보드 설명
Contour에서의 탐색과 분석은 일련의 보드를 통해 수행됩니다. 일부 보드는 차트를 생성하거나 계산을 수행하며, 다른 보드는 데이터셋을 필터링하고, 열 제거 등으로 조작하는 데 사용됩니다.
이 요약 표의 링크를 사용하여 이 페이지의 보드 유형 간에 이동하세요.
| 보드 | 설명 | 시각화 | 행 필터링 | 집계 | 열 조작 | 중복 제거 |
|---|---|---|---|---|---|---|
| 요약 | 테이블의 행 수를 보고합니다. | 예 | 아니오 | 아니오 | 아니오 | 아니오 |
| 필터 | 숫자, 텍스트 또는 날짜 및 시간 값으로 데이터셋을 필터링합니다. | 아니오 | 예 | 아니오 | 아니오 | 예 |
| 표현식 | 표현식 언어를 사용하여 새 열을 도출하거나 복잡한 필터링을 수행합니다. | 아니오 | 예 | 아니오 | 예 | 아니오 |
| 표 | 원시 데이터의 일부분을 확인하고, 스키마를 탐색하고 데이터 커버리지 메트릭을 계산합니다. | 예 | 아니오 | 아니오 | 아니오 | 아니오 |
| 히스토그램 | 데이터의 히스토그램을 생성하고 특정 그룹으로 필터링합니다. | 예 | 예 | 예 | 예, Pivot 옵션을 통해 | 아니오 |
| 분포 | 데이터의 분포도를 생성합니다. | 예 | 예 | 아니오 | 아니오 | 아니오 |
| 시계열 | x축에 날짜/시간을 가진 차트를 생성하고 특정 그룹으로 필터링합니다. | 예 | 예 | 아니오 | 아니오 | 아니오 |
| 열 편집 | 열을 결합, 복제, 제거, 이름 변경 또는 분할합니다. | 아니오 | 아니오 | 아니오 | 예 | 아니오 |
| 데이터 변환 | 데이터를 익명화하거나 값을 찾아 바꾸거나 날짜를 분석합니다. | 아니오 | 아니오 | 아니오 | 예 | 아니오 |
| 차트 | 사용자 정의 가능한 다중 레이어 차트를 생성합니다. | 예 | 예 | 예 | 아니오 | 아니오 |
| 그리드 | 두 개의 범주형 열의 행렬을 생성합니다. 셀은 필터링할 수 있으며 히트맵으로 표시됩니다. | 예 | 예 | 아니오 | 아니오 | 아니오 |
| 히트맵 | 좌표 데이터를 기반으로 한 히트맵을 확인합니다. | 예 | 예 | 아니오 | 아니오 | 아니오 |
| 피벗 테이블 | 하나 이상의 메트릭에 대한 피벗 테이블을 생성합니다. | 예 | 예 | 예 | 예, Pivot 옵션을 통해 | 아니오 |
| 열 에디터 | 새로운 열을 도출하거나 필요하지 않은 열을 제거합니다. | 아니오 | 아니오 | 아니오 | 예 | 예 |
| 다중 열 에디터 | 열 이름 변경, 제거, 열 순서 변경 또는 데이터 중복 행 제거합니다. | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| Enrich | 또 다른 데이터셋으로 데이터를 풍부하게 하고 두 데이터셋에서 열을 반환합니다. | 아니오 | 아니오 | 아니오 | 예 | 예 |
| 링크 | 다른 데이터셋에 조인하고 해당 데이터셋의 일치하는 레코드를 반환합니다. | 아니오 | 아니오 | 아니오 | 예 | 예 |
| Set math | 외부 데이터셋을 기반으로 행을 유지, 추가 또는 제거합니다. | 아니오 | 예 | 아니오 | 아니오 | 아니오 |
| 조인 | 커레이션된 조인을 수행합니다. | 아니오 | 예 | 아니오 | 아니오 | 아니오 |
| 내보내기 | 최종 필터링된 관찰 세트를 CSV 또는 XLS로 내보냅니다. | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 열 순서 변경 | 테이블의 열 순서를 변경합니다. | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 매크로 | 템플릿화된 변환을 경로에 적용합니다. | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 정렬 | 하나 이상의 열을 기준으로 데이터 행을 정렬합니다. | 아니오 | 아니오 | 아니오 | 아니오 | 아니오 |
| 계산 | 여러 집계 계산을 표시합니다. | 예 | 아니오 | 예 | 아니오 | 아니오 |
| Unpivot | 일부 열을 행으로 변환하여 데이터를 재구성합니다. | 아니오 | 아니오 | 아니오 | 예 | 아니오 |
요약
요약 보드는 경로의 현재 위치에서 테이블의 행과 열 수를 표시합니다.
아직 데이터를 필터링하지 않은 경우, 이는 시작 세트의 행 수입니다. 히스토그램을 추가하고 특정 막대를 선택하는 등 필터를 적용한 경우, 이는 필터 후 남은 행 수입니다.
필터
필터 보드의 목적은 데이터셋에 사용자 정의 필터를 적용하는 것입니다. 분포, 히스토그램과 같은 다른 보드에서도 필터를 적용할 수 있지만, 필터 보드는 여러 변수가 포함된 더 복잡한 필터를 한 곳에서 구축할 수 있습니다.
필터 보드에서 목록을 사용하는 것은 SQL의 WHERE IN (x,y,z) 절과 유사합니다. Contour는 필터 보드에서 수천 개의 항목 목록을 처리할 수 있습니다. 그러나 큰 목록은 브라우저에 부담을 주고, 너무 큰 목록은 브라우저 실패를 초래할 것입니다. 이러한 경우, 목록을 별도의 세트로 Contour에 가져와서 링크 또는 세트 계산 보드를 사용하여 필터를 구현해야 합니다. 링크 또는 세트 계산 보드를 사용하는 방법을 알아보세요.
설정
필터 추가를 클릭하고, 필터링할 열을 선택한 다음 드롭다운에서 필터 유형을 선택합니다. 선택한 열에 따라, Contour는 적절한 범주의 필터(예: 숫자 값의 열에 대한 숫자)를 선택합니다.
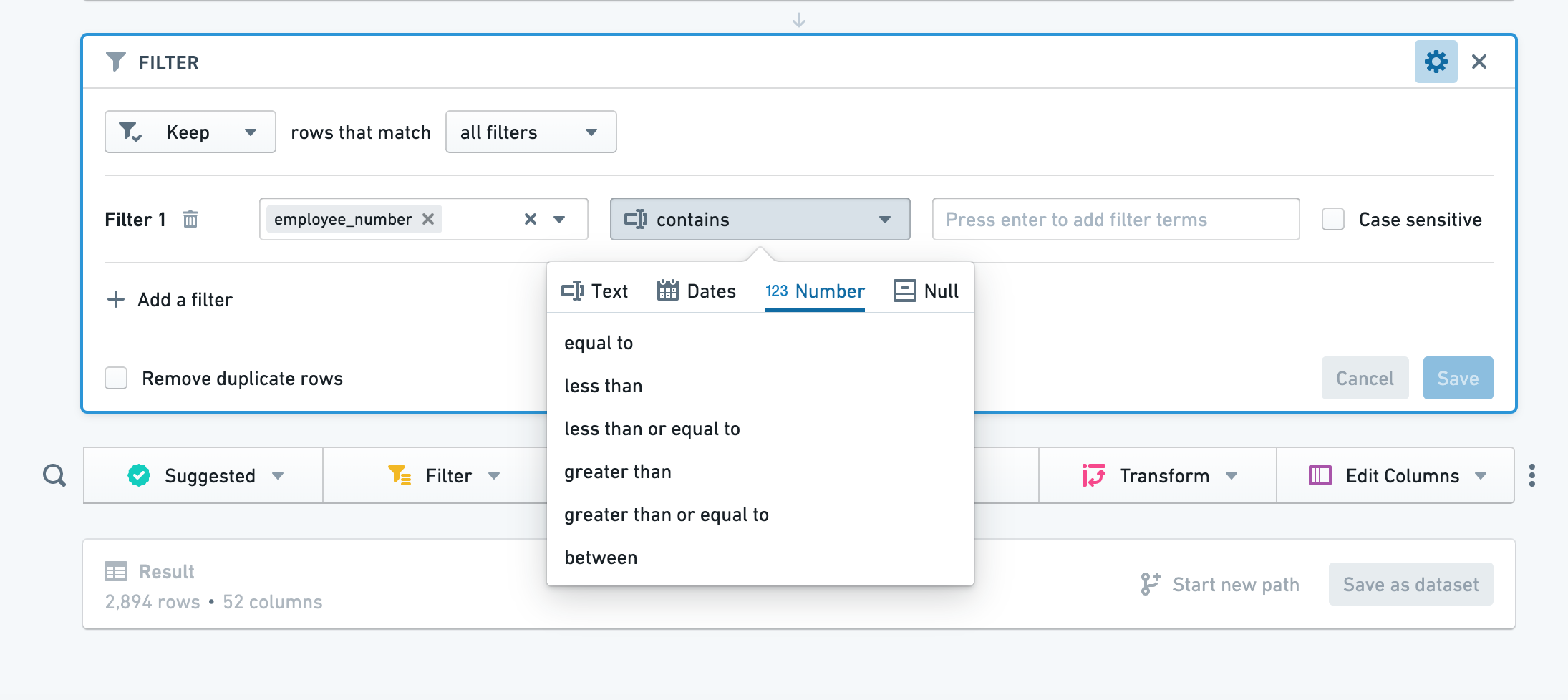
일부 텍스트 필터에서 와일드카드를 사용할 수 있습니다: *는 여러 문자로 대체될 수 있고, ?는 하나의 문자로 대체될 수 있습니다.
"일치"(정규 표현식) 텍스트 필터에서 정규 표현식을 직접 입력할 수 있습니다(따옴표 또는 문자열 지시자 없음).
필터를 추가하려면, 다시 필터 추가를 클릭하십시오. 모든 필터 또는 어떤 필터와 일치하도록 선택할 수 있습니다. 필터를 제거하려면 필터 옆에있는 휴지통 버튼을 클릭합니다. 필터를 적용하려면 저장을 클릭합니다.
텍스트 필터 상세
텍스트 필터에는 현재 다음 옵션이 제공됩니다:
- 포함: 검색어가 포함된 행을 반환합니다. 검색어는 텍스트만 포함해야 합니다. 예를 들어, "안녕"이라는 검색어는 "hi안녕hi"가 포함된 행과 일치합니다.
- 포함 (와일드카드 사용): 검색어가 포함된 모든 행을 반환합니다. 검색어에는
?를 사용하여 단일 문자 와일드카드를 나타내거나 *를 사용하여 여러 문자 와일드카드를 나타낼 수 있습니다. 예를 들어,h?l*o라는 검색어는 "hi hello hi" 또는 "hi halqqqqqo hi"와 일치합니다. - 일치: 검색어와 동일한 행을 반환합니다. 검색어는 텍스트만 포함해야 합니다. 예를 들어,
안녕이라는 검색어는 "안녕"과 일치하지만 "hi 안녕 hi"와는 일치하지 않습니다. - 일치 (와일드카드 사용): 검색어와 동일한 행을 반환합니다. 검색어에는 ?를 사용하여 단일 문자 와일드카드를 나타내거나 *를 사용하여 여러 문자 와일드카드를 나타낼 수 있습니다. 예를 들어,
h?l*o라는 검색어는 "hello" 또는 "halqqqqqo"와 일치합니다. - 일치: 검색어와 일치하는 행을 반환합니다. 검색어는 정규 표현식입니다. 이 옵션은 Java Pattern을 사용하여 정규 표현식을 평가합니다.
표현식
히스토그램 및 차트와 같은 시각 도구 외에도 Contour는 표현식 보드를 제공하여 Contour의 풍부한 표현식 언어를 사용하여 데이터에서 새로운 열을 도출하거나 복잡한 필터링을 수행하거나 복잡한 집계를 수행할 수 있습니다.
- 표현식 에디터를 사용할 때 ? 아이콘을 클릭하여 표현식 언어의 빠른 참조를 확인하십시오.
- 입력하면 드롭다운에 제안된 함수가 표시됩니다. 원하는 함수를 클릭하거나 Enter 키를 사용하여 선택합니다.
열 이름은 대소문자를 구분합니다. 또한, 열을 선택할 때 열 이름을 따옴표를 사용하거나 사용하지 않고 작성할 수 있습니다. 예를 들어, year("birthdate_col")은 year(birthdate_col)와 동일합니다. 일관성을 위해 이 문서의 열 이름은 따옴표를 사용하여 작성되었습니다.
표
표 보드는 데이터셋을 표 형식으로 보여줍니다. 데이터셋의 처음 limit(기본값: 1,000) 행만 표시됩니다. 이는 브라우저 성능 문제를 방지하기 위한 것입니다.
