상속된 마킹 및 조직 제거
현재 stop_propagating 변환 속성은 Pipeline Builder에서 지원되지 않습니다. Code Repositories의 리소스에서 먼저 변환 속성을 사용한 다음 결과물을 Pipeline Builder 그래프에 추가하여 파이프라인 구축을 계속하길 권장합니다.
Markings과 Organizations은 사용자의 적격성에 따라 리소스에 대한 접근을 제한합니다.
종속 리소스를 추출하거나 숨기는 동안 제한된 콘텐츠가 제거되면 사용자는 해당 파생 리소스에 대한 마킹 및/또는 조직을 제거하려 할 수 있습니다. 상속된 마킹 및 조직을 제거하는 이 과정은 stop_propagating 및 stop_requiring 입력 변환 속성을 사용하여 수행할 수 있습니다.
stop_propagating은 상속된 Markings (예: 개인정보)를 제거하는 데 사용됩니다.stop_requiring은 상속된 Organizations (예: Palantir)를 제거하는 데 사용됩니다.
용어
- Organizations은 사용자 그룹과 리소스 간의 엄격한 경계를 보장하는 프로젝트에 적용된 접근 요구 사항입니다. 접근 요구 사항을 충족시키기 위해 사용자는 프로젝트에 적용된 조직 중 최소 하나의 회원 또는 게스트 회원이어야 합니다.
- Markings은 리소스에 적용된 접근 요구 사항으로, 일체형 방식으로 접근을 제한합니다. 접근 요구 사항을 충족시키기 위해 사용자는 리소스에 적용된 모든 마킹의 회원이어야 합니다.
- Roles은 사용자가 주어진 리소스에서 수행할 수 있는 특정 워크플로를 정의하는 권한 모음입니다 (예: 뷰어, 에디터 등).
알아두기
stop propagating및stop requiring키 구문은 조직과 마킹에만 적용되며 Roles에는 적용되지 않습니다.- 리포지토리에는 적어도 하나의 보호된 브랜치(예: main)가 있어야 합니다. 이 브랜치는 또한 적어도 한 명의 필수 승인자를 강제로 지정해야 합니다.
- 조직과 마킹을 제거할 수 있는 브랜치는 보호된 브랜치뿐입니다. 보호되지 않은 브랜치를 언급하면(예:
