데이터셋 결합
Contour는 데이터셋 결합을 수행하기 위한 여러 가지 다른 보드를 제공합니다. 이 가이드에서는 (1) 데이터셋을 결합하기 위해 각 보드를 사용하는 방법, (2) 각 보드의 SQL 등가성, 및 (3) 성능 고려사항에 대해 알려드립니다.
Join 보드
Join 보드를 사용하면 현재 작업 중인 데이터셋을 다른 데이터셋과 결합하고, 일치하는 결과를 데이터에 병합할 수 있습니다. 개요는 다음과 같습니다.
예시
고객이 구매한 물품에 대한 정보가 있는 표가 있다고 가정합니다.
| customer_id | item_id | purchase_date | price |
|---|---|---|---|
| 101 | 999 | 1/1/2000 | 50 |
| 121 | 997 | 1/1/2000 | 35 |
| … |
재고의 모든 품목에 대한 정보가 있는 두 번째 표가 있을 수 있습니다.
| item_id | item | weight_kg |
|---|---|---|
| 999 | Toaster oven | 1 |
| 997 | Frying pan | 0.5 |
| … |
Join 보드를 사용하여 시작 데이터셋(transactions)에 구매한 각 품목에 대한 정보를 포함시킬 수 있습니다.
데이터셋에 동일한 이름의 열이 있는 경우, Contour는 열 이름에 접두사를 추가하도록 요청합니다. 이 경우, 두 데이터셋 모두 item_id 열을 가지고 있습니다. 들어오는 데이터셋의 열에 "inv"(inventory에 대한) 접두사를 적용합니다.
결과적으로 결합된 데이터셋에 중복된 item_id 열을 추가하고 싶지 않다면, 들어오는 데이터셋에서 해당 열의 선택을 취소할 수 있습니다.
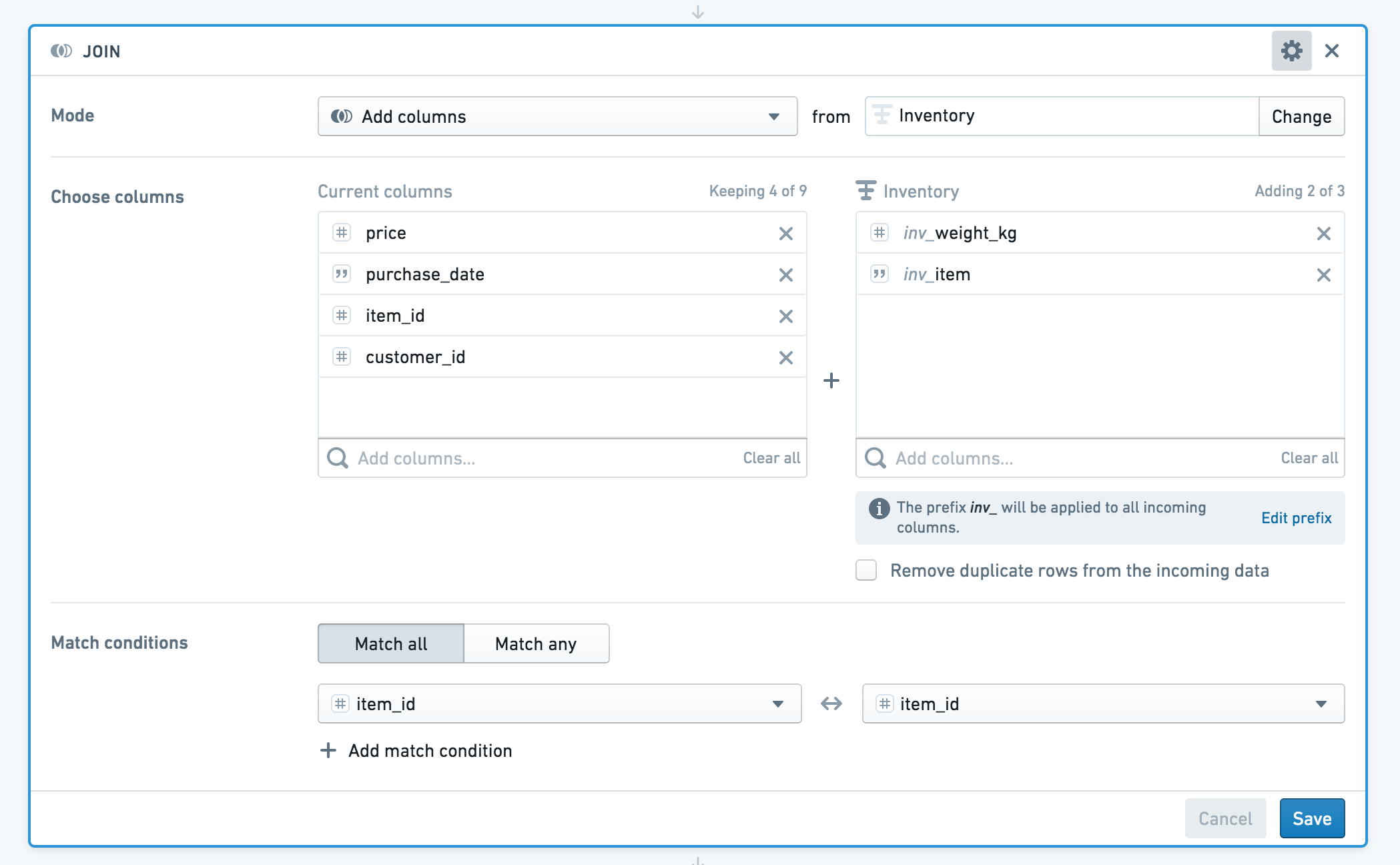
풍부한 데이터셋은 다음과 같이 표시됩니다:
| customer_id | item_id | purchase_date | price | inv_item | inv_weight_kg |
|---|---|---|---|---|---|
| 121 | 997 | 1/1/2000 | 35 | Frying pan | 0.5 |
| 101 | 999 | 1/1/2000 | 50 | Toaster oven | 1 |
| … |
Join 보드의 구성
