다운로드를 위한 데이터셋 준비하기
다음 내보내기 과정은 고급 워크플로이며, Foundry 인터페이스에서 직접 데이터를 다운로드하지 못하는 경우에만 수행해야 합니다. 이는 Code Repositories의 액션 메뉴를 사용하거나 다른 Foundry 애플리케이션에서 내보내는 경우에 해당합니다.
이 가이드는 Code Repositories에서 변환을 사용하여 CSV를 다운로드 준비하는 방법을 설명합니다. 경우에 따라서는 Foundry 인터페이스의 액션 메뉴를 사용하지 않고 Foundry에서 CSV 형식의 데이터 샘플을 다운로드해야 할 수도 있습니다. 이러한 경우, 액션 메뉴를 사용하는 대신 빌드 도중 내보내기 파일을 준비하는 것을 권장합니다.
데이터 준비하기
다운로드를 위한 CSV를 준비하는 첫 번째 단계는 필터링되고 정리된 데이터 세트를 생성하는 것입니다. 다음 단계를 수행하는 것을 권장합니다:
- 데이터 샘플이 내보내질 수 있는지 확인하고 데이터 내보내기 제어 규칙을 준수합니다. 특히, 내보내기가 그룹의 데이터 거버넌스 정책을 준수하는지 확인해야 합니다.
- 가능한 한 데이터를 작게 필터링하여 필요한 목표를 충족시킵니다. 일반적으로 CSV 형식의 데이터의 압축되지 않은 크기는 기본 HDFS 블록 크기(128 MB)보다 작아야 합니다. 이를 달성하기 위해 필요한 열만 선택하고 행 수를 최소화해야 합니다. 특정 값에 대해 필터링하거나 임의의 행 수(예: 1000)를 가진 무작위 샘플을 가져와 행 수를 줄일 수 있습니다.
- 열 유형을
string으로 변경합니다. CSV 형식은 스키마(열에 대한 강제 유형과 레이블)가 없으므로 모든 열을 문자열로 캐스팅하는 것이 좋습니다. 이는 타임스탬프 열에 특히 중요합니다.
다음은 뉴욕 택시 데이터셋에서 가져온 샘플 코드로, 데이터를 다운로드 준비하는 데 도움이 될 수 있습니다:
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23def prepare_input(my_input_df): from pyspark.sql import functions as F # 필터링할 컬럼 지정 filter_column = "vendor_id" # 필터링할 값 지정 filter_value = "CMT" # 위에서 지정한 컬럼과 값으로 데이터 필터링 df_filtered = my_input_df.filter(filter_value == F.col(filter_column)) # 샘플링할 행의 대략적인 수 지정 approx_number_of_rows = 1000 # 샘플링할 비율 계산 (선택할 샘플의 수 / 전체 행의 수) sample_percent = float(approx_number_of_rows) / df_filtered.count() # 계산된 비율을 사용하여 데이터 샘플링 (복원 추출이 아님, seed=0으로 랜덤성 지정) df_sampled = df_filtered.sample(False, sample_percent, seed=0) # 중요한 컬럼들을 리스트로 지정 important_columns = ["medallion", "tip_amount"] # 중요한 컬럼들만 선택하고, 모든 컬럼을 문자열 타입으로 변환 return df_sampled.select([F.col(c).cast(F.StringType()).alias(c) for c in important_columns])
비슷한 로직과 Spark 개념을 사용하여 SQL 또는 Java와 같은 다른 Spark API에서 준비를 구현할 수도 있습니다.
출력 형식 설정 및 파티션 통합
데이터가 내보내기 준비가 되면 출력 형식을 CSV로 설정할 수 있습니다. 출력 형식을 CSV로 설정하면 데이터의 기본 형식이 Foundry의 CSV 파일로 저장됩니다. 또한 출력 형식을 JSON, ORC, Parquet 또는 텍스트로 설정할 수도 있습니다. 마지막으로 결과를 단일 CSV 파일에 저장하려면 다운로드를 위해 데이터를 단일 파티션으로 통합해야 합니다.
파이썬
다음 예제 코드에서는 파이썬에서 데이터를 통합하는 방법을 보여줍니다:
Copied!1 2 3 4 5 6 7 8 9from transforms.api import transform, Input, Output @transform( output=Output("/path/to/python_csv"), # 출력 경로를 "/path/to/python_csv"로 설정합니다. my_input=Input("/path/to/input") # 입력 경로를 "/path/to/input"로 설정합니다. ) def my_compute_function(output, my_input): # my_input의 데이터프레임을 취해서 한 개의 파티션으로 병합(coalesce)한 후, csv 형식으로 출력 경로에 씁니다. # 옵션에서 "header"를 "true"로 설정하여, 출력 파일의 첫 번째 행에 열 이름이 포함되도록 합니다. output.write_dataframe(my_input.dataframe().coalesce(1), output_format="csv", options={"header": "true"})
SQL
다음 예제 코드는 SQL에서 데이터를 합치는 방법을 보여줍니다:
CREATE TABLE `/path/to/sql_csv` USING CSV AS SELECT /*+ COALESCE(1) */ * FROM `/path/to/input`
이 코드는 SQL을 사용하여 특정 입력 경로에서 CSV 파일을 읽어와 새로운 테이블을 생성합니다. 또한, COALESCE(1)는 빈 필드를 1로 채우는 역할을 합니다.
아래는 한국어로된 주석이 추가된 코드입니다:
/* 특정 입력 경로에서 CSV 파일을 읽어와 새로운 테이블을 생성합니다. 빈 필드는 COALESCE(1)을 사용하여 1로 채웁니다. */
CREATE TABLE `/path/to/sql_csv` USING CSV AS SELECT /*+ COALESCE(1) */ * FROM `/path/to/input`
추가적인 CSV 생성 옵션은 공식 Spark 문서를 참조하십시오.
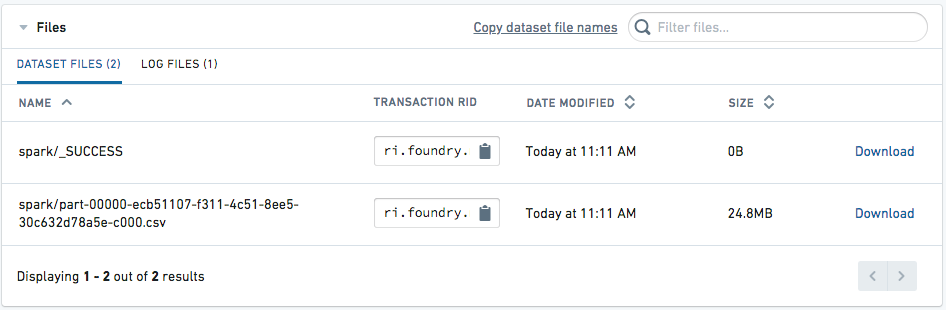
다운로드를 위한 파일 접근
데이터셋이 생성되면, 데이터셋 페이지의 상세 탭으로 이동합니다. CSV 파일이 다운로드 가능한 상태로 표시됩니다.