on_branches=[..., "not-protected-branch"]) 빌드가 실패하게 됩니다. - 조직 및 마킹 제거는 Python, Java, SQL에서 지원됩니다.
- 상속된 조직 및 마킹 제거를 승인하는 데 특별한 사용자 권한이 필요합니다. 사용자는 마킹 제거 권한이 있는
Remove marking권한과 조직 제거 권한이 있는Expand access권한이 필요합니다.
기본 워크플로
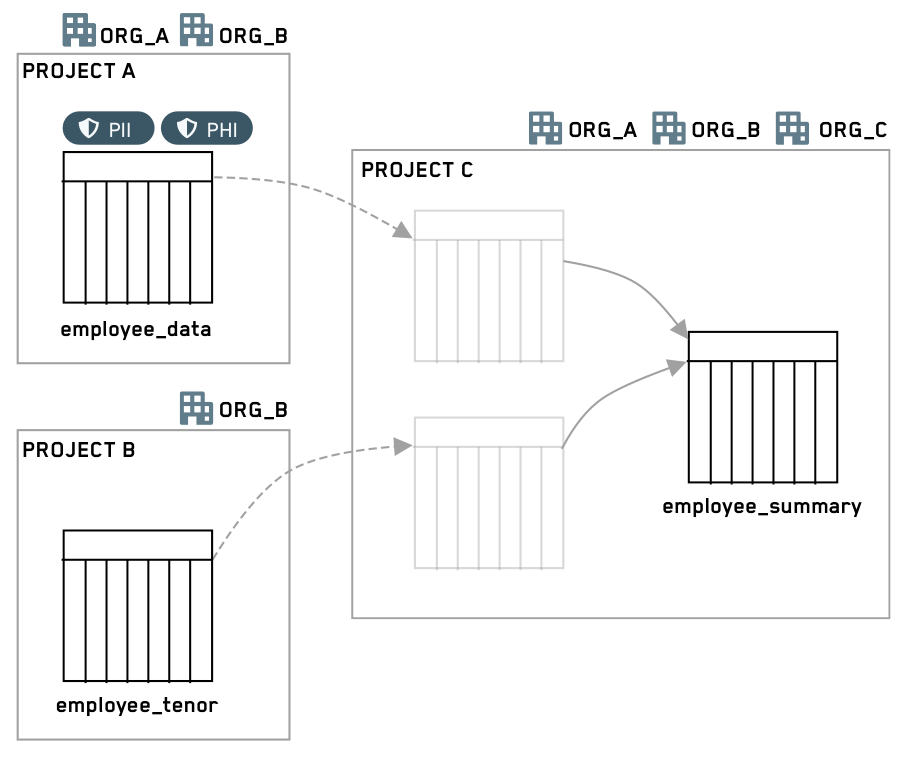
아래 프로젝트 C의 회색 데이터셋 상자는 대상 프로젝트의 모든 입력에 대해 프로젝트 참조를 추가해야 함을 강조합니다.
단계
-
보호된 브랜치(예: main)에서 새로운 브랜치를 생성합니다.
-
입력 변환에
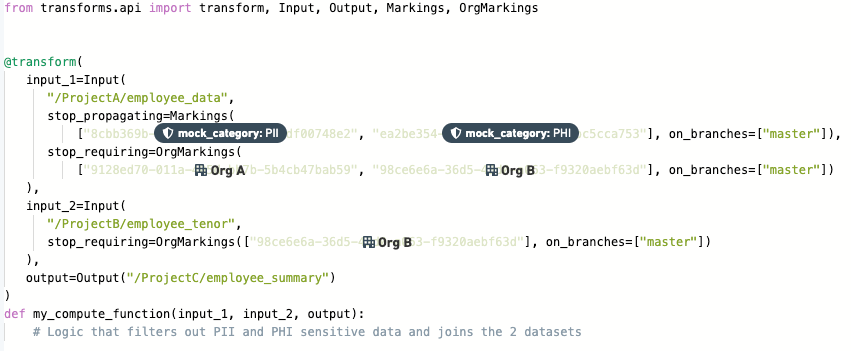
stop_propagating및/또는stop_requiring속성 중 하나를 추가합니다. 예를 들면:
-
이 코드를 보호된 브랜치에 병합하려면 풀 리퀘스트를 생성합니다.
-
마킹에 대해
Remove marking권한이 있는 사용자 또는 조직에 대해Expand access권한이 있는 사용자가 제안된 변경 사항을 승인하거나 거부할 수 있습니다. 여러 명의 검토자가 추가되면, 어느 검토자든 거부하면 전체 풀 리퀘스트가 거부됩니다. -
승인되면, 코드 에디터가 PR을 병합하고 결과 데이터셋을 빌드합니다. 결과 데이터셋이 빌드된 후에는 전파된 마킹 및/또는 조직이 더 이상 존재하지 않습니다.
내부적으로 조직은 약간 다른 유형의 마킹으로 표시되므로, stop_requiring 다음의 변환 키워드는 OrgMarkings라고 불립니다.
입력 변환 속성
상속된 마킹(예: PII)을 제거하려면 stop_propagating 키 구문을 사용하세요.
상속된 조직(예: Palantir)을 제거하려면 stop_requiring 키 구문을 사용하세요.
이러한 키 구문은 마킹 또는 조직 제거가 필요한 모든 입력에 지정해야 합니다. 제거할 때마다 적용할 보호 브랜치도 지정해야 합니다. 마킹 ID, 조직 ID, 및 브랜치는 항상 따옴표로 묶인 문자열로 지정해야 합니다.