표 보드는 데이터가 예상대로 보이는지 확인하기 위해 데이터를 현장에서 확인하는 데 유용합니다. 표를 조작할 수 있습니다: 열을 드래그 앤 드롭하여 순서를 변경하거나 각 열의 드롭다운에서 선택할 수 있습니다. 표의 형식 변경은 기본 데이터에는 영향을 주지 않습니다(열의 하위 집합만 표시하는 경우, 기본 데이터에는 모든 열이 여전히 존재함).

Shift 키를 누른 채 여러 열을 선택하여 한 번에 여러 열을 이동할 수 있습니다. 또한 설정 패널을 사용하여 한 번에 여러 열을 수정할 수 있습니다.
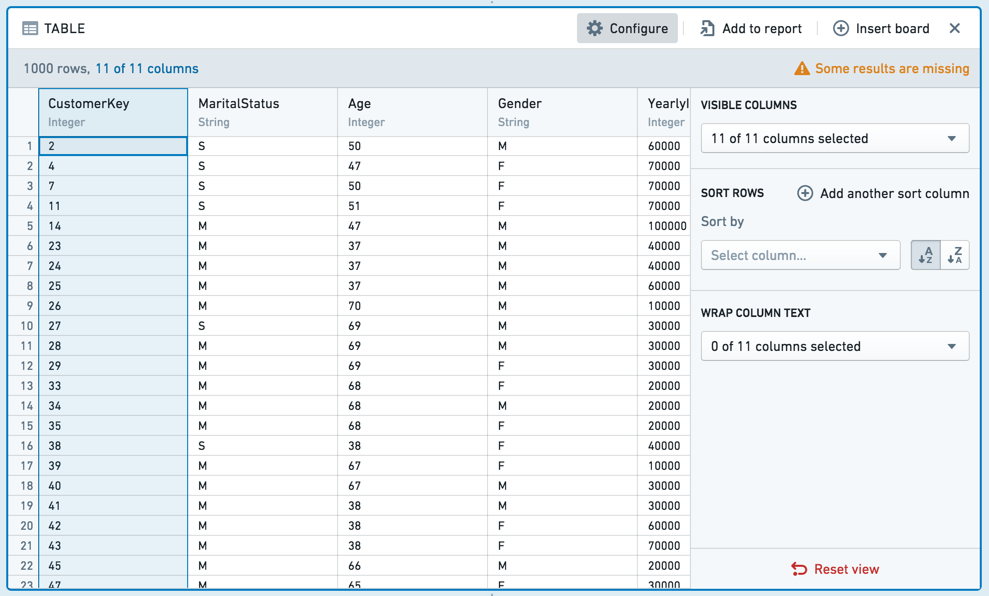
조건적 포맷팅
표 보드에 조건부 서식을 추가하려면 열 드롭다운을 클릭합니다.
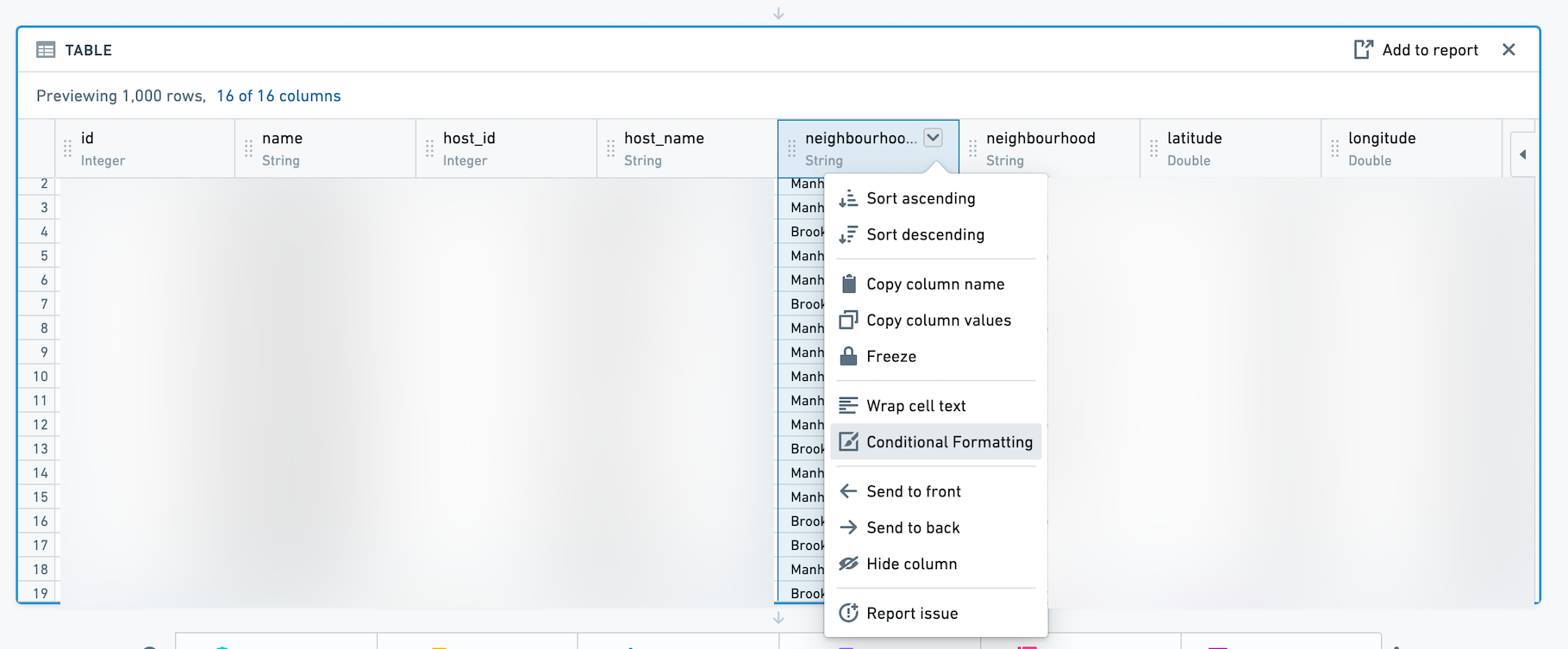
그런 다음 대화 상자를 사용하여 주어진 열에 대한 규칙을 추가합니다. 조건부 서식이 지정된 셀은 선택한 색상의 텍스트와 배경으로 표시됩니다. 규칙은 날짜 열에서는 지원되지 않습니다.
표 보드 대 표 패널
경로의 어느 지점에서도 표 보드를 추가하여 해당 시점의 데이터 미리보기를 빠르게 얻을 수 있거나, 경로보기에서 표 패널로 전환할 수 있습니다.
표 패널은 표(보드가 아닌)를 중심으로 놓고 데이터가 각 보드를 추가할 때 어떻게 변경되는지 확인할 수 있습니다. 이는 표현식을 작성할 때 특히 도움이 됩니다.
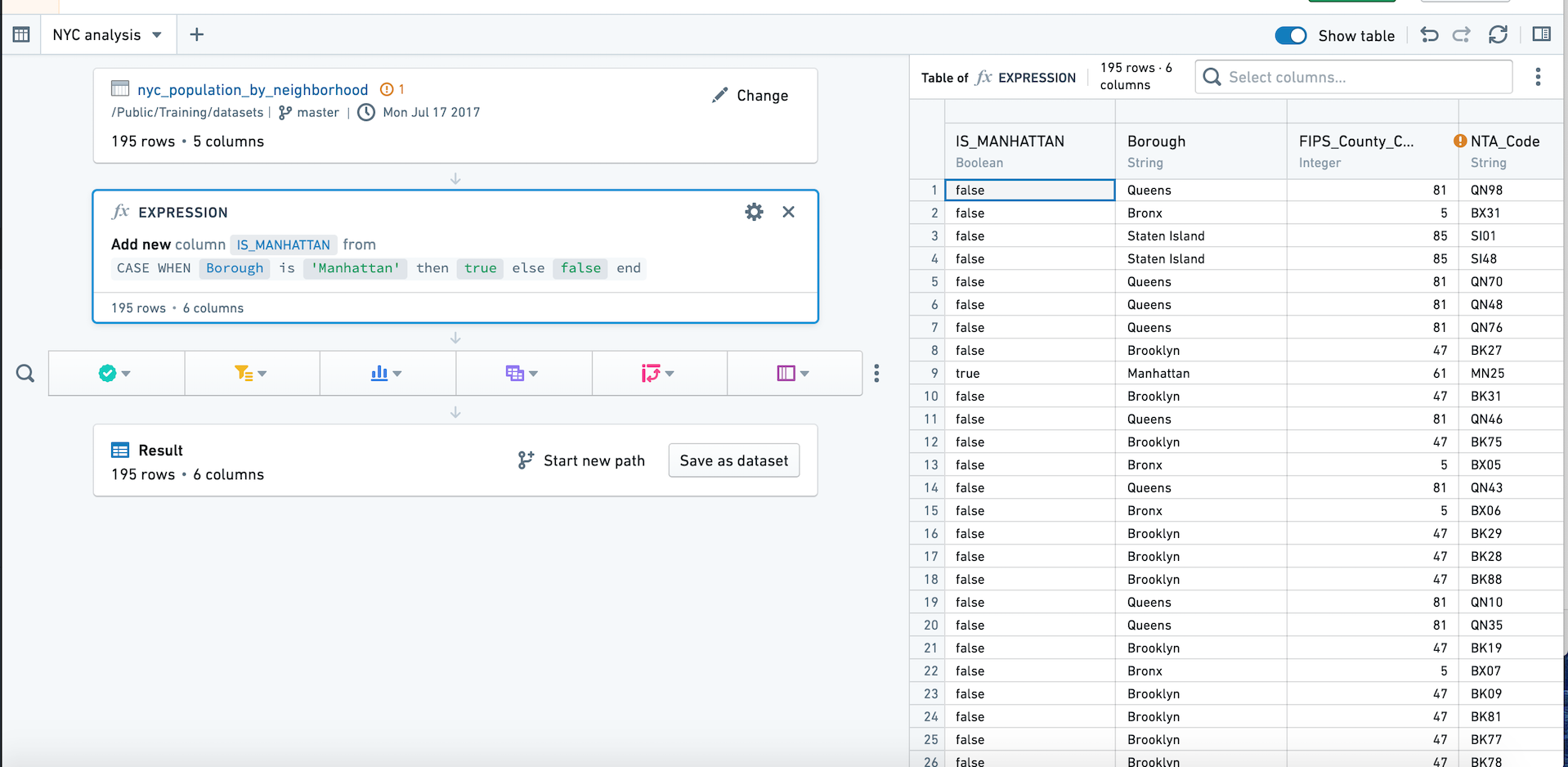
오른쪽 상단의 표를 클릭하여 표 패널로 전환할 수 있습니다. 다시 버튼을 클릭하거나 표 숨기기를 클릭하여 경로보기로 돌아갑니다.
표 패널은 조건적 포맷팅을 지원하지 않습니다.
히스토그램
히스토그램 보드는 주어진 열의 고유한 값들을 집계하고 결과를 막대 차트로 표시합니다.
예를 들어, 다음 히스토그램은 뉴욕의 어느 이웃에서 시작된 택시 탑승 거리의 평균을 계산합니다.
