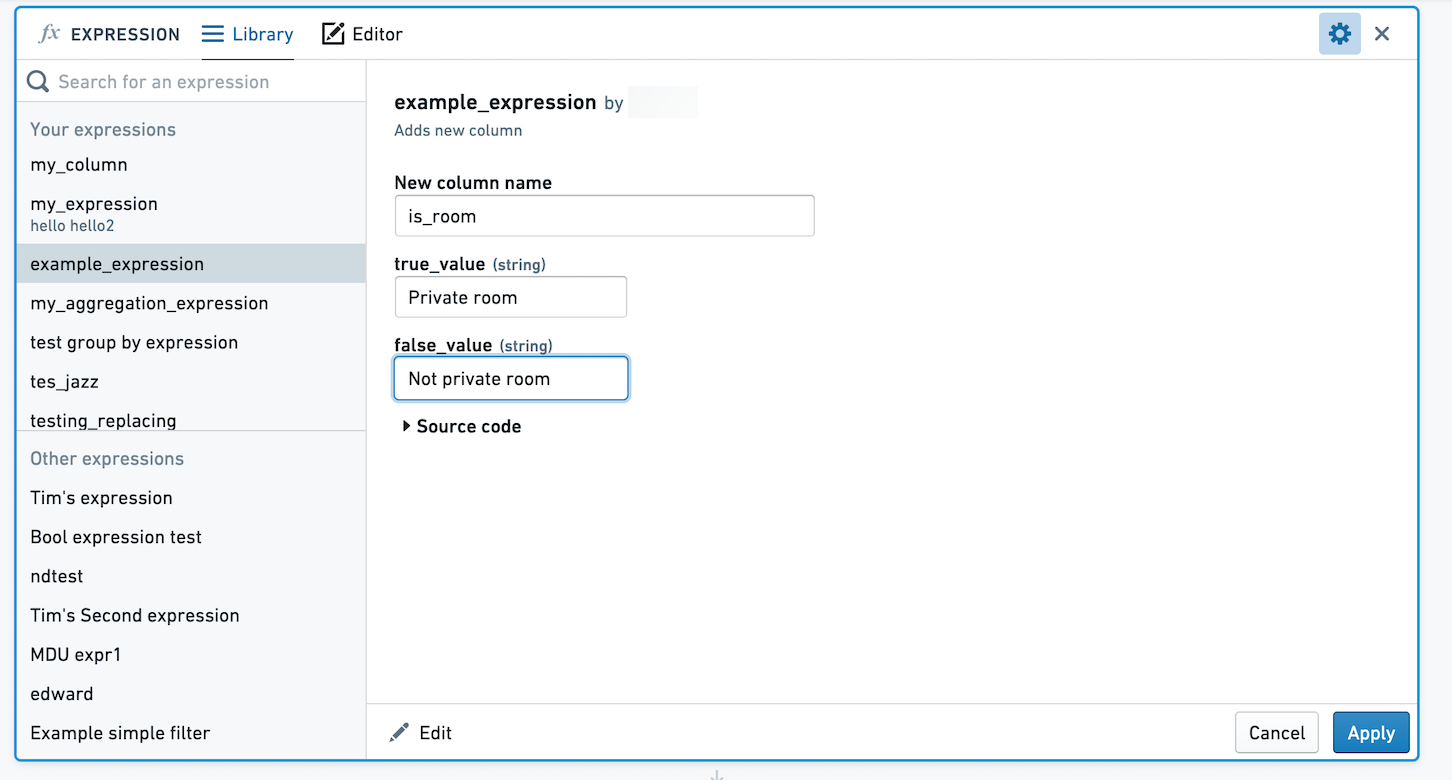
Contour에서는 표현식을 저장하여 분석 및 경로 간에 쉽게 로직을 재사용하고 다른 사람과 로직을 공유할 수 있습니다. 새 열을 만드는 표현식을 생성했다고 가정해 보겠습니다. 열 room_type의 값이 Private room인 경우 값이 True이고, 그렇지 않은 경우 값이 False입니다. 이 표현식을 저장하여 다른 사람들이 이 로직을 사용할 수 있도록 하려고 합니다.
표현식 보드의 왼쪽 하단에서 표현식 저장하기를 클릭하십시오.