적어도 하나의 상류 조직을 제공해야 합니다. 사용자는 적어도 하나의 조직을 만족시켜야 하기 때문입니다. 각 나열된 조직에 대해 승인이 필요합니다. 아래의 상세 워크플로는 이 점을 설명하는 예를 제공합니다.
파이썬
파이썬에서는 입력 생성자에서 마킹 제거를 지정합니다.
Copied!1 2 3 4 5 6 7 8 9 10@transform( # 입력값 설정 input_1=Input("<input_id>", # 전파 중지 설정 stop_propagating=Markings([markingId1, ...], [branch1, ...]), # 요구 중지 설정 stop_requiring=OrgMarkings([orgMarking1, ...], [branch2, ...])), # 출력값 설정 output=Output("<output_id>") )
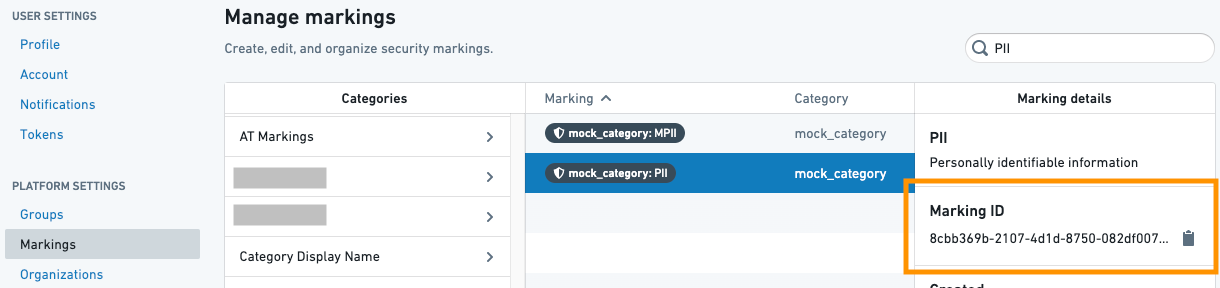
Markings 클래스는 Marking ID 목록과 마킹 제거를 적용할 보호된 브랜치 목록을 사용합니다. Marking ID는 Settings 페이지의 Markings 목록에서 찾을 수 있습니다.
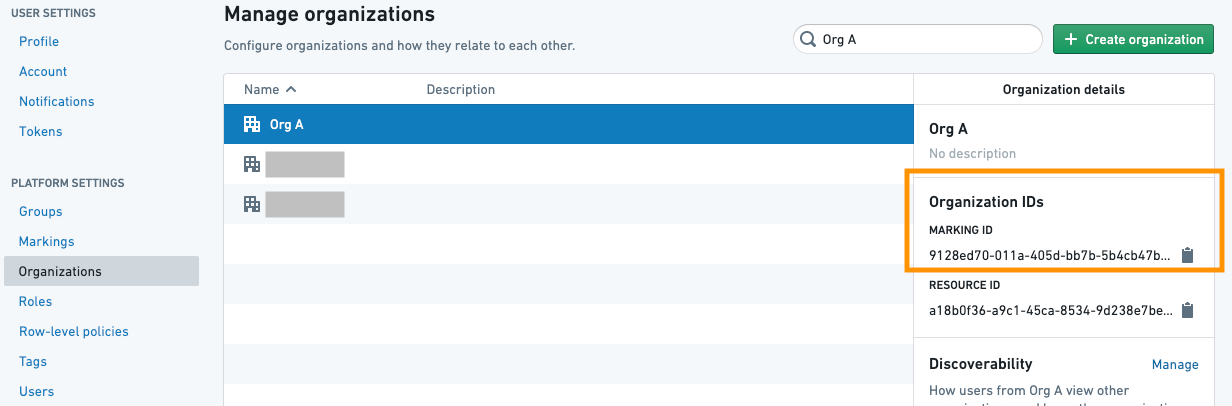
OrgMarking 클래스는 Organization ID 목록과 마킹 제거를 적용할 보호된 브랜치 목록을 사용합니다. Organization ID는 Settings 페이지의 Organizations 목록에서 찾을 수 있습니다.