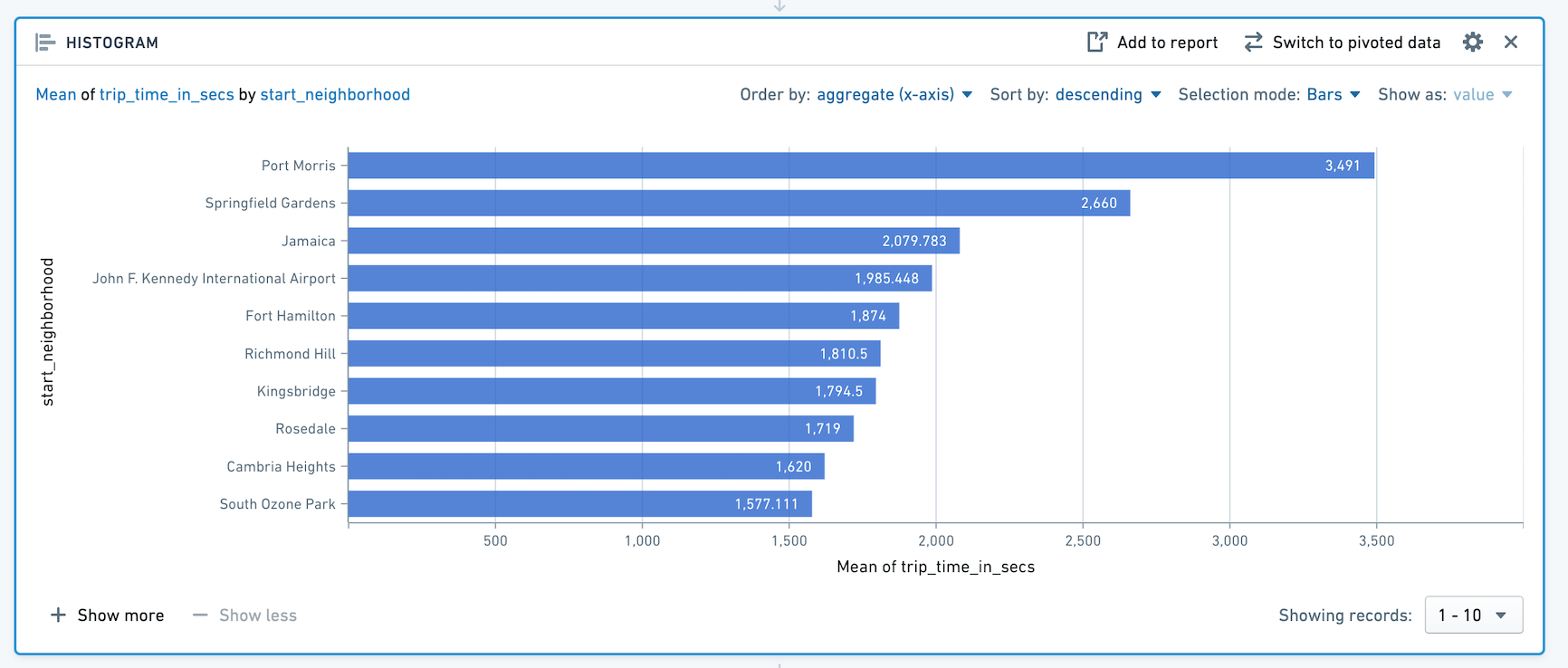
참고로 상위 10개의 막대만 표시됩니다. 더 많은 막대를 표시하려면 + 더 보기를 클릭하세요. 한 번에 최대 50개의 값을 표시할 수 있습니다. 50개 이상의 값이 있는 경우, 드롭다운을 사용하여 범위의 다른 부분으로 이동하세요.
SQL 동등
히스토그램 보드는 SQL GROUP BY 절의 시각화입니다.
위의 예제 히스토그램은 다음 SQL 쿼리와 동일합니다:
Copied!1 2 3SELECT start_neighborhood, mean(trip_time_in_secs) -- 시작 지역과 해당 지역의 평균 여행 시간(초)을 선택합니다. FROM <table name> -- 여기에는 테이블 이름을 입력해야 합니다. GROUP BY start_neighborhood -- 시작 지역별로 그룹화합니다.
설정
- Y-축
- 데이터를 그룹화할 열을 선택합니다. 이 열의 이산 값에 기반하여 데이터가 그룹화되고, 그 후에 집계가 계산됩니다.
- X-축
- 계산할 집계를 선택하고, 집계가 Count가 아닌 경우에는 적용할 열을 선택합니다.
- 집계
- 사용 가능한 집계 메트릭은 다음과 같습니다: Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. median, Standard Deviation, 그리고 Variance.
- Count를 제외하고는 집계가 적용되는 열을 지정해야 합니다. Unique Count의 경우, 어느 열이든 선택할 수 있습니다.
- Min, Max, Sum, Mean, Approx. Median, Standard Deviation, 그리고 Variance는 숫자 열에만 적용됩니다.
- 집계는 Y-축으로 선택된 열의 각 고유 값에 대해 계산됩니다.
- 사용 가능한 집계 메트릭은 다음과 같습니다: Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. median, Standard Deviation, 그리고 Variance.
Approx. Median 집계는 대략적입니다. Contour는 퍼센트 값 0.5와 기본 정확도로 percentile_approx 함수를 호출합니다.
Pivoted Data로 전환
Pivoted Data로 전환을 클릭하면, 히스토그램 이후에 추가하는 모든 보드는 원래 데이터셋 대신 표에서 계산된 집계 데이터를 사용합니다.
새 데이터셋에는 원래 히스토그램 설정에서 Y-축에 선택한 열과 집계를 위한 열이 포함됩니다. 예를 들면:
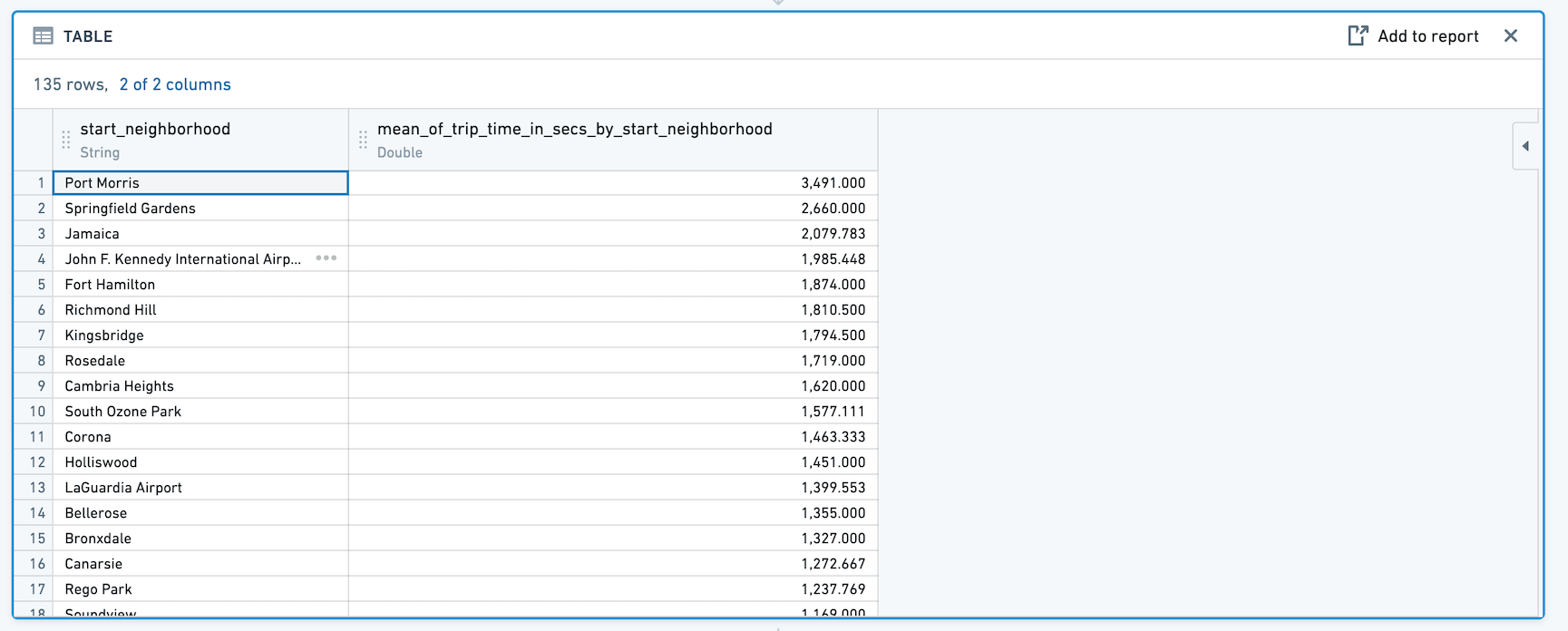
정렬
히스토그램은 기본적으로 집계를 내림차순으로 정렬합니다. 매우 큰 히스토그램의 경우, 정렬은 집계의 최고 값 1,000개에 대해 수행됩니다.
드롭다운을 사용하여 Y-축 열 값으로 정렬하거나 정렬 방향을 변경할 수 있습니다.
필터링
히스토그램에서 데이터를 선택하여 미래 보드의 데이터셋을 필터링합니다.
선택 모드:
- Y-축으로 선택한 열의 하나 또는 여러 개의 고유 값을 필터링하기 위해 Bar를 선택합니다.

- 집계 값으로 필터링하기 위해 Range를 선택합니다. 예를 들어, 특정 임계값 이상의 값을 가진 카테고리만 선택하기 위해 Range 선택을 사용할 수 있습니다.

그런 다음 Keep를 선택하여 선택된 값 만 필터링하거나, Remove를 선택하여 선택되지 않은 값만 유지합니다.

분포
분포 보드는 집계 메트릭에 대한 수치 변수의 분포를 표시합니다.
분포 보드는 히스토그램과 유사하지만, 특정 값이 아닌 값의 범위에 기반한 집계 데이터를 표시합니다. 예를 들어, 다음 분포는 고객의 연령에 대한 데이터를 표시합니다. 연령은 열 개의 범위 (또는 "버킷")로 나누어집니다.
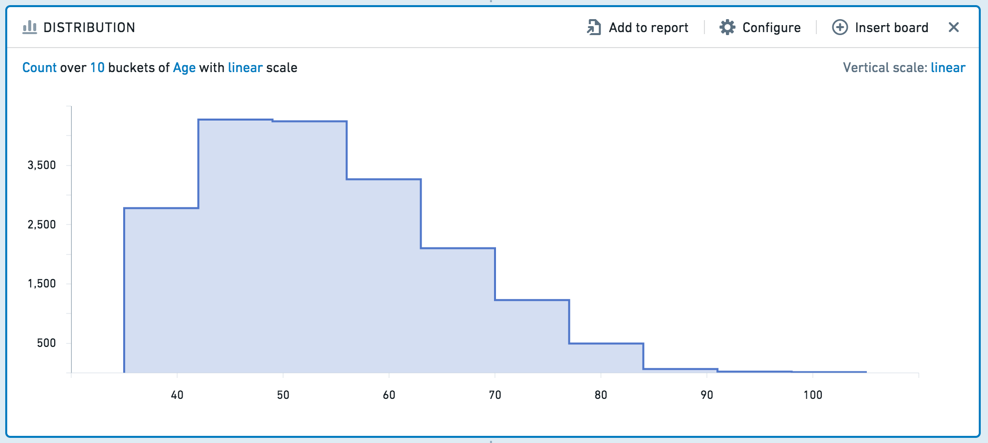
SQL 동등
분포 보드를 계산할 때, 먼저 X-축의 최소값과 최대값을 찾고 버킷을 계산하는 함수를 생성합니다. 그런 다음 분포의 SQL 동등은 대략 다음과 같습니다:
Copied!1 2 3 4 5 6 7 8-- X_AXIS_BUCKET_FUNCTION을 사용하여 [x-axis-column]을 선택합니다. SELECT X_AXIS_BUCKET_FUNCTION([x-axis-column]), -- <AGGREGATE_METRIC>를 사용하여 [aggregate-column]을 집계합니다. <AGGREGATE_METRIC>([aggregate-column]) -- <PARENT_BOARD>로부터 데이터를 가져옵니다. FROM <PARENT_BOARD> -- X_AXIS_BUCKET_FUNCTION([x-axis-column])에 따라 그룹화합니다. GROUP BY X_AXIS_BUCKET_FUNCTION([x-axis-column])
구성
- X축
- 숫자 값 열을 선택합니다. 이 열의 값은 동일한 너비 범위로 그룹화되며(다시 말해 데이터가 10, 100, 1000 개의 "버킷"으로 균등하게 나뉩니다), 그런 다음 집계가 적용됩니다. 이 축의 스케일(선형 또는 로그)도 구성할 수 있습니다.
- Y축
- 각 범위에 계산할 집계 메트릭을 선택합니다.
- 사용 가능한 집계 메트릭은 다음과 같습니다: Count(레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. Median, Standard Deviation, Variance. Count를 제외하고는 집계가 적용되는 열을 지정해야 합니다.
- Y축의 스케일도 구성할 수 있습니다(선형 또는 로그).
- 각 범위에 계산할 집계 메트릭을 선택합니다.
Approx. Median 집계는 근사값입니다. Contour는 percentile_approx 함수를 백분율 값 0.5와 기본 정확도로 호출합니다.
필터링
필터링할 범위를 선택하려면 차트에서 원하는 간격을 클릭하여 드래그합니다.