수행할 결합 유형을 선택하세요: 왼쪽 결합(Add columns), 내부 결합(Intersection), 오른쪽 결합(Switch to dataset) 또는 완전 결합(Incorporate all data, matching rows where possible).
현재 작업 세트에 추가할 다른 데이터셋의 열을 선택합니다. 기본적으로 첫 번째 데이터셋의 모든 열이 반환됩니다.
그런 다음 각 세트에서 하나 이상의 키를 선택합니다. 여러 결합 키를 사용하는 경우 Match Any 또는 Match All 조건을 선택할 수 있습니다.
전체 결합의 경우 두 데이터셋의 모든 행이 반환되므로, 어느 쪽 데이터셋의 결합 열이든 null 값이 표시될 수 있습니다. 이는 두 열이 병합되지 않기 때문입니다.
Union 보드
Union 보드를 사용하여 현재 데이터셋을 기반으로 다른 데이터셋을 변경합니다. 다른 데이터셋에서 데이터를 추가(Add rows), 데이터셋을 필터링하여 다른 데이터셋에 존재하는 데이터만 유지(Keep rows)하거나 다른 데이터셋에 존재하는 데이터를 기반으로 데이터를 제거(Remove rows)할 수 있습니다. 열의 위치 또는 열 이름을 기준으로 일치시킬 수 있습니다.
구체적인 개념 예를 위해 다음 세 개의 표를 사용합니다.
people
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
candidates
| first_name | surname |
|---|---|
| Jess | Sage |
| Lee | Rose |
| Jamie | Wood |
candidates_backward
| last_name | first_name |
|---|---|
| Sage | Jess |
| Rose | Lee |
| Wood | Jamie |
사람들의 테이블이 있고, 이를 후보자의 두 테이블과 비교하고 싶습니다. 두 테이블 모두 people 테이블과 동일한 스키마를 가지고 있지 않습니다. 다음 섹션에서는 테이블에서 어떤 비교(집합 수학)를 수행하느냐에 따라 결과 세트가 어떻게 되는지 보여줍니다.
예시: 행 추가하기
people 테이블에서 시작하여 By name으로 candidates_backward 테이블에서 Add rows를 실행하면 결과 세트는 다음과 같습니다.