자바
자바 자동 등록
자바에서 마킹 제거는 자동으로 등록된 변환에 대한 입력에 대한 주석을 통해 지정됩니다.
구문:
Copied!1 2 3 4 5 6 7 8 9 10 11 12@Compute public void myComputation( // 특정 마킹을 중지하고 분기를 처리합니다. @StopPropagating(markings = {markingId1, ...}, onBranches = {branch1, ...}) // 특정 조직의 마킹 요구사항을 중지하고 분기를 처리합니다. @StopRequiring(orgMarkings = {orgId1, ...}, onBranches = {branch2, ...}) // 입력 ID를 받아서 FoundryInput 객체를 생성합니다. @Input("<input_id>") FoundryInput input, // 출력 ID를 사용하여 FoundryOutput 객체를 생성합니다. @Output("<output_id>") FoundryOutput output)
@StopPropagating 및 @StopRequiring 주석은 마킹 제거를 적용할 마킹 ID 세트와 보호된 브랜치 세트를 사용합니다.
마킹 또는 브랜치 중 하나만 지정된 경우 {}로 감싸지 않아도 됩니다 (예: @StopPropagating(markings = marking1, onBranches = "my-branch")).
자바 수동 등록
수동으로 등록된 Java 변환의 경우, MyPipelineDefiner.java 파일에서 등록하는 동안 unmarking을 지정하기 위해 다음 구문을 사용합니다.
Copied!1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26@Override public void define(Pipeline pipeline) { // 고수준 수동 변환 객체 생성 HighLevelTransform highLevelManualTransform = HighLevelTransform.builder() .computeFunctionInstance(new HighLevelManualFunction()) .putParameterToInputAlias("myInput", "/path/to/input/dataset") .returnedAlias("/path/to/output/dataset") // 원하는 unmarking 설정 .desiredUnmarkings(Set.of( Unmarking.builder() .branch("branch1") .input(alias("/input1")) .output(alias("/output")) .markingId(MarkingId.valueOf("markingId")) .build(), Unmarking.builder() .branch("branch1") .input(alias("/input1")) .output(alias("/output")) .markingId(MarkingId.valueOf("orgId1")) .build() )) .build(); // 파이프라인에 고수준 수동 변환 객체 등록 pipeline.register(highLevelManualTransform); }
SQL
SQL에서는 SparkSQL 힌트 문을 사용하여 제거 표시를 지정합니다:
Copied!1 2 3 4 5 6 7 8CREATE TABLE <output_id> AS SELECT /*+ foundry_stop_propagating(markingId1, ...) foundry_stop_requiring(orgMarkingId1, ...) foundry_on_branches(branch1, ...) */ * FROM <input_id> -- 테이블 생성 <output_id> -- SELECT 문을 사용하여 <input_id> 테이블에서 모든 데이터를 선택 -- foundry_stop_propagating : 마킹 전파 중지 -- foundry_stop_requiring : 원본 마킹 요구사항 중지 -- foundry_on_branches : 지정된 브랜치에만 적용
SQL에서 마킹 및 그룹 제거는 어떤 SELECT 문에도 추가할 수 있습니다. 예를 들면:
Copied!1 2CREATE TABLE <output_id> AS SELECT * FROM <input_1_id> CROSS JOIN (SELECT /*+ foundry_stop_propagating(markingId1) foundry_on_branches("my-branch") */ * FROM <input_2_id>) -- 크로스 조인을 사용하여 두 입력 테이블의 모든 행 조합을 결과로 생성
제거 권한
일반적으로 코드를 보고 풀 요청을 승인하려면, 승인자는 프로젝트와 저장소 자체에 있는 모든 그룹 및 마킹을 통과해야 하며, 기본 Stemma 데이터셋 보기 워크플로를 포함하는 역할이 있어야 합니다(기본적으로, 보기 권한 보유 사용자 역할에 포함됨). 사용자는 또한 각 그룹 및 마킹에 권한을 가지고 있어야 승인 모드를 설정하거나 해당 그룹 및 마킹을 제거하는 풀 요청을 승인할 수 있습니다. 사용자는 반드시 그룹 또는 마킹의 구성원일 필요는 없습니다.