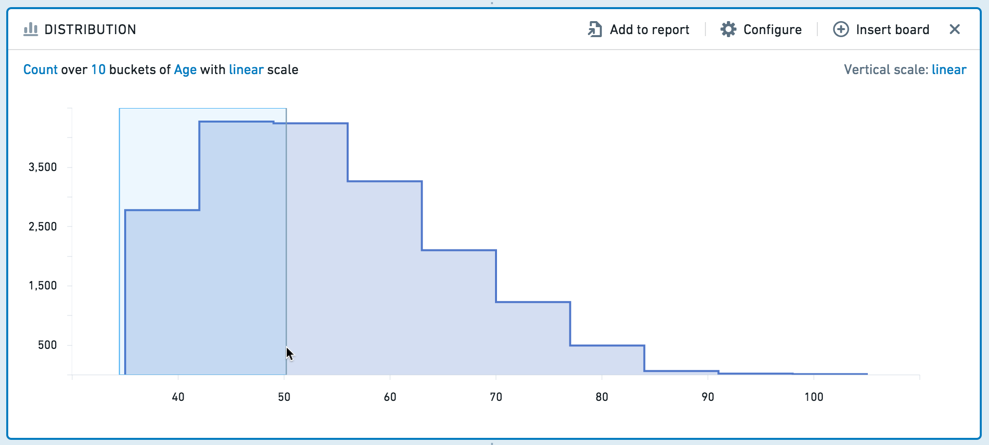
그런 다음 편집 가능한 보드 바닥글에서 간격을 더 정확하게 조정할 수 있습니다.
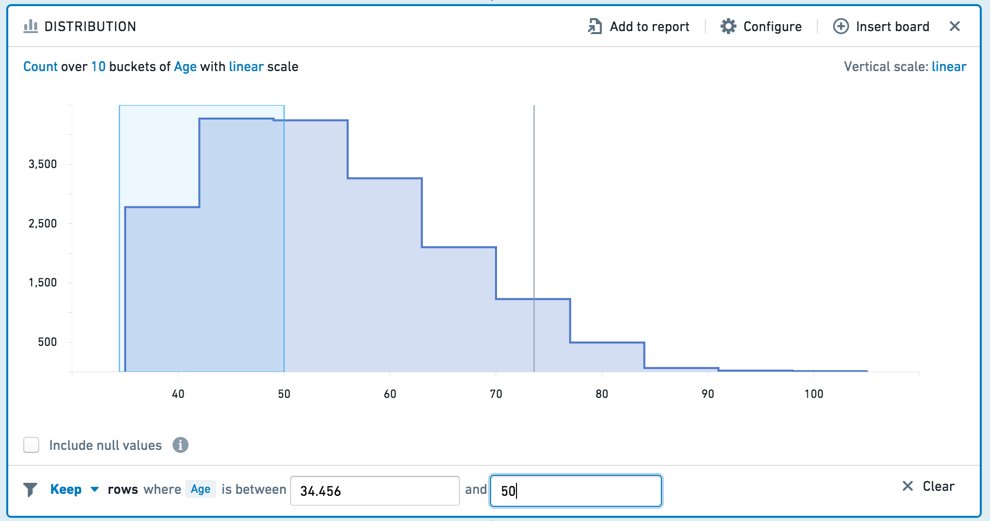
선택한 간격의 값들을 Keep하거나, 선택하지 않은 값들만 유지하려면 해당 값을 Remove할 수 있습니다. 선택을 지우려면 Clear 버튼(x)을 클릭하십시오.
시계열
시계열 보드를 사용하면 데이터를 시간 간격별로 그룹화하고 해당 데이터에 대한 집계 메트릭을 계산할 수 있습니다.
예를 들어, 고객의 개인 정보에 대한 데이터셋이 주어진 경우 다음 시계열 보드는 각 연도별 출생 인원수를 계산합니다.

series로 사용할 열을 추가로 지정할 수 있습니다. 위 예시에서는 성별을 series로 사용할 수 있습니다. 시계열 보드는 이제 series 열의 각 값에 대한 선이 하나씩 나눠집니다. 이 경우 F(여성) 또는 M(남성)입니다.

시계열은 전체 데이터셋을 기준으로 집계를 수행하며, 출력 결과를 표시할 때 처음 1000개 값으로 축소합니다.
구성
- X축
- 데이터를 시간적으로 그룹화하기 위해 DateTime 열을 선택합니다. 그런 다음 시간 단위를 선택하십시오. 데이터는 해당 길이의 간격으로 그룹화됩니다. 사용 가능한 단위는 다음과 같습니다: Second, Minute, Hour, Day, Week, Month, Year.
- 집계
- 각 시간 간격에 적용할 집계를 정의합니다.
- 사용 가능한 집계 메트릭은 다음과 같습니다: Count(레코드 수), Unique Count, Min, Max, Sum, Mean, Standard Deviation, Variance.
- Count를 제외하고는 집계가 적용되는 열을 지정해야 합니다. Unique Count의 경우, 어떤 열이든 선택할 수 있습니다.
- Min, Max, Sum, Mean, Approx. Median, Standard Deviation, Variance는 숫자 열에만 적용됩니다.
- Series
- 데이터를 시리즈로 나눌 열을 선택합니다. 열의 이산 값에 대해 하나의 시리즈(차트에서 선으로 표시됨)가 생성됩니다.
Approx. Median 집계는 근사값입니다. Contour는 percentile_approx 함수를 백분율 값 0.5와 기본 정확도로 호출합니다.
필터링
시계열에서 날짜 범위를 선택하여 데이터셋을 필터링해야 하는 경우가 있습니다.  를 클릭한 다음 원하는 간격을 클릭하여 드래그하십시오. (편집 가능한 보드 바닥글에서 간격을 더 정확하게 조정할 수 있습니다.) 선택을 지우려면
를 클릭한 다음 원하는 간격을 클릭하여 드래그하십시오. (편집 가능한 보드 바닥글에서 간격을 더 정확하게 조정할 수 있습니다.) 선택을 지우려면  아이콘을 클릭하십시오.
아이콘을 클릭하십시오.
드롭다운에서 Keep을 선택하여 선택한 값만 필터링하거나, Remove를 선택하여 선택하지 않은 값만 유지하십시오.

열 편집
Contour에서 다음 보드를 사용하여 열을 편집할 수 있습니다:
- 두 개 이상의 열을 Combine 합니다.
- 열을 Duplicate(예: 원본 데이터에 영향을 주지 않고 해당 열에서 작업을 시도하기 위해)합니다.
- 테이블에서 열을 Remove 합니다.
- 열의 이름을 Rename 합니다.
- 구분 문자를 기준으로 열을 Split 합니다.
데이터 변환
다음 보드를 사용하여 열의 데이터를 변환할 수 있습니다:
Obfuscate
- Hashing 셀 값(예: 이름과 같은 민감한 데이터를 숨기기 위해). 열의 각 값은 SHA-1 해시 함수를 사용하여 값의 해시된 표현으로 바뀝니다.
SHA-1 해시는 해독할 수 있으며 완전히 안전하지 않다고 간주됩니다. 따라서 데이터 준수 목적으로 사용해서는 안 됩니다.
- 값의 일부 문자 수를 Masking(예: 전화번호의 마지막 2자리를 제외한 모든 것을 마스킹)합니다.
- K-anonymizing 데이터의 특정 필드를 "억제"함으로써 데이터셋에 적용할 임계값(
k)을 설정하여 개인 식별 가능 정보가 없어도 재식별 위험을 줄이려는 개인 정보 보호 기술입니다. 이 과정은 출처를 밝히는 데 도움이 될 수 있는 특정 필드를 "억제"하는 것입니다.
사용 사례에 적합한 k 값은 컨텍스트에 따라 결정됩니다. 조직은 일반적으로 분석 컨텍스트와 재식별 통계적 위험을 기반으로 k 값을 설정하는 정책을 설정합니다. 일부 예제 정책은 National Center for Education Statistics 및 U.S Department of Health & Human Services가 있습니다. 최소한 k 값은 항상 1보다 크고 데이터셋의 행 수보다 작아야 합니다.
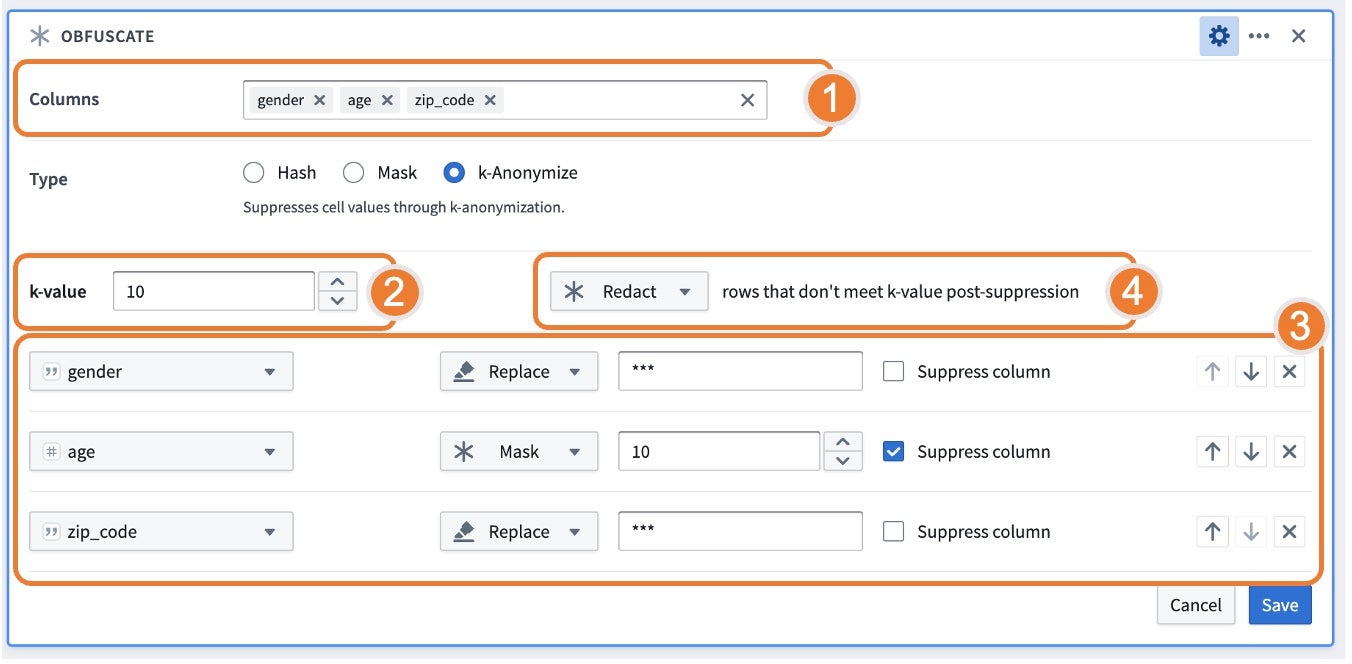
k-anonymize 기능을 사용하면 k-anonymize할 열, k 값 목표, 억제 전략을 선택하고 억제 후 k 값에 도달하지 않는 행을 처리하는 방법을 묻습니다.
-
Columns: 개인을 고유하게 식별하는 외부 데이터와 연결할 수 있는 "준 식별자" 또는 속성을 나타냅니다.
-
k-value: 같은 민감 정보 집합을 가진 인스턴스가 최소
k개 이상 있는 임계값k를 나타냅니다. -
Strategies: 억제 방법과 순서를 나타냅니다. 지정된 작업 순서를 설정하여 k 값에 도달할 수 있습니다. 나열된 각 열에 대해 k 값에 도달하기 위해 데이터에 적용되는 다양한 전략 중에서 선택할 수 있습니다:
- Bucket: 정수를 범위로 대체합니다. 숫자 유형 열이 선택되었을 때만 사용 가능합니다.
- Mask: 마지막 n개 문자를 *로 대체합니다.
- Replace: 전체 값을 문자열로 대체합니다. 기본 동작은
***을 대체 값으로 제안하지만, 사용자가 제공하는 값으로 대체할 수 있습니다. - Suppress Column 플래그가 있는 열은 k 값에 도달하더라도 전략이 모든 값에 적용됩니다. 이 동작은 특히 모든 값에 대해 일관된 버킷화 전략이 유용한 연령 버킷화와 같은 경우에 관련됩니다.
-
억제 후 k 값에 도달하지 않는 행: 일부 행이 k 값 임계값에 도달하지 못하고
k보다 큰 카운트로 억제할 수 없는 경우 다음 옵션이 사용 가능합니다:- Keep: 데이터가 손실되지 않도록 행을 유지합니다. 이러한 행을 유지하면 데이터셋이 k-anonymized 되지 않습니다. k-anonymization 결과를 검토하는 데 유용한 단계입니다.
- Drop: k 값에 도달하지 않는 모든 행을 제거합니다. 삭제를 선택할 때는 은닉화 전후 행 수를 계산하여 삭제된 행 수를 파악하십시오.
- Redact: 테이블의 모든 값을
***로 은폐합니다. 이 옵션은 행 수를 동일하게 유지하려는 경우에 특히 관련이 있습니다.
-
Find and replace 열 내 텍스트를 찾거나 비어 있는 또는 null 셀을 찾습니다. 이 보드는 String 또는 Numeric 유형의 속성을 지원합니다.
