Contour에서의 비결정성
비결정적 윈도우 함수
ROW_NUMBER, FIRST, LAST, LEAD, LAG, NTILE, ARRAY_AGG, 또는 ARRAY_AGG_DISTINCT를 윈도우 함수에서 사용할 때 비결정성에 주의하세요. 열 A를 기준으로 파티션하고 열 B를 기준으로 정렬한다고 가정해 봅시다. 열 A의 동일한 값에 대해 열 B의 값이 동일한 여러 행이 있는 경우, 이러한 윈도우 함수의 결과는 비결정적일 수 있으며, 동일한 입력 데이터와 로직이 주어진 경우 다른 결과가 나올 수 있습니다.
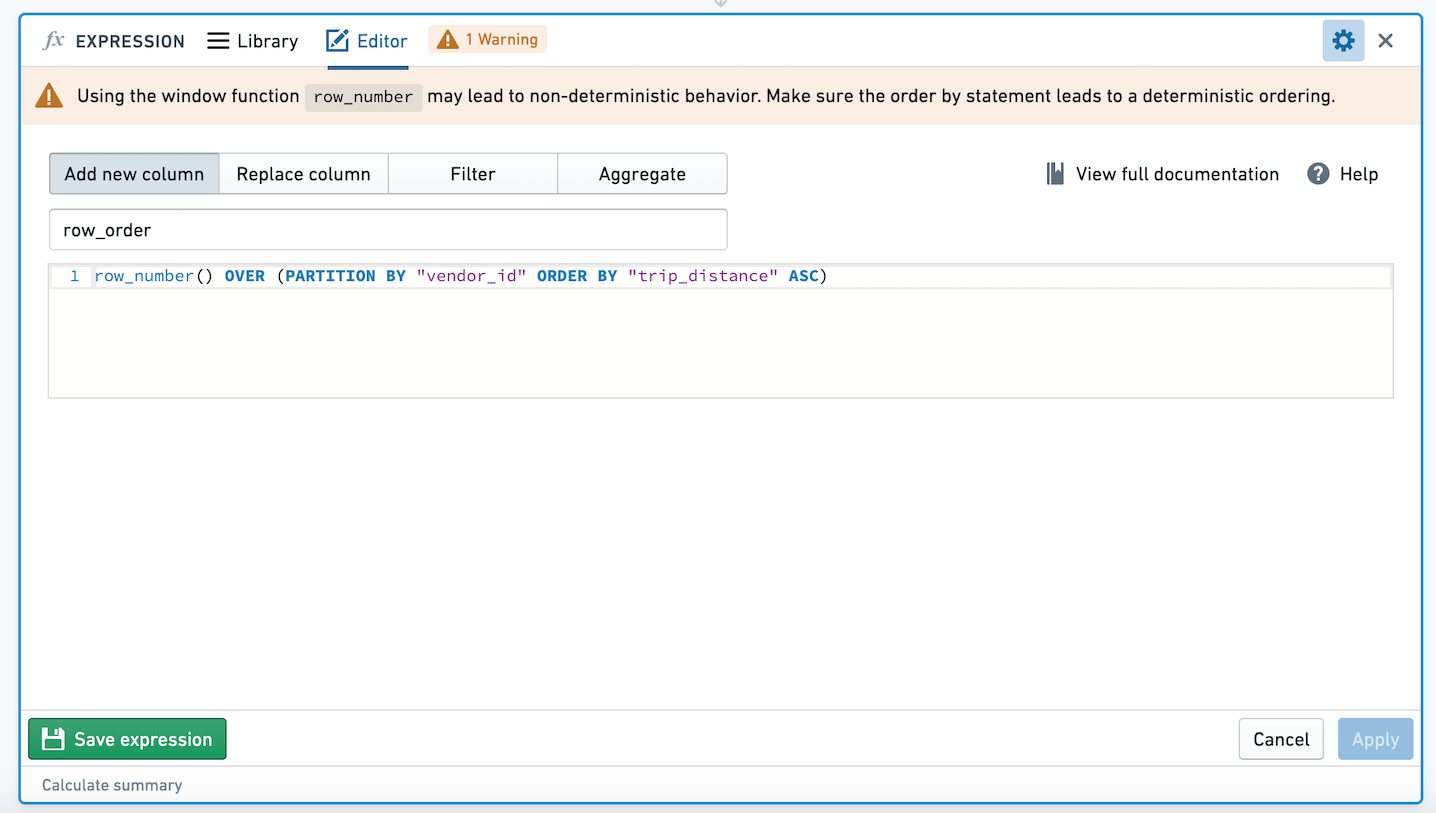
이러한 표현식을 표현식 보드에서 사용할 때, 윈도우 함수의 ORDER BY 절이 결정적인지 확인하기 위해 경고가 표시됩니다.