표현식을 인수 없이 저장하거나, 표현식에 대한 인수로 정의할 값을 선택할 수 있습니다. 인수가 없는 표현식을 저장하면, 적용될 때 표현식의 로직이 정확하게 유지됩니다. 인수를 정의하면 사용자는 인수에 대해 다른 값을 선택할 수 있습니다. 아래 이미지에서는 True와 False 값을 매개변수화했습니다.
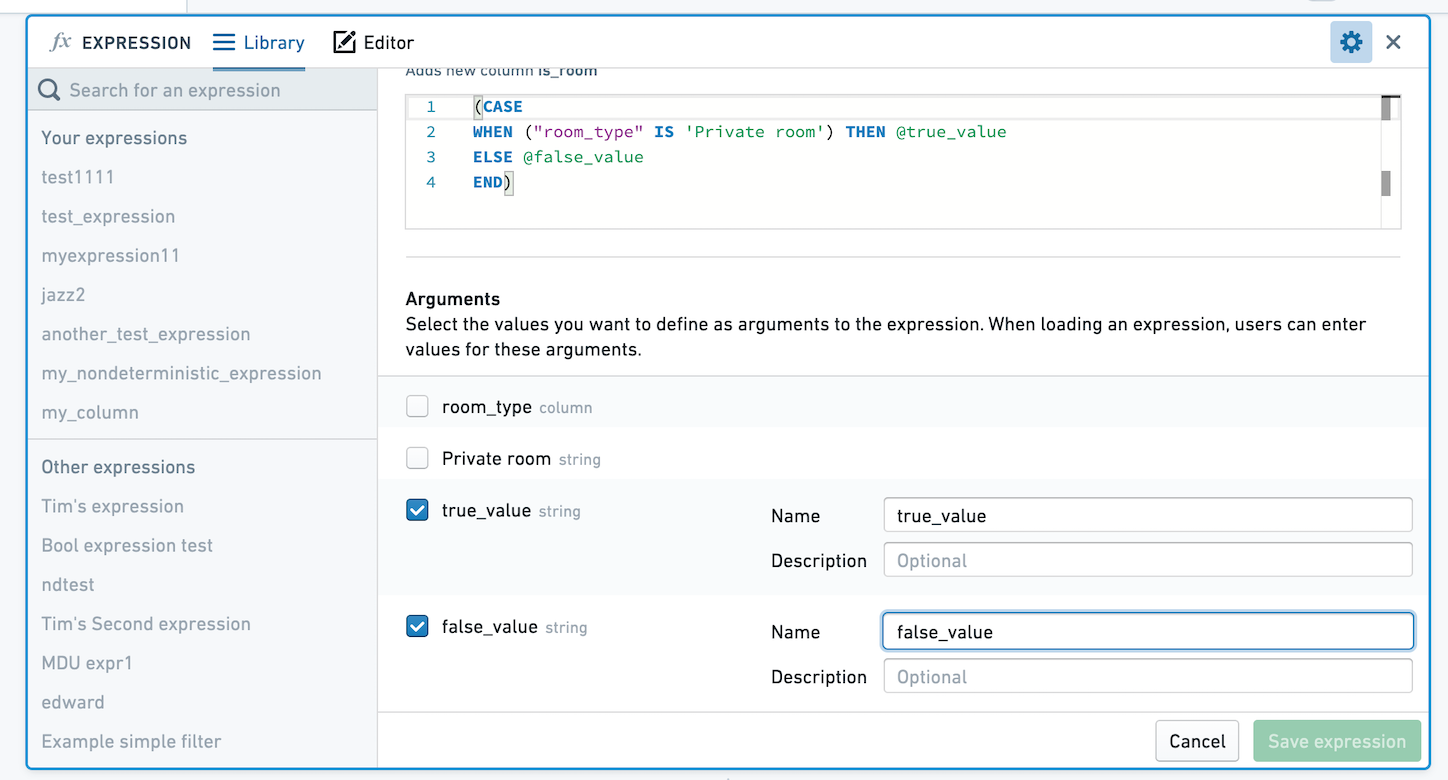
표현식을 적용하려는 사용자는 true_value와 false_value에 대한 값을 선택하도록 요청받습니다. 여기에서 이러한 값은 Private room 및 Not private room에 매핑됩니다.