마킹 승인의 경우, 승인하는 사용자는 마킹에 마킹 제거 역할이 있어야 합니다.
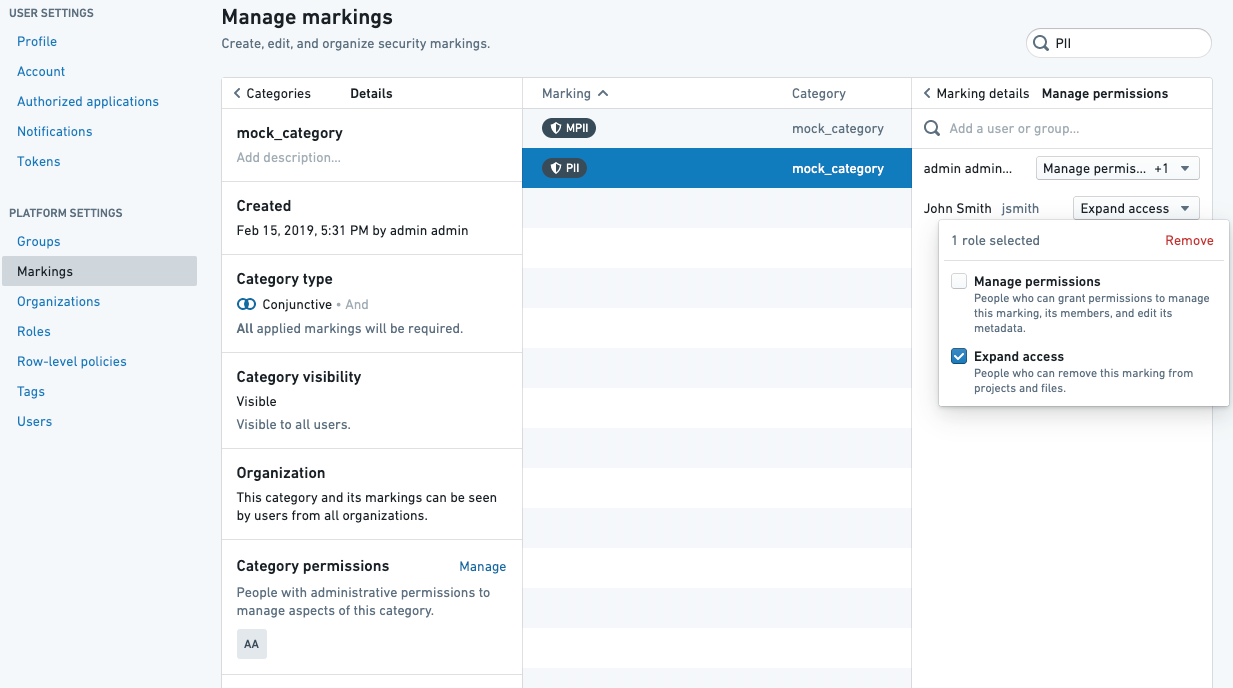
그룹 승인의 경우, 승인하는 사용자는 마킹에 접근 확장 역할이 있어야 합니다.