데이터를 사용한 예를 살펴봅시다:
| name | class | grade |
|---|---|---|
| Aaron | Math | 95 |
| Burt | Math | 95 |
| Chrissy | Math | 80 |
| Angelica | Science | 77 |
| Burt | Science | 81 |
| Charlie | Science | 66 |
각 클래스에서 학생들의 성적순으로 순위를 매기고 싶어서 새로운 열 rank를 표현식 ROW_NUMBER() OVER (PARTITION BY "class" ORDER BY "grade" DESC)를 사용하여 추가합니다.
이 결과를 얻습니다:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 1 |
| Burt | Math | 95 | 2 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
그러나 때때로 이 결과를 얻습니다:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 2 |
| Burt | Math | 95 | 1 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
Aaron과 Burt가 수학에서 같은 성적을 받았기 때문에 rank 열은 비결정적입니다. 열을 결정적으로 만들려면 표현식에서 "name" 열을 order by 절에 추가할 수 있습니다: ROW_NUMBER() OVER (PARTITION BY "class" ORDER BY "grade" DESC, "name" ASC). 이 표현식을 사용하면 동일한 성적을 가진 행이 모두 name 열로 정렬되어 항상 아래 결과를 얻을 수 있습니다:
| name | class | grade | rank |
|---|---|---|---|
| Aaron | Math | 95 | 1 |
| Burt | Math | 95 | 2 |
| Chrissy | Math | 80 | 3 |
| Angelica | Science | 77 | 2 |
| Burt | Science | 81 | 1 |
| Charlie | Science | 66 | 3 |
기타 비결정적 함수
위에서 설명한 윈도우 함수 외에도 CURRENT_DATE, CURRENT_TIMESTAMP, CURRENT_UNIX_TIMESTAMP, MONOTONICALLY_INCREASING_ID 함수는 비결정적입니다.
CURRENT_DATE, CURRENT_TIMESTAMP, CURRENT_UNIX_TIMESTAMP의 경우 값은 경로 업데이트 시에만 계산됩니다. 예를 들어, 1일에 CURRENT_DATE를 사용하여 새 열을 만들고 2일에 분석으로 돌아갈 경우, 새 열은 여전히 어제의 날짜를 반영합니다.
이중 열에 대한 집계
Spark 계산의 분산 특성으로 인해 산술 연산의 피연산자 순서는 비결정적입니다(즉, 1+2 대 2+1). 이러한 비결정적 순서는 입력 유형이 double인 경우 비결정적 결과를 생성하는 집계와 함께 사용할 수 있습니다. 이는 동일한 입력을 갖는 이중 열에 대한 집계가 하나의 계산에서 다른 계산으로 달라질 수 있음을 의미하며, 이 차이는 매우 작습니다(예: 0.000001).
예를 들어, 이중 열의 mean 또는 variance를 취하면 비결정적 열이 생성됩니다. 비결정적 열에서 작업을 수행한 결과(예: 필터링)도 비결정적입니다.
분석에서 이중 열의 mean, sum, stddev, variance, corr, 또는 sum_distinct를 취하면 비결정적 열이 생성됩니다.
예를 들어 살펴봅시다:
pickup_latitude라는 이중 열이 있다고 가정합니다. 피벗 테이블에서 이중 열 pickup_latitude의 평균을 구합니다. 피벗된 데이터로 전환하면 이제 비결정적 열이 생성됩니다.