저장된 집계 표현식
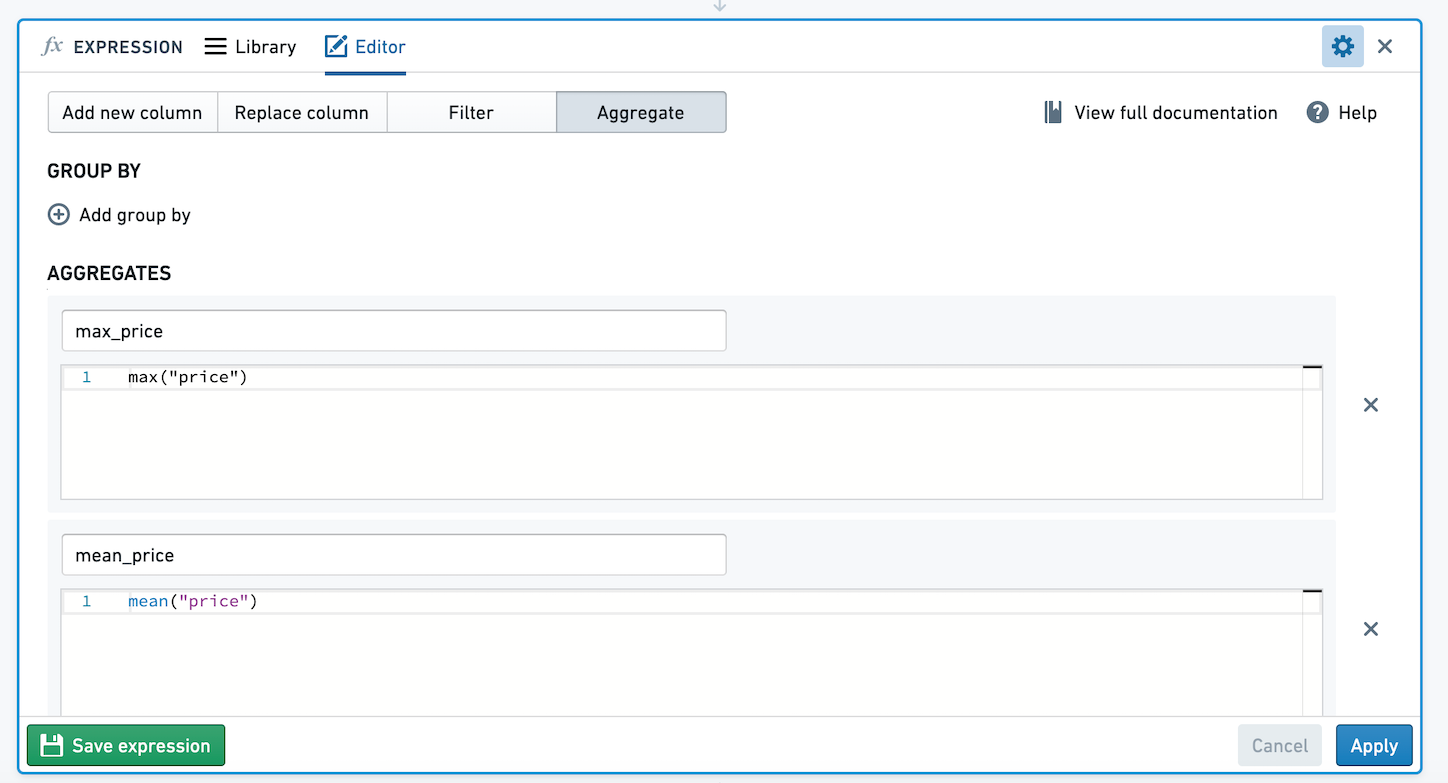
집계 표현식은 0개 이상의 그룹별 기준을 기반으로 데이터를 집계하는 데 사용됩니다. 그룹별 기준이 0개인 집계 표현식을 저장하면, 표현식 사용자는 임의의 수의 열 그룹별 기준을 선택할 수 있습니다.