-
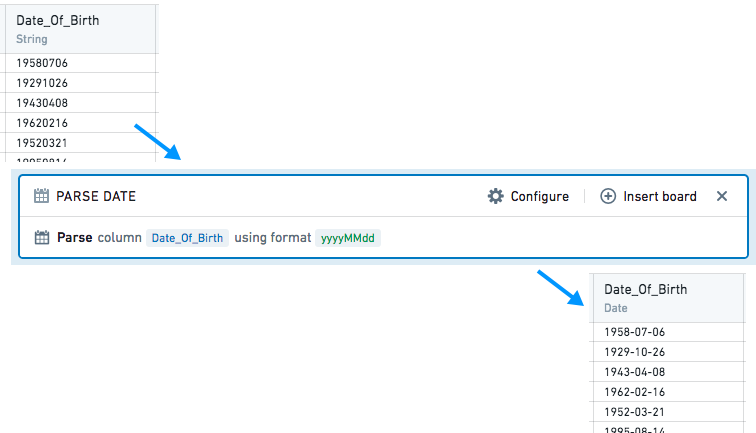
문자열에서 날짜를 Parse 합니다.
차트
Contour 차트 보드를 사용하면 데이터 분석을 위해 사용자 정의 차트를 작성할 수 있습니다.
구성
주 차트 레이어에 대한 차트 유형을 선택한 다음 x축과 y축을 구성합니다. 현재 차트 보드는 다음 유형의 차트를 제공합니다:
Bar
Horizontal Bar
Line
Scatter
Heat Grid
Pie

Segment by
Heat grid 및 pie를 제외한 차트 유형의 경우 데이터를 시리즈로 분할할 수도 있습니다.
정렬
Options 섹션을 펼쳐 차트 데이터 정렬 방식을 변경할 수 있습니다. 주 레이어의 값에 따라 차트 데이터를 정렬할 수 있습니다.
- X 값
- Y 값
- 사용자 정의 열 값. 이 정렬 값은 데이터셋의 어떤 열(차트에 표시되지 않은 열도 포함)이 될 수 있습니다.
다음 예는 올림픽에서 국가별 금메달 수에 따라 막대 차트를 정렬합니다.
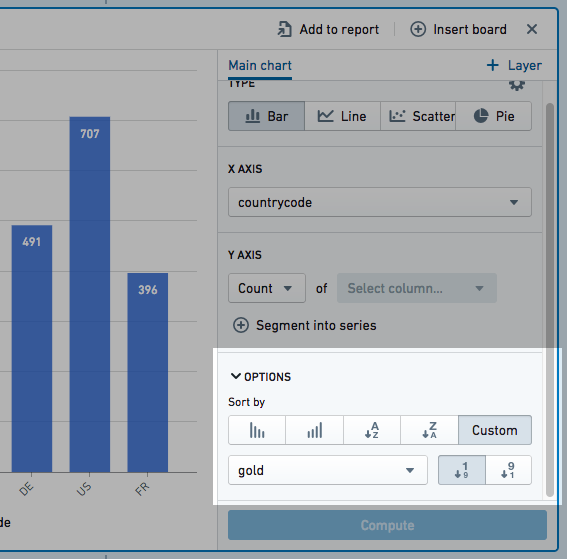
데이터는 오름차순 또는 내림차순으로 정렬됩니다. 오버레이 플롯 값은 차트 데이터 정렬에 사용할 수 없습니다.
포맷 설정
포맷 탭을 사용하여 차트를 구성합니다. X축 및 Y축 제목, 축의 형식, 범례 위치, 시리즈 정렬 및 시리즈 색상을 변경할 수 있습니다.
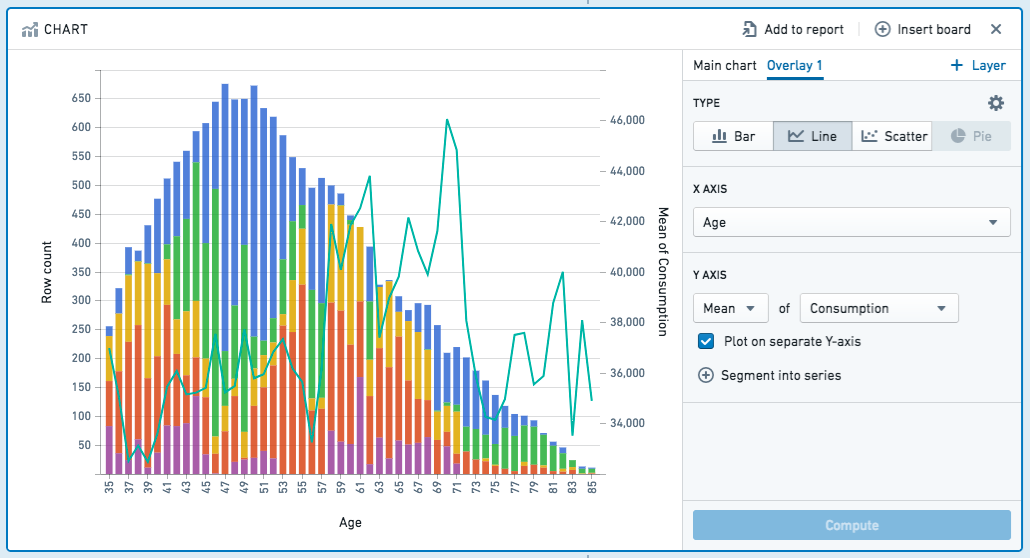
오버레이 추가
+ Add Overlay를 클릭하여 오버레이 플롯을 추가할 수 있습니다. 예를 들어, 막대 차트 위에 선 차트를 오버레이하려는 경우가 있습니다.
오버레이를 추가할 때 차트가 현재 경로의 데이터를 사용할 것인지 다른 데이터셋에서 사용할 것인지 선택할 수 있습니다.
다른 데이터셋에서 데이터를 플로팅하면 작업 세트와 조인되지 않습니다. 데이터셋을 조인하려면 Join board를 사용하십시오.
주 차트 레이어만 데이터 경로의 일부입니다. 다른 레이어는 전적으로 표시 목적으로 사용됩니다. 즉, 오버레이 레이어에서 선택하거나 데이터를 다른 방식으로 조작하면 데이터 경로의 하류에 영향을 주지 않습니다.
개별 레이어의 값이 관련이 없거나 데이터 범위 또는 플롯 스케일이 크게 다른 경우 차트 레이어를 별도의 y축에 플로팅할 수 있습니다.
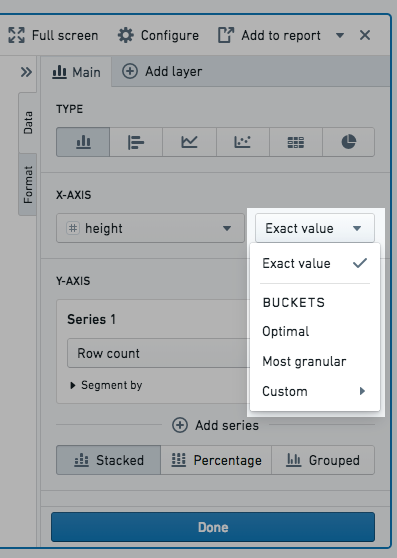
Bucket 선택
Group by 열(예: x축) 및 Segment by 열을 구성할 때 데이터 포인트를 어떻게 버킷화할지 선택할 수 있습니다. 숫자, 날짜 또는 시간 열만 버킷화할 수 있습니다. 예를 들어 막대 차트를 만들고 x축 Group by 열로 날짜 열을 선택한 다음 버킷 유형 Year를 선택하면 결과 차트에는 매년 막대가 표시됩니다. 사용 가능한 버킷 유형은 아래에 나열되어 있습니다.
숫자 열 버킷 유형:
- Exact value: 데이터가 버킷화되지 않고 정확한 값이 표시됩니다.
- Optimal: 버킷 수는 기본 데이터 범위 내의 점의 제곱근과 같습니다. 데이터 범위는 열의 최대값과 최소값의 차이입니다.
- Most granular: 차트가 Result limit 내에 들어갈 수 있는 최대 버킷 수를 사용합니다. 가능한 경우 정확한 값을 사용합니다.
- Custom: 버킷 수를 수동으로 선택할 수 있습니다. 버킷 수는 Result limit보다 클 수 없습니다.
날짜 및 시간 열 버킷 유형:
- Exact time: 데이터가 버킷화되지 않고 정확한 값이 표시됩니다.
- Rounding: 데이터가 선택한 Second, Minute, Hour, Day, Week, Month, Year 중 가장 가까운 값으로 버킷화됩니다. 예를 들어, Year로 버킷화하는 경우 2018년 6월 15일의 데이터 포인트는 2018년 버킷으로 버킷화됩니다.
- Ordinals: 데이터가 순위 날짜로 버킷화됩니다. 예를 들어, Day of week를 선택한 경우, 데이터는 주중 각 요일에 대한 버킷으로 버킷화됩니다.
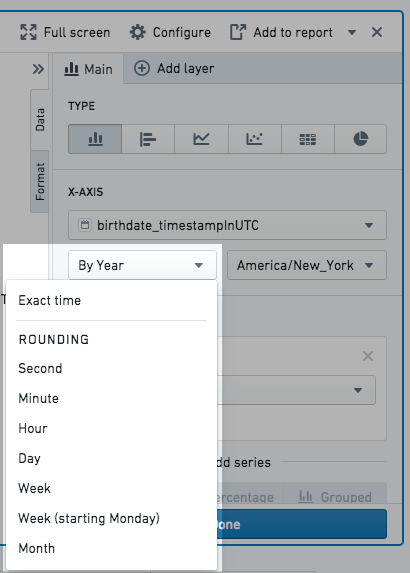
버킷 선택이 결과 제한에 맞지 않으면 결과가 손실되지 않도록 가장 세분화된 옵션이 적용됩니다. Result limit에 대한 자세한 정보를 읽어보십시오.
결과 제한
Contour는 브라우저에 표시되는 데이터 포인트 수에 제한을 둡니다. 실제로 말하면, Contour는 화면에 있는 픽셀 수보다 더 많은 데이터 포인트를 표시할 수 없습니다. 정확한 차트를 만들고 데이터를 삭제하지 않기 위해 차트 보드는 차트 구성을 결과 제한에 맞게 가장 세분화된 버킷 선택으로 다시 버킷화합니다.
결과 제한은 Palantir 관리자에 의해 설정되며 기본값은 1000개의 포인트입니다. 숫자, 날짜 또는 시간 열에 대해 다시 버킷화가 수행됩니다.
다시 버킷화를 설명하기 위해 다음 예를 고려하십시오:
- 출생 날짜가 포함된 데이터셋에서 차트 보드가 생성됩니다.
- 보드가 출생일 열을 기준으로하는 사람 수를 계산하는 막대 차트로 구성됩니다.
- 출생일 열은 초 단위로 날짜를 지정하므로 Second 버킷 유형이 선택됩니다.
- 이 데이터셋에서 초별 고유 출생일 수가 결과 제한을 초과합니다.
- 따라서 계산 시 차트 보드는 Second 대신 Hour 단위로 데이터를 자동으로 버킷화하며, 이는 결과 제한에 맞는 이 특정 데이터셋의 가장 세분화된 버킷 크기입니다.
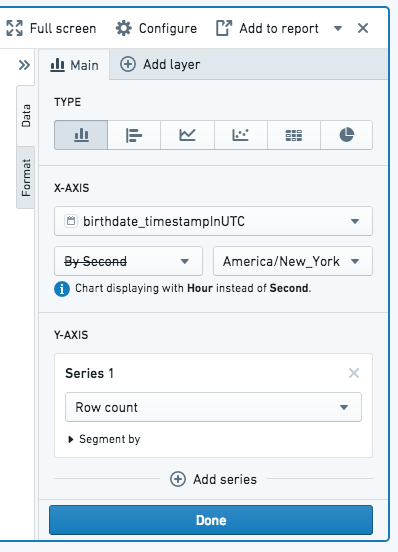
필터링
차트에서 데이터를 선택하여 향후 보드용 데이터셋을 필터링합니다. 다중 선택을 위해 Ctrl+Click 또는 Cmd+Click을 사용합니다.
차트에서 팬 및 줌을 사용하여 데이터를 더 쉽게 볼 수 있습니다. 차트의 막대 또는 포인트 위로 마우스를 가져가면 툴팁이 표시되어 보고 있는 내용을 강조합니다.