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
| Jess | Sage |
| Lee | Rose |
| Jamie | Wood |
people 테이블에서 시작하여 By position으로 candidates_backward 테이블에서 Add rows를 실행하면 결과 세트는 people 테이블에서 성(last names)을 가져와 candidates_backward 테이블에서 이름(first names)을 가져와 붙이게 됩니다. 이는 원하는 결과가 아닐 수 있습니다. 결과 세트는 다음과 같습니다.
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
| Sage | Jess |
| Rose | Lee |
| Wood | Jamie |
열 이름이 일치하지 않지만 첫 번째 이름과 성의 위치가 일치하기 때문에 people 테이블에서 candidates 테이블의 By postion으로 Add rows를 실행하려고 합니다. 시작 세트에서 열 이름이 가져온 것에 유의하세요.
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
| Jess | Sage |
| Lee | Rose |
| Jamie | Wood |
예시: 행 유지하기
people 테이블에서 시작하여 Union 보드를 구성하여 By position으로 candidates 테이블에서 Appear in을 사용하여 Keep rows를 실행하면 결과 세트는 다음과 같습니다.
| first_name | last_name |
|---|---|
| Jess | Sage |
| Lee | Rose |
people 테이블에서 시작하여 Union 보드를 구성하여 By name으로 candidates_backward 테이블에서 Appear in을 사용하여 Keep rows를 실행하면 결과 세트는 다음과 같습니다.
| first_name | last_name |
|---|---|
| Jess | Sage |
| Lee | Rose |
예시: 행 제거하기
people 테이블에서 시작하여 By position으로 candidates 테이블에서 Appear in을 사용하여 Remove rows를 실행하면 결과 세트는 다음과 같습니다.
| first_name | last_name |
|---|---|
| Casey | Linden |
| Taylor | Oak |
people 테이블에서 시작하여 By name으로 candidates_backward 테이블에서 Appear in을 사용하여 Remove rows를 실행하면 결과 세트는 다음과 같습니다.
| first_name | last_name |
|---|---|
| Casey | Linden |
| Taylor | Oak |
대신 people 테이블에서 시작하여 By position으로 candidates_backward 테이블에서 Appear in을 사용하여 Remove rows를 실행하면 결과 세트는 아래와 같습니다. 위치를 기준으로 candidates_backward 테이블에서 나타나는 행이 없기 때문에 이 테이블은 people 테이블과 동일합니다.
| first_name | last_name |
|---|---|
| Casey | Linden |
| Jess | Sage |
| Lee | Rose |
| Taylor | Oak |
Union 보드의 구성
Keep rows, Add rows 또는 Remove rows를 선택한 다음, 비교할 세트를 선택합니다.
Keep rows와 Remove rows의 경우 Appear in 또는 Match on 중 하나를 선택할 수 있습니다.
- Appear in을 사용할 때는 By position 또는 By name 중 하나를 선택할 수 있습니다.
- Match on을 사용할 때는 조인할 열을 지정해야 합니다(각 세트에서 한 열씩).
Union을 수행할 때 두 데이터셋은 동일한 열 개수를 가져야 합니다. 따라서 Union 보드를 사용할 때 스키마가 변경될 수 있는 경우 주의해야 합니다. 예를 들어, 피벗된 데이터로 전환된 피벗 테이블 하류의 유니온 보드는 스키마 변경으로 인해 열 개수의 예기치 않은 변경이 발생할 수 있습니다.