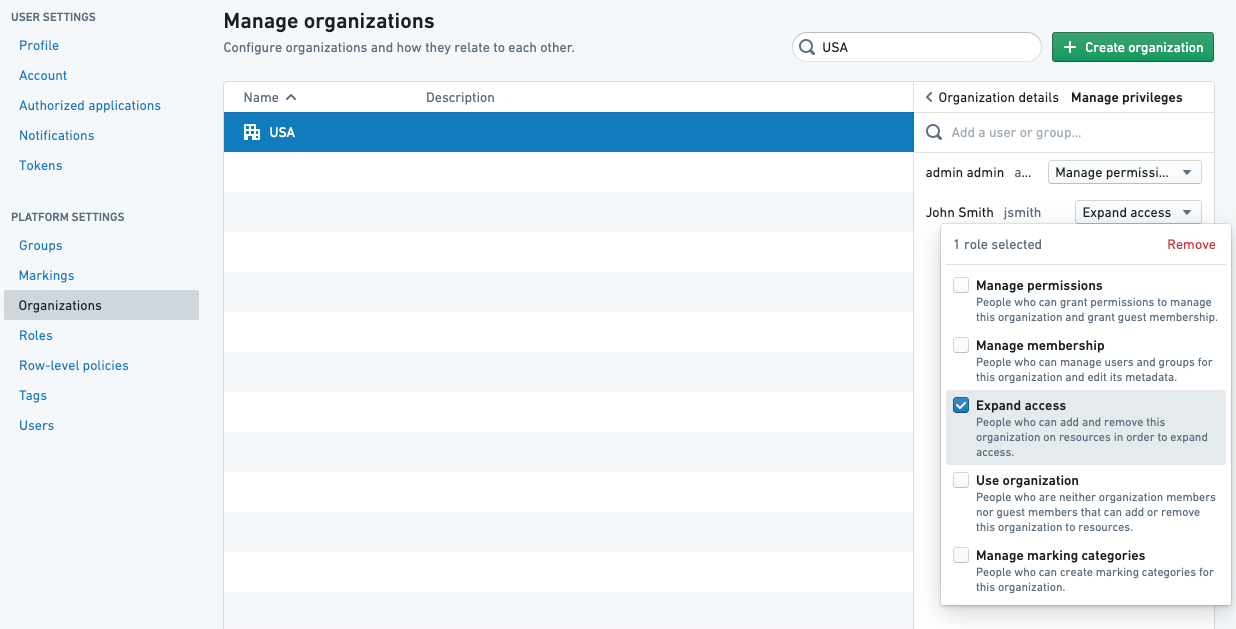
승인 모드
각 저장소 및 각 그룹 및 마킹에 대해 데이터 거버넌스 사용자는 어떤 모드를 사용해 새로운 승인을 트리거할지 정의할 수 있습니다:
- 재승인 필요: 이것은 모든 그룹 및 마킹에 대한 기본 모드입니다. 저장소는 이 그룹 및 마킹이 제거된 브랜치에 대한 모든 풀 요청에 대해 보안 승인을 항상 필요로 합니다. 이 모드는 로직 변경에 대한 보호를 제공하여 그룹 및 마킹이 안전하게 제거되도록 합니다.
- 재승인 필요 없음: 이 그룹 및/또는 마킹이 처음으로 변환에서 제거될 때 승인이 필요합니다. 이후 로직 변경은 보안 승인에 의해 차단되지 않습니다.