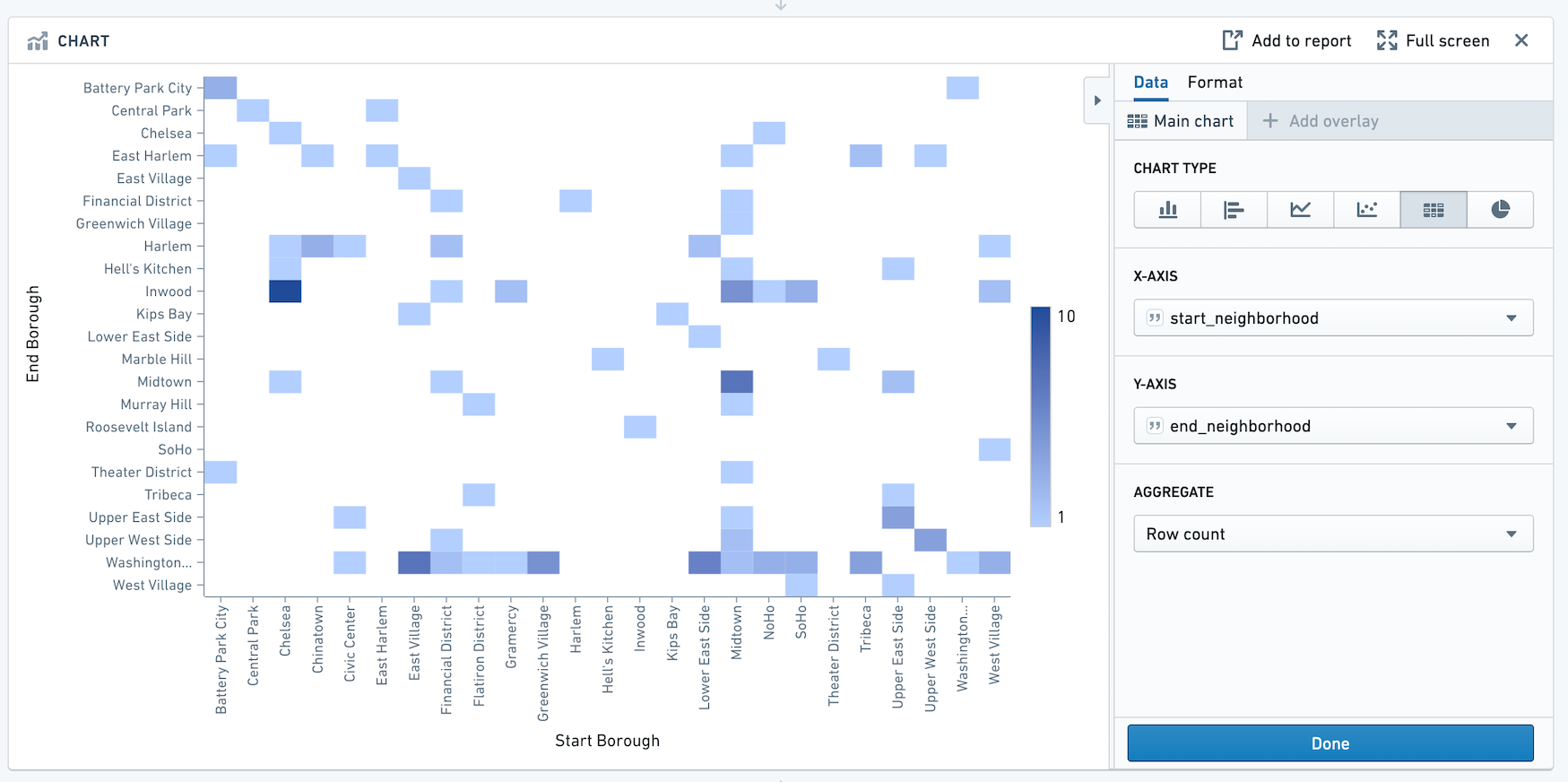
그리드
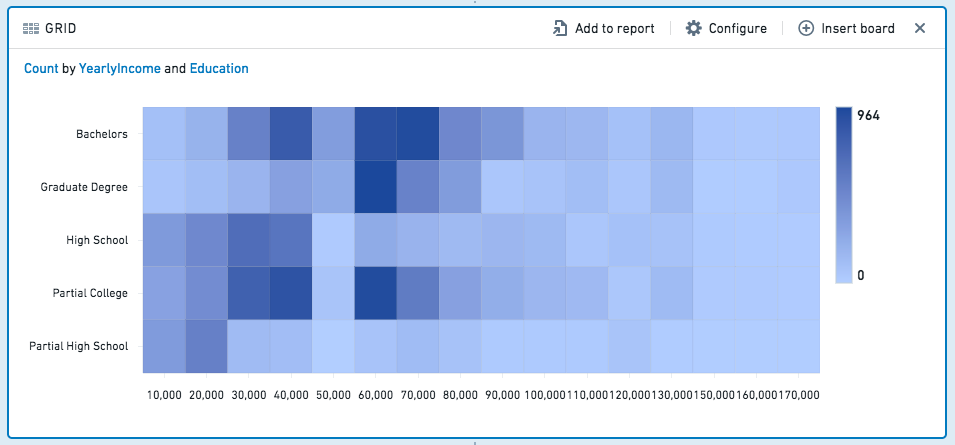
그리드 보드는 히스토그램과 비슷하지만 그리드 보드는 두 열로 데이터를 집계하고 결과를 열기 차트로 표시합니다.(두 개 이상의 열의 경우 피벗 테이블을 사용할 수 있습니다.) 예를 들어 다음 그리드는 교육 수준과 연간 소득을 비교합니다.
SQL 등가
그리드 보드는 집계 쿼리의 시각화로, 히스토그램 및 피벗 테이블 보드와 유사합니다. 그리드는 다음과 같은 SQL 쿼리와 대략적으로 동일합니다:
Copied!1 2 3 4SELECT [x축-컬럼], [y축-컬럼], <집계_지표>([집계-컬럼]) FROM <부모_보드> GROUP BY [x축-컬럼], [y축-컬럼] -- x축과 y축 컬럼을 기준으로 집계 지표를 계산합니다.
구성
- X축 및 Y축
- 두 열을 선택하십시오. 선택한 열의 고유 값 조합이 격자의 각 셀을 구성합니다.
- 집계
- 격자의 각 셀에 대해 계산할 집계 지표를 선택하십시오. 집계 결과가 셀의 색상을 결정합니다.
- 사용 가능한 집계 지표는 다음과 같습니다. Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. Median, Standard Deviation, and Variance.
- Count를 제외한 나머지는 집계가 적용되는 열을 지정해야 합니다. Unique Count의 경우, 임의의 열을 선택할 수 있습니다.
- Min, Max, Sum, Mean, Approx. Median, Standard Deviation, Variance는 숫자 열에만 적용됩니다.
Approx. Median 집계는 근사값입니다. Contour는 기본 정확도로 percentile_approx 함수를 호출하여 백분율 값 0.5를 사용합니다.
필터링
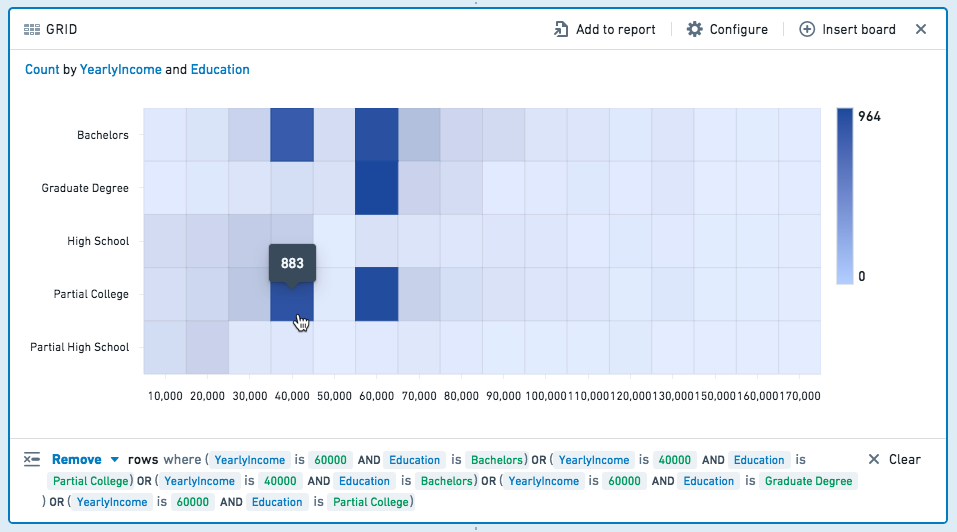
그리드에서 하나 이상의 셀을 선택하여 미래의 보드용 데이터셋을 필터링하십시오. 셀을 다시 클릭하여 선택을 취소하십시오.
Keep을 선택하여 선택한 값만 필터링하거나, Remove를 선택하여 선택하지 않은 값만 유지하십시오.
Heatmap
히트맵 보드는 지도에 지리코드 데이터를 표시하며, 색상 코드로 값이 표현됩니다.
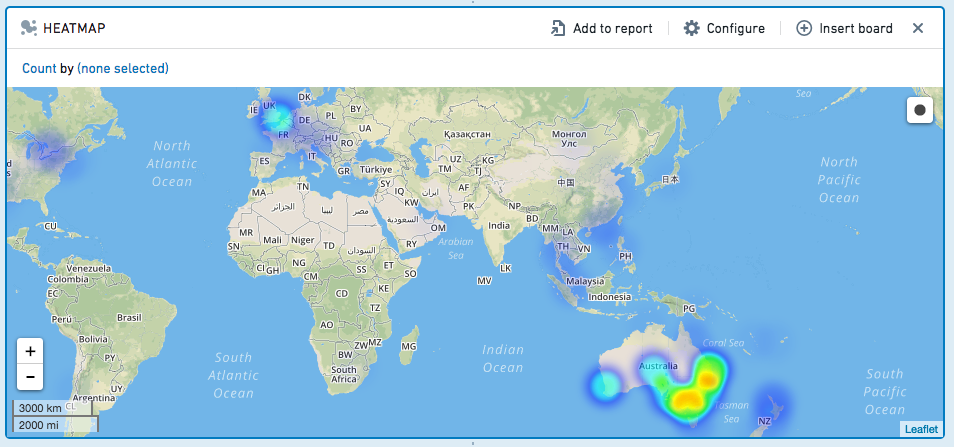
구성
- 위도/경도 데이터가 있는 열을 지정하십시오.
- 선택적으로, 지오해시 열을 지정하십시오.
- 그런 다음, 집계 지표를 계산하십시오.
- 사용 가능한 집계 지표는 다음과 같습니다. Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. Median, Standard Deviation, and Variance.
- Count를 제외한 나머지는 집계가 적용되는 열을 지정해야 합니다. Unique Count의 경우, 임의의 열을 선택할 수 있습니다.
- Min, Max, Sum, Mean, Approx. Median, Standard Deviation, Variance는 숫자 열에만 적용됩니다.
- 사용 가능한 집계 지표는 다음과 같습니다. Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. Median, Standard Deviation, and Variance.
Approx. Median 집계는 근사값입니다. Contour는 기본 정확도로 percentile_approx 함수를 호출하여 백분율 값 0.5를 사용합니다.
필터링
히트맵에서 반경을 그려 해당 반경 내에 있는 지오 데이터를 포함하는 모든 행을 선택할 수 있습니다.
 을 클릭한 다음, 맵에서 원을 그리려면 클릭하고 드래그하십시오.
을 클릭한 다음, 맵에서 원을 그리려면 클릭하고 드래그하십시오.

선택한 반경 내의 값을 Keep하거나, 해당 값을 Remove하여 선택되지 않은 값만 유지하십시오.
선택을 지우고 필터를 제거하려면 맵의 원 바깥쪽을 클릭하십시오.
Pivot table
피벗 테이블 보드를 사용하면 데이터를 여러 차원에서 빠르게 집계 값을 계산할 수 있습니다. 이 계산의 결과는 샘플링되어 테이블에 표시되는 내용이 불완전할 수 있습니다. 이 샘플링은 아래에서 자세히 설명되어 있습니다.
고객에 대한 인구통계 정보가 포함된 데이터셋이 있다고 가정할 때, 다음 피벗 테이블은 결혼한 여성, 결혼한 남성, 미혼 여성, 미혼 남성의 고객 수(연령별)를 계산합니다.