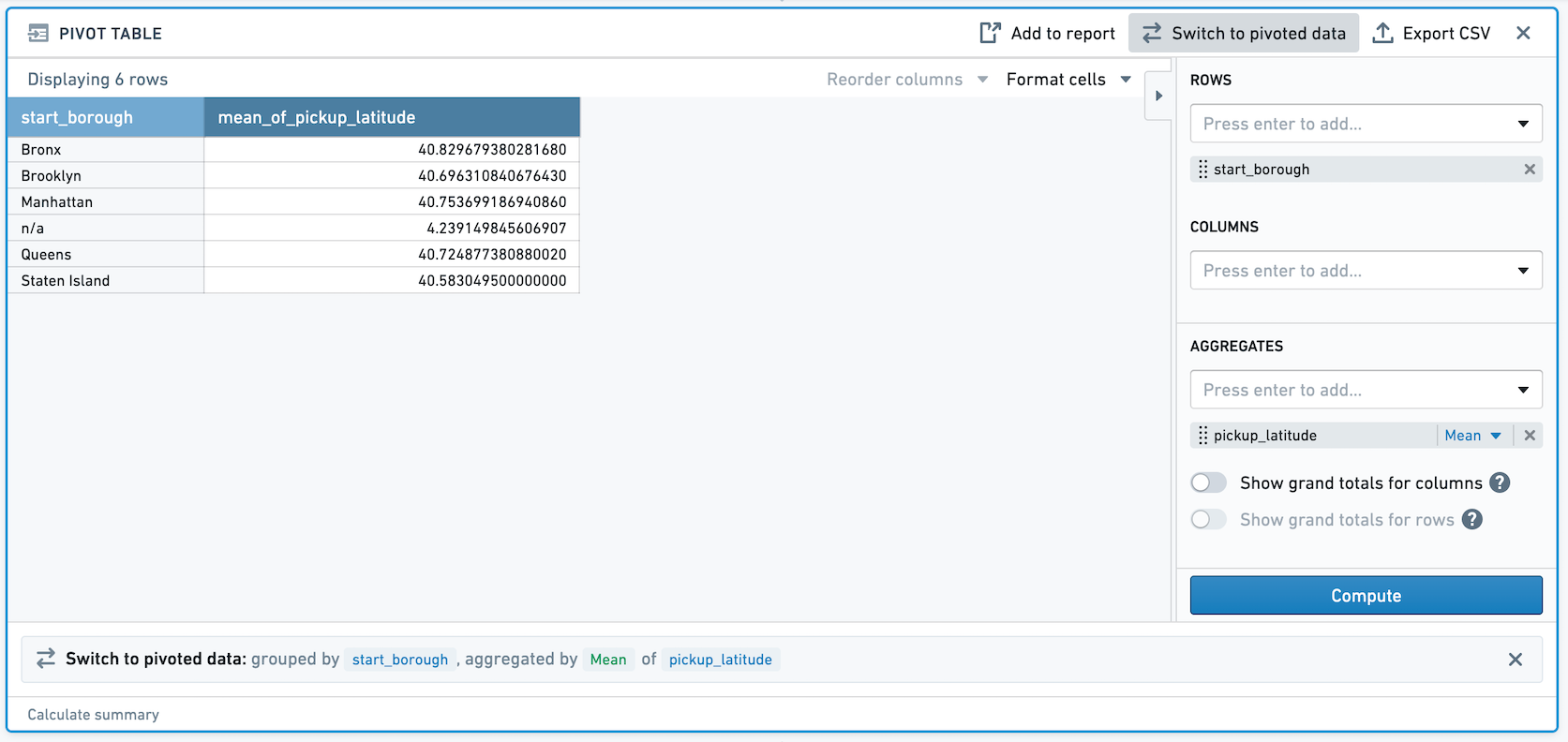
새롭게 생성된 열에 필터를 적용하면, 이 필터의 결과는 비결정적입니다. 예를 들어, 위 스크린샷에서 Staten Island의 평균 pickup_latitude는 40.5830495입니다. 이 값으로 필터링하면 하나의 행만 남습니다.
그러나 이 경로를 다시 계산하면, 평균 값이 매우 약간 변경되었기 때문에 필터 후에 행이 더 이상 나타나지 않을 수 있습니다. 비결정적 열에서 정확한 필터 사용을 피하는 것이 좋습니다(예: 평균 = 40.5830495로 필터링). 또한 비결정적 열을 조인 키로 사용하는 것을 피하는 것이 좋습니다.