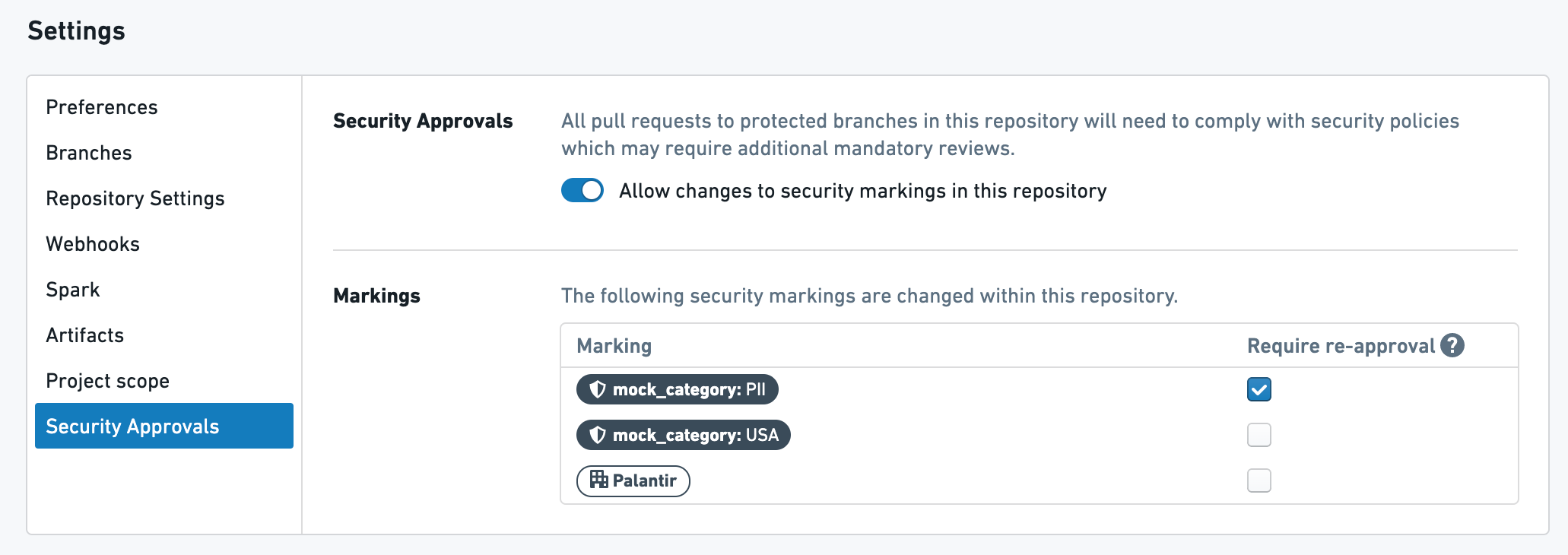
예제 1
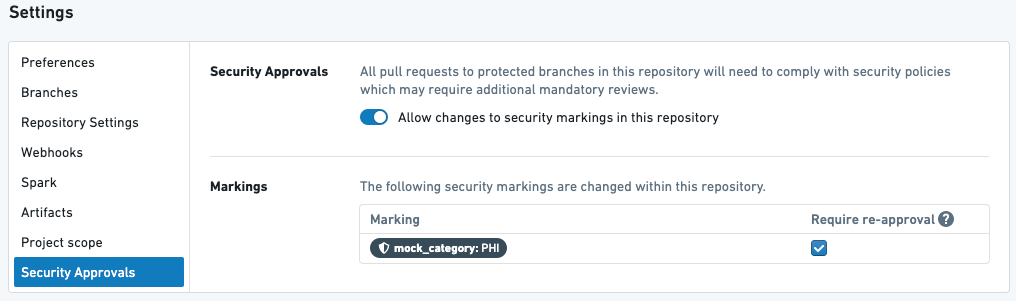

위는 PHI 마킹이 재승인을 필요로 하는 저장소에서의 변환입니다.
위의 설정을 가지고 있을 경우, 다음과 같은 일이 발생합니다:
- 사용자가 PHI 마킹의 전파를 중단하는 첫 PR을 생성할 때, 그들은 PHI 마킹에
제거역할이 있는 사용자로부터 승인을 받아야 합니다. - 사용자가 나중에 위의 변환을 다음 PR에서 수정하면, 다시 승인을 받도록 요청받게 됩니다.
- 사용자가 저장소에서 어떤 것이든 수정하면 – 이 파일이나 다른 파일에서 – 그들은 다시 PHI 마킹에 대한 승인을 받도록 요청받게 됩니다.