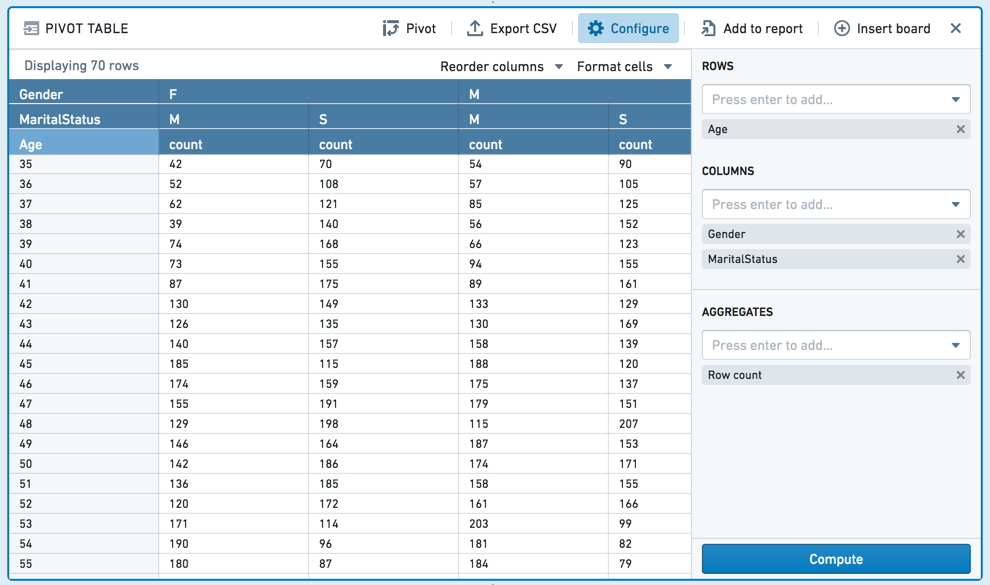
샘플링에 대한 중요한 참고 사항
느린 프론트엔드 및 백엔드 성능을 방지하기 위해 계산할 행의 수에 제한이 있습니다. 제한은 구성 가능하며, 기본 maxRows 값은 1,000행으로 설정됩니다.
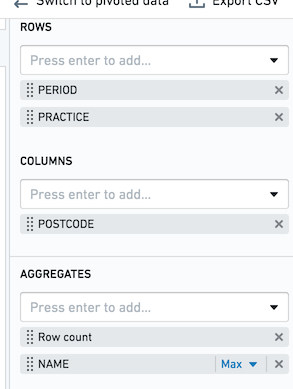
위 스크린샷과 같이 피벗 테이블의 행 집계가 PERIOD 및 PRACTICE이고 열 집계가 POSTCODE라고 가정하십시오. 각 조합에 대해 행 수와 열 NAME의 최대값을 얻고 싶습니다. maxRows 구성 값이 1,000인 경우, 1,000개의 완전한 행만 계산됩니다. 각 행은 완전하게 보장되지만 일부 행은 표시되지 않을 수 있습니다.
피벗 테이블의 열을 정렬할 때 정렬은 전체 데이터셋이 아닌 미리보기에서 수행됩니다. 전체 데이터셋을 정렬하려면 Sort Board를 사용하십시오. 자세한 정보는 Sort를 참조하십시오.
피벗된 데이터 전체와 상호 작용하려면 보드에서 Switch to pivoted data 옵션을 사용하여 Contour 분석을 피벗 테이블 보드 아래의 모든 보드에 대해 완전히 계산된 피벗 데이터로 전환하십시오. 또는, 피벗 테이블 상류에서 데이터를 더 필터링하여 셀 제한을 피할 수 있습니다.
구성
열 집계를 지정할 때, 열 값은 대소문자를 구분하지 않아야 고유합니다. 예를 들어, "Borough" 열에 "Brooklyn"과 "brooklyn"이라는 값이 포함된 경우, "Borough"를 열 집계로 지정하면 피벗 테이블 계산이 실패합니다. 이 문제를 피하려면 모든 값이 일관된 대소문자로 변환하십시오.
- 열
- 기존 데이터셋에서 집계를 수행할 하나 이상의 열을 선택하십시오. 원본 데이터셋의 선택된 열의 값 조합이 피벗 테이블의 각 열을 구성합니다.
- 행
- 원본 데이터셋에서 하나 이상의 열을 선택하여 피벗 테이블의 행을 정의하십시오. 원본 데이터셋의 선택된 열의 값 조합이 피벗 테이블의 각 행을 구성합니다.
- 집계
- 사용 가능한 집계 지표는 다음과 같습니다. Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. Median, Standard Deviation, and Variance.
- Count를 제외한 나머지는 집계가 적용되는 열을 지정해야 합니다. Unique Count의 경우, 임의의 열을 선택할 수 있습니다.
- Min, Max, Sum, Mean, Approx. Median, Standard Deviation, Variance는 숫자 열에만 적용됩니다.
- 사용 가능한 집계 지표는 다음과 같습니다. Count (레코드 수), Unique Count, Min, Max, Sum, Mean, Approx. Median, Standard Deviation, and Variance.
Approx. Median 집계는 근사값입니다. Contour는 기본 정확도로 percentile_approx 함수를 호출하여 백분율 값 0.5를 사용합니다.
열, 행 및 집계 사이에서 드래그 앤 드롭을 할 수 있습니다.
피벗 테이블에서 여러 집계를 지정할 수 있습니다. 선택한 행과 열의 각 조합에 대해 각 집계가 계산됩니다.
행, 열 또는 모두에 대한 총계를 계산할 수도 있습니다. 총계는 전체 데이터셋에 대해 집계를 수행하여 계산됩니다(즉, Unique Count의 총계는 데이터셋의 고유 개수의 총계이고, Mean의 총계는 전체 데이터셋의 평균입니다).
피벗 (집계된 데이터로 전환)
Pivot (집계된 데이터로 전환)을 클릭하면, 히스토그램 이후에 추가하는 보드는 원본 데이터셋이 아닌 테이블에서 계산된 집계 데이터를 사용합니다.
새 데이터셋에는 원본 히스토그램 구성에서 Y축에 선택한 열과 집계에 대한 열이 포함됩니다. 예를 들어:
Column editor
열 편집기 보드를 사용하면 데이터셋에서 열을 쉽게 제거하고 새 열을 파생할 수 있습니다. 후속 보드는 유지하려는 열 집합을 사용합니다.
새 열 추가
기존 데이터셋의 열에 이진 연산을 수행하여 새로 파생된 열을 생성하거나, 문자열 열을 숫자 또는 날짜 형식 열로 파싱할 수 있습니다.
SQL Equivalent
파생된 열은 SQL 또는 Spark의 연산자를 사용하는 것과 동일합니다. 예를 들어, 다음은 Income per person에 대한 열을 파생합니다.
Copied!1 2 3 4 5SELECT [Household Members], -- 가구 구성원 수 [Marital Status], -- 결혼 상태 [Income Column] / [Household Members] AS [Income per person] -- 가구 구성원 당 소득 FROM [Table Name] -- 테이블 이름
기존 열
열을 제거하려면 기존 열 표시를 선택한 다음 제거하려는 열의 이름을 선택합니다. 열을 다시 추가하려면 열을 다시 선택하세요. 많은 열을 삭제하려면 모두 제거를 선택한 다음 보존하려는 열을 선택할 수도 있습니다.
중복 행 제거
열 편집기 보드의 중복 행 제거 옵션을 사용하여 중복 행을 제거할 수 있습니다.

SQL 등가
열 편집기 보드를 통해 열을 제거하는 것은 SQL에서 열 이름을 선택하는 것과 동일합니다. 예를 들어, A-E까지 5개의 열이 있는 테이블에서 다음은 열 D와 E를 제거합니다:
Copied!1 2 3 4-- 선택하다 columnA, columnB, columnC SELECT columnA, columnB, columnC -- <테이블이름>에서 FROM <tableName>
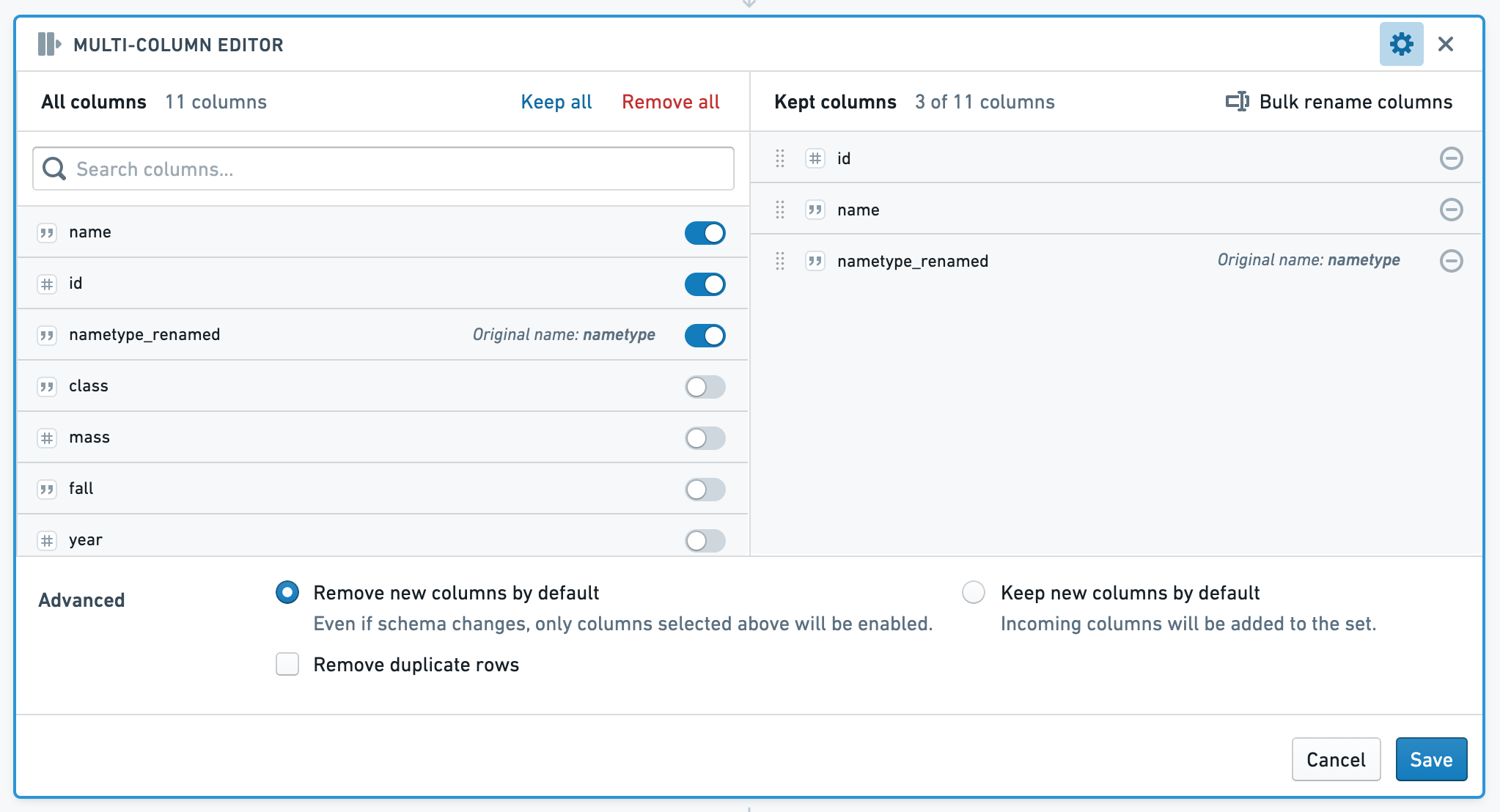
다중 열 에디터
다중 열 에디터 보드는 데이터에서 열을 재정렬, 이름 변경 및 제거하고 중복 행을 제거할 수 있습니다. 이후의 보드는 유지하기로 선택한 열 세트를 사용합니다.
보드의 왼쪽은 모든 열을 보여주고, 오른쪽은 유지된 열을 보여줍니다. 유지된 열 섹션에서는 유지된 열의 이름을 변경하거나 재정렬하거나 일괄 이름 변경 기능을 사용할 수 있습니다.
SQL 동등
열의 재정렬, 이름 변경 및 제거는 SQL에서 열 이름을 선택하는 것과 동등합니다. 예를 들어, A-E까지 5개의 열이 있는 표가 주어진 경우 다음 코드는 D와 E 열을 제거하고 A를 A_1로 이름을 변경합니다:
Copied!1 2 3-- columnA를 columnA_1로 이름 변경하여 선택, columnB와 columnC도 선택 SELECT columnA as columnA_1, columnB, columnC FROM <tableName> -- 여기에 테이블 이름 입력
풍부하게 하기
풍부하게 하기 보드는 현재 작업 중인 데이터셋을 다른 데이터셋에 조인하고 일치하는 결과를 데이터에 병합하도록 허용합니다.
링크
링크 보드는 다른 데이터셋에 조인하고 해당 데이터셋의 일치하는 레코드를 반환하게 합니다. 이는 링크된 (오른쪽) 테이블만에서 열을 반환하는 것으로, set math 보드의 '오직 유지하기' 작업과는 다릅니다.