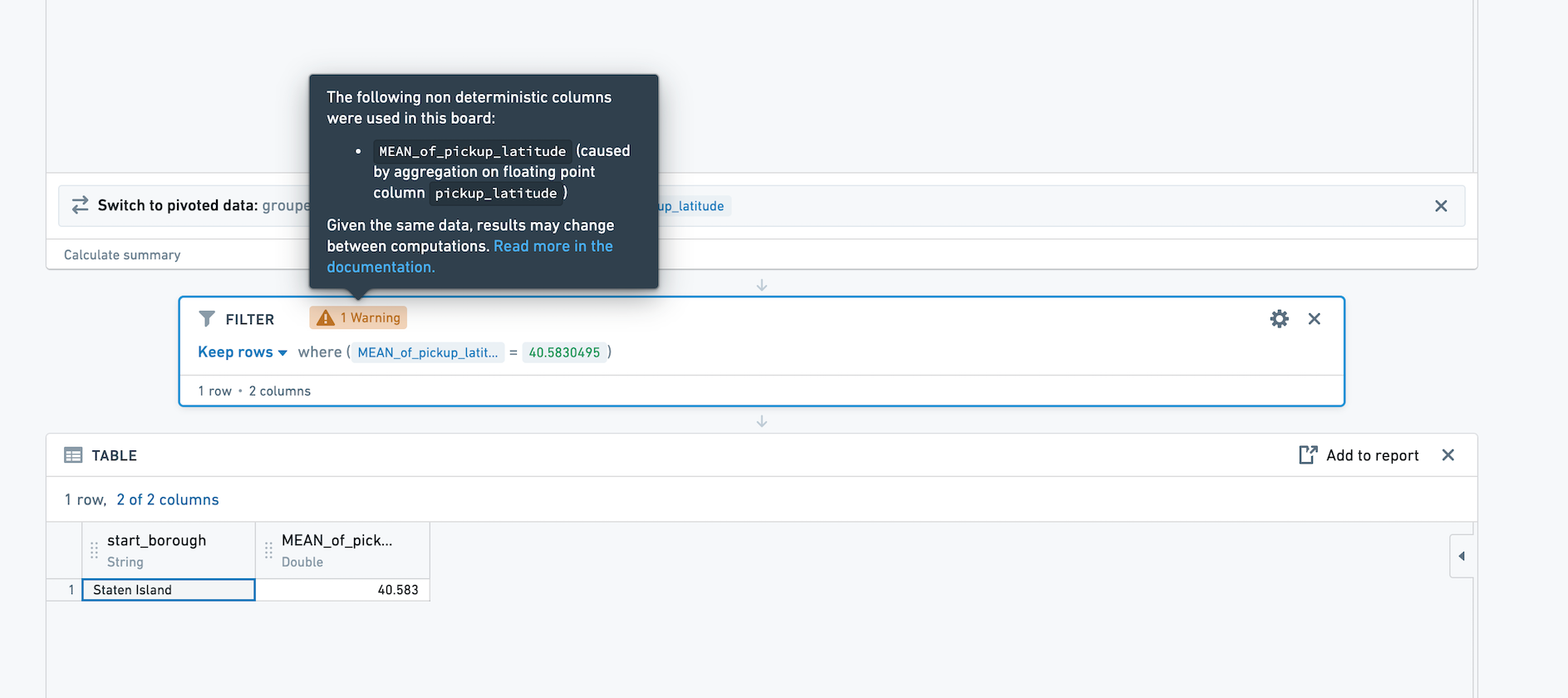
Contour에서 비결정적 열에서 작업을 수행할 때(예: 해당 열에 필터를 적용하는 경우), 작업이 수행되는 보드에서 경고가 표시됩니다. 경고는 비결정적 열의 원인이 되는 어떤 집계인지를 나타냅니다.
비결정성 진단
분석이 비결정적인지의 한 가지 신호는 일관되지 않은 행 수입니다. 예를 들어, 요약 보드를 삽입한 다음 행 수를 변경하지 않는 일련의 변환을 수행한 후 다른 요약 보드를 추가한 분석이 있다고 가정해 봅시다. 두 요약 보드의 행 수가 일치하지 않으면, 이전 경로에 비결정적 작업이 있는지 조사해야 합니다. 비결정적 함수를 사용하거나 이중 집계를 사용할 때 UI에서 경고 표시를 찾아보세요.