SQL 등가성
SQL에 익숙한 사용자의 경우 Contour 결합 작업을 SQL에서의 등가성과 비교하는 것이 도움이 될 수 있습니다. 다음 표는 어떤 보드에서 어떤 SQL 결합 유형이 지원되는지 보여줍니다:
Join
Join 작업은 SQL에서 다음과 동일합니다:
Copied!1 2 3 4SELECT [DISTINCT] <Column1, Column2, ...> -- 선택하려는 컬럼을 나열하세요 (중복 제거를 원하면 DISTINCT 사용) FROM CurrentTable -- 현재의 테이블 <INNER JOIN | LEFT OUTER JOIN | RIGHT OUTER JOIN | FULL OUTER JOIN > OtherTable -- 다른 테이블과 조인하려면 조인 종류를 선택하세요 (내부, 왼쪽 외부, 오른쪽 외부, 완전 외부) ON <join condition 1>([AND | OR] <join condition 2> [AND | OR] <join condition 3> ...) -- 조인 조건을 추가하고 필요한 경우 AND 또는 OR로 더 많은 조건을 연결하세요
유니온
행이 일치하는 항목 유지는 SQL에서 Left Semi Join과 같습니다:
Copied!1 2 3 4 5-- 다음 SQL 쿼리는 L 테이블과 R 테이블의 고유한 <join column>을 사용하여 내부 조인을 수행합니다. SELECT L.* FROM L INNER JOIN (SELECT DISTINCT <join column> FROM R) AS R_KEY -- L 테이블의 <join column>과 R_KEY 테이블의 <join column>이 일치하는 경우에만 결과를 반환합니다. ON L.<join column> = R_KEY.<join column>
일치하지 않는 행 제거는 조인 키가 일치하지 않는 SQL Left Outer Join과 동일합니다:
Copied!1 2 3 4 5 6 7 8-- L 테이블의 모든 열을 선택합니다. SELECT L.* -- L 테이블을 왼쪽에 두고 R 테이블과 왼쪽 외부 조인을 수행합니다. FROM L LEFT OUTER JOIN R -- L 테이블의 조인 열과 R 테이블의 조인 열이 동일한지 확인합니다. ON L.<join column> = R.<join column> -- 조건: R 테이블의 조인 열이 null 인 경우만 필터링합니다. WHERE R.<join column> is null
데이터 유형
결과 데이터셋을 검사하여 데이터 유형이 예상대로인지 확인하십시오.
유니온 보드를 사용할 때 열의 데이터 유형을 주의해야합니다. 호환되는 열 유형이 캐스팅됩니다. 구체적인 예를 들어 두 개의 데이터셋을 사용해보겠습니다.
dataset1
| ID (int) | Name (string) |
|---|---|
| 555 | Alice |
| 666 | Bob |
dataset2
| ID (long) | Name (string) |
|---|---|
| 555 | Alice |
| 999 | Chloe |
dataset1에서 시작하여 dataset2에서 위치별로 행 추가를 수행하면 결과 데이터셋은 다음과 같습니다:
| ID (long) | Name (string) |
|---|---|
| 555 | Alice |
| 666 | Bob |
| 555 | Alice |
| 999 | Chloe |
dataset1에서 시작하여 dataset2에 포함되는 행 유지를 수행하면 결과 데이터셋은 다음과 같습니다:
| ID (long) | Name (string) |
|---|---|
| 555 | Alice |
시작 데이터셋에서는 ID 열이 int 유형이지만 결과 데이터셋에서는 long 유형입니다. 포함되는 행 유지는 스파크의 Intersect function을 사용합니다.
dataset1에서 시작하여 dataset2에 포함되는 행 제거를 수행하면 결과 데이터셋은 다음과 같습니다:
| ID (long) | Name (string) |
|---|---|
| 666 | Bob |
다시 한 번, 시작 데이터셋에서는 ID 열이 int 유형이지만 결과 데이터셋에서는 long 유형입니다. 포함되는 행 제거는 스파크의 Except function을 사용합니다.
성능 고려사항
- 두 테이블을 결합하기 위한 키를 선택할 때 고유한 ID(기본 키와 같은)를 최대한 사용해야합니다. 외래 키 결합을 사용하는 것을 강력히 권장하지 않습니다 – 이렇게 하면 Spark가 중단됩니다.
- 복잡한 결합이나 표현식 후에 데이터셋으로 저장 기능을 사용하여 작업을 "저장"해야 합니다. 이렇게 하면 결합이 디스크에 저장되므로 하위 쿼리가 더 높은 성능을 발휘합니다.
결과 확인
데이터셋을 결합한 후에는 결합된 데이터셋의 테이블을 확인하여 결과가 예상대로인지 확인하는 것이 좋습니다. 액션 리본에서 표를 선택하여 테이블 보드를 추가하고 새로운 결합된 데이터셋을 스크롤하세요.