Set math
Set math 보드는 다른 세트를 기반으로 현재 데이터셋을 변경하게 합니다. 데이터셋을 다른 데이터셋에 있는 데이터만 유지하도록 필터링하거나 (오직 유지하기), 다른 데이터셋에서 데이터를 추가하거나 (추가), 또는 다른 데이터셋의 결과를 기반으로 데이터를 제거할 수 있습니다 (제거).
조인
조인 보드는 Palantir 관리자에 의해 구성된 추천 조인 템플릿을 제공합니다. 추천 조인을 추가하거나 수정하려면 관리자에게 연락하세요.
내보내기
내보내기 보드는 분석 세트를 CSV 또는 XLS 파일로 다운로드할 수 있게 합니다.
드롭다운에서 csv 또는 xls를 선택한 후 내보내기를 클릭합니다. 보드가 서버에서 작업을 마치면 파일 이름을 커스터마이징하는 옵션이 제공됩니다. 그런 다음 다운로드 <#> 레코드를 클릭하여 파일을 다운로드합니다.


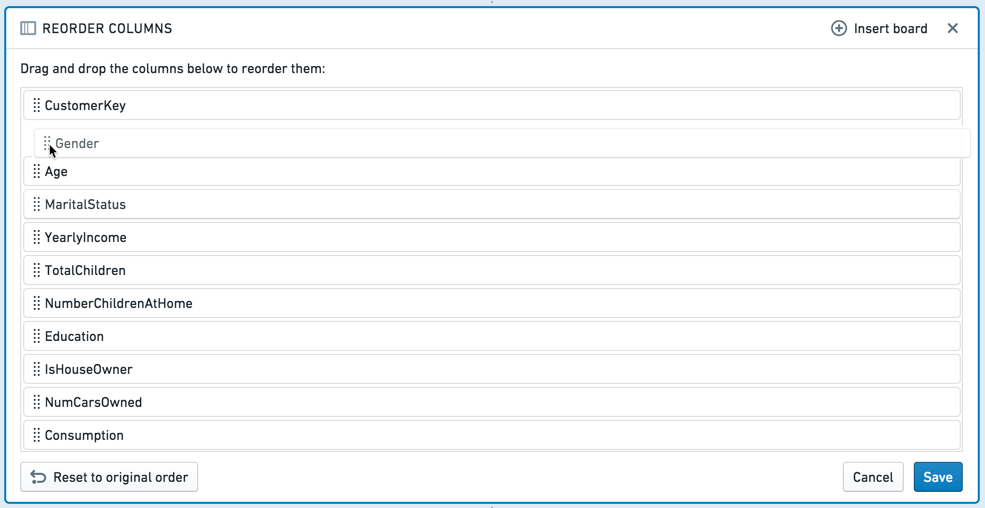
열 순서 변경
열 순서 변경 보드는 테이블 내의 열을 다른 순서로 끌어다 놓게 합니다.
매크로
매크로 보드는 이전에 생성된 매크로를 경로에 적용하게 합니다.
정렬
정렬 보드는 데이터셋의 모든 데이터를 정렬하게 합니다. 이 정렬은 분석에 한정되며 저장된 데이터셋에는 적용되지 않습니다. 정렬은 다운스트림 집계 (예: 조인 또는 중복 행 제거)에 의해 손실될 수 있으므로, 이러한 집계를 정렬 전에 수행하는 것이 좋습니다.
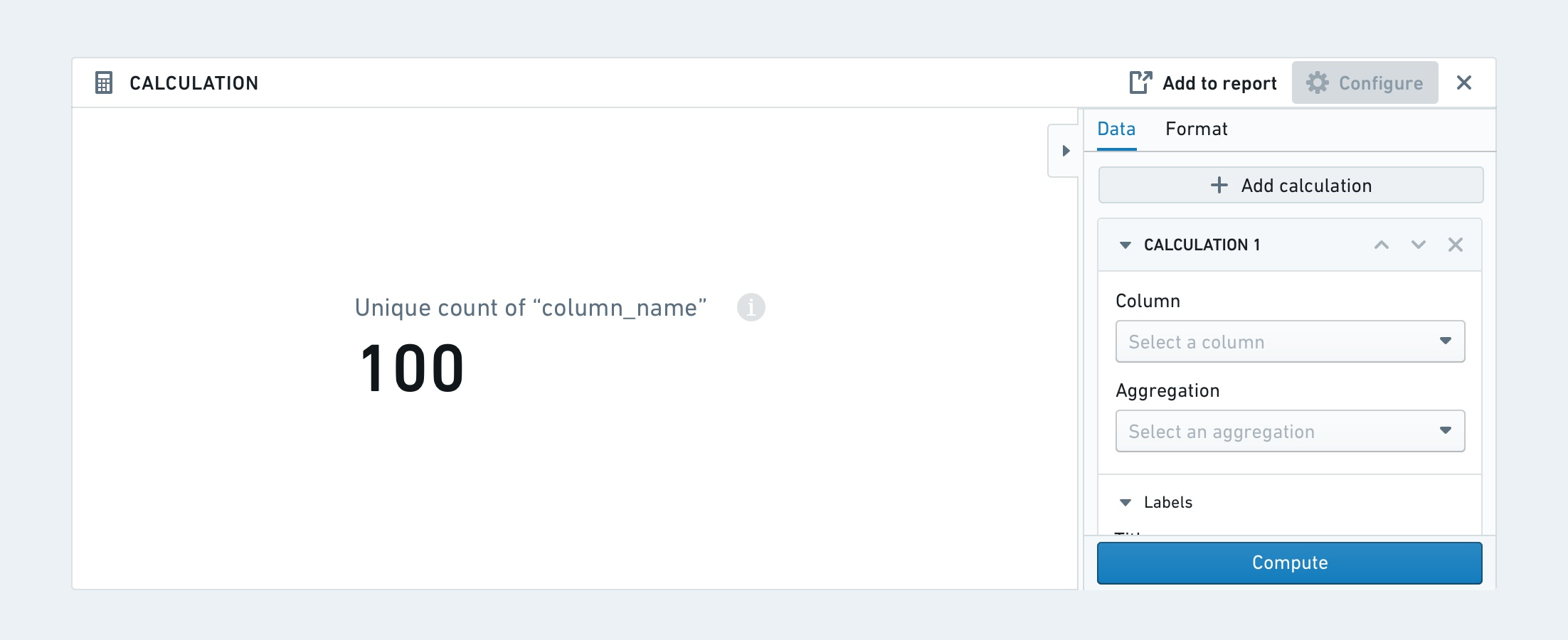
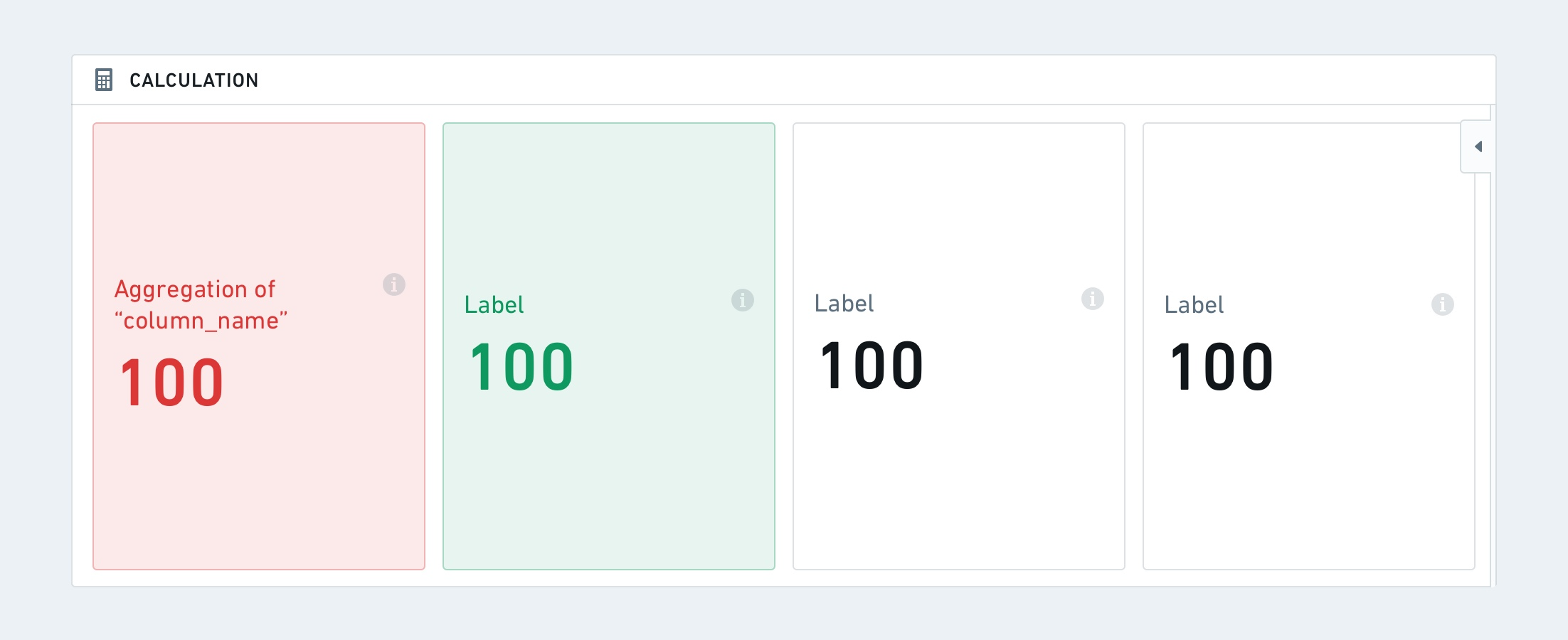
연산
연산 보드는 카드 또는 목록의 형태로 데이터에 여러 집계 연산을 표시하게 합니다. 사용 가능한 집계 지표는 다음과 같습니다: 고유 카운트, 최소값, 최대값, 합계, 평균, 중앙값, 표준 편차, 그리고 분산.
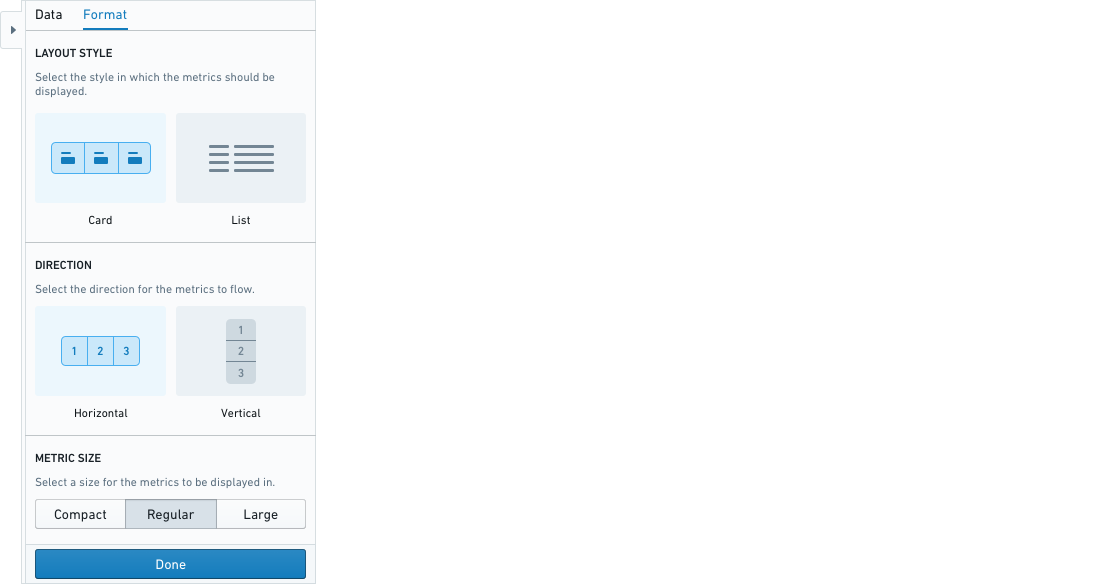
연산 보드는 카드 또는 목록 형식으로 포맷팅될 수 있습니다.
카드 형식에는 가로 또는 세로 방향 그리고 지표 크기에 대한 추가적인 포맷팅 옵션이 있습니다.
마지막으로, 각 연산은 설정된 규칙 (조건)에 따라 조건적 포맷팅을 가질 수 있습니다. 이는 조건이 충족되는지 여부에 따라 글꼴 색상과 배경 색상이 변경될 수 있다는 것을 의미합니다.
Unpivot
Unpivot 보드는 일부 열을 행으로 바꾸어 데이터를 재구성할 수 있게 합니다. 선택한 열은 두 개의 새 열로 다시 포맷됩니다: 헤더 열 (원래의 열 이름을 포함) 그리고 값 열 (원래의 데이터 값을 포함).