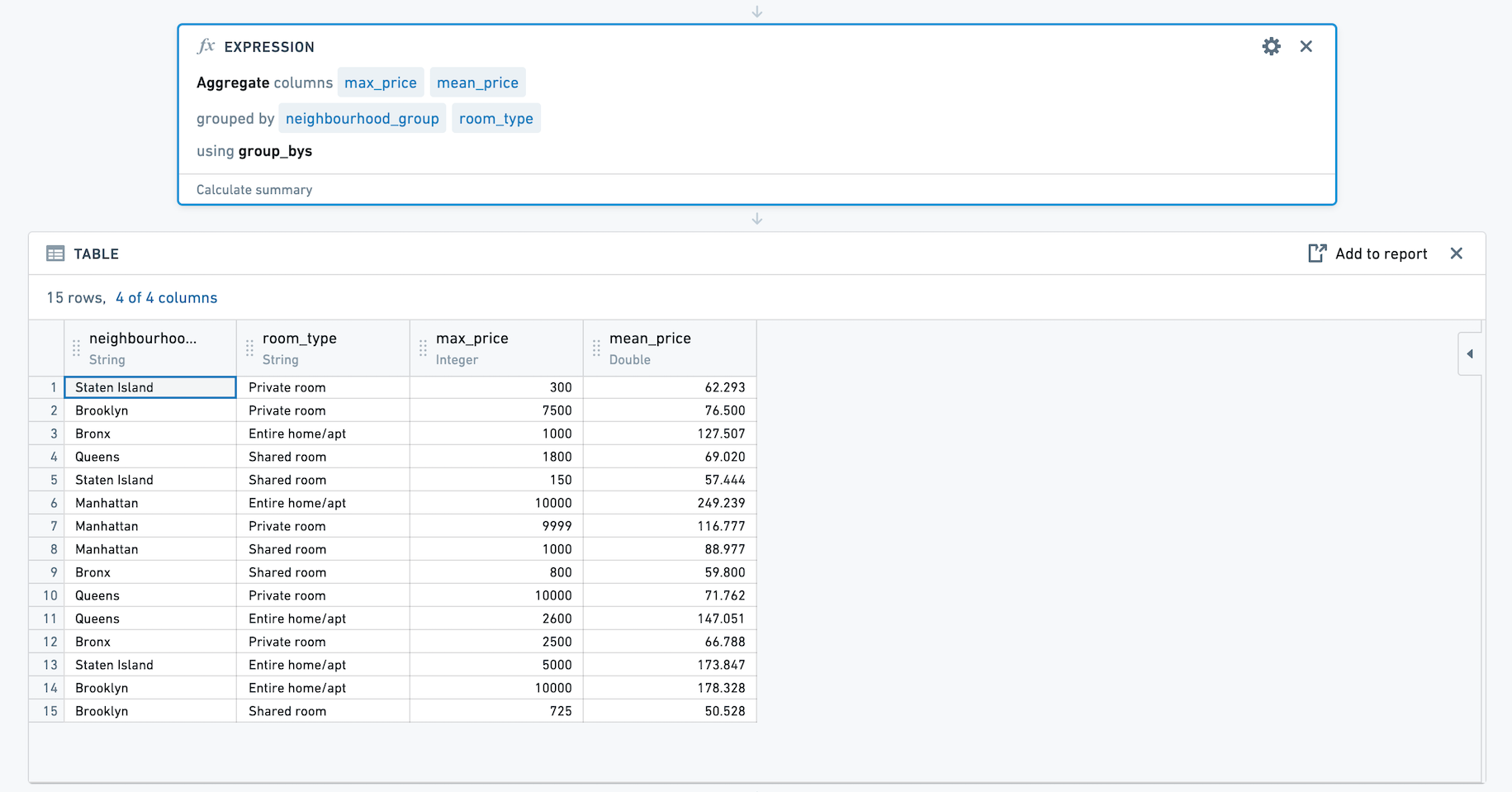
예를 들어, 아래에는 그룹별 기준이 0개이고 Inside Airbnb의 오픈 소스 데이터를 사용하여 price의 평균과 최대값을 계산하는 두 개의 집계가 있는 집계 표현식이 있습니다. 이 집계 표현식을 저장해 봅시다.
이 표현식을 사용할 때 열 선택기가 표시됩니다. 여러 열을 그룹별로 선택할 수 있습니다. 여기에서는 neighbourhood_group 및 room_type 조합별로 price의 평균 및 최대값을 계산합니다.
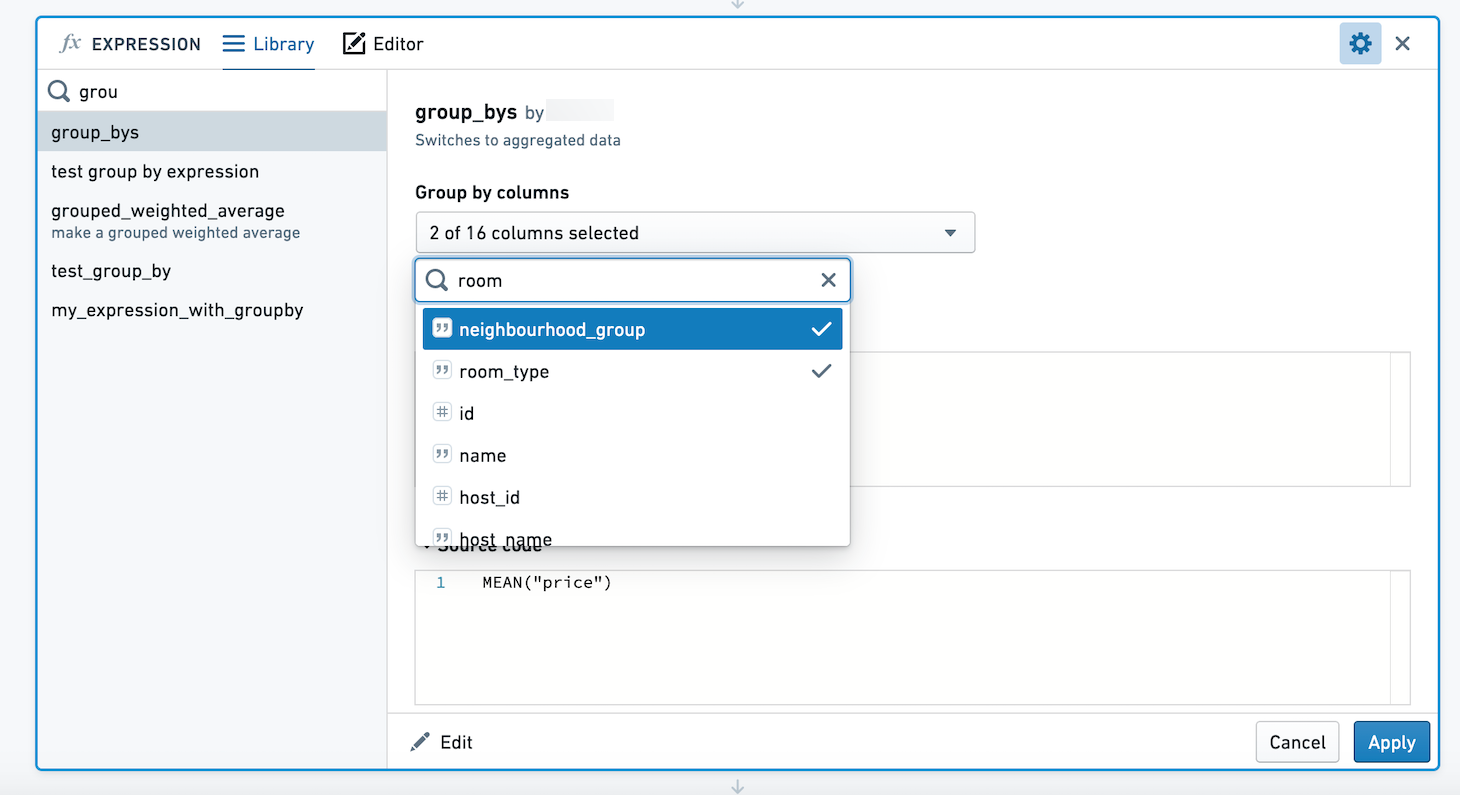
결과 집합에는 neighbourhood_group, room_type, max_price 및 mean_price 네 개의 열이 있습니다.