예제 2
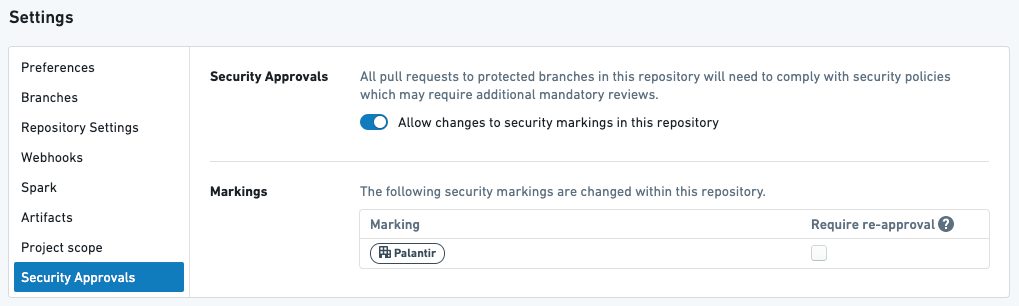

위는 하나의 그룹, PALANTIR을 가진 저장소에서의 변환으로, 재승인이 필요 없습니다.
위의 설정을 가지고 있을 경우, 다음과 같은 일이 발생합니다:
- 사용자가
PALANTIR그룹을 요구하는 것을 중단하는 첫 풀 요청을 생성할 때, 그들은PALANTIR그룹에접근 확장역할이 있는 사람으로부터 승인을 받아야 합니다. - 사용자가 나중에 위의 변환을 다음 풀 요청에서 수정하면, 승인을 받을 것을 요청받지 않습니다.
- 사용자가 이후에 이 저장소에서 어떤 것이든 수정하면, 승인을 받을 것을 요청받지 않습니다.
예제 3

Transform 1: 위는 하나의 마킹, PII, 그리고 하나의 그룹, PALANTIR을 가진 변환입니다. PII 마킹은 재승인을 필요로 하고 PALANTIR 그룹은 재승인이 필요하지 않습니다.

Transform 2: 위는 하나의 마킹, USA,를 가진 변환으로, 재승인이 필요 없습니다.
위의 설정을 가지고 있을 경우, 다음과 같은 일이 발생합니다:
- 사용자가 Transform 1에 대한 첫 풀 요청을 생성할 때, 그들은
PII마킹에마킹 제거역할이 있는 사용자와PALANTIR그룹에접근 확장역할이 있는 사용자로부터 승인을 받아야 합니다. - 사용자가 나중에 Transform 1을 다음 풀 요청에서 수정하면, 그들은
PII마킹에마킹 제거역할이 있는 사용자로부터만 승인을 받도록 요청받게 됩니다. - 사용자가 Transform 2에 대한 첫 풀 요청을 생성할 때, 그들은
USA마킹에마킹 제거역할이 있는 사용자와PII마킹에마킹 제거역할이 있는 사용자로부터 승인을 받아야 합니다. - 사용자가 나중에 Transform 2를 다음 풀 요청에서 수정하면, 그들은
PII마킹에마킹 제거역할이 있는 사용자로부터만 승인을 받도록 요청받게 됩니다. - 사용자가 이후에 이 저장소에서 어떤 것이든 수정하면, 그들은
PII마킹에마킹 제거역할이 있는 사용자로부터만 승인을 받도록 요청받게 됩니다.
자세한 워크플로
이 예제 시나리오에서 코드 에디터는 민감한 상위 프로젝트에서 두 개의 데이터셋을 사용하고 특정 정보를 제거하고, 결과 데이터셋에 더 넓은 대상을 접근하게 하려고 합니다. 두 개의 데이터셋은 각각 두 개의 마킹을 가지고 있으며, 하위 프로젝트의 참조로 추가되었습니다. 코드 에디터는 네 개의 마킹 중 세 개가 전파되는 것을 중단하려고 하며, 그래서 그들이 결과물 데이터셋에 나타나지 않습니다. 또한, 상위 프로젝트는 OrgA 또는 OrgB의 사용자에게 제한되어 있고, 하위 데이터를 OrgC의 사용자에게 배포하려는 의도가 있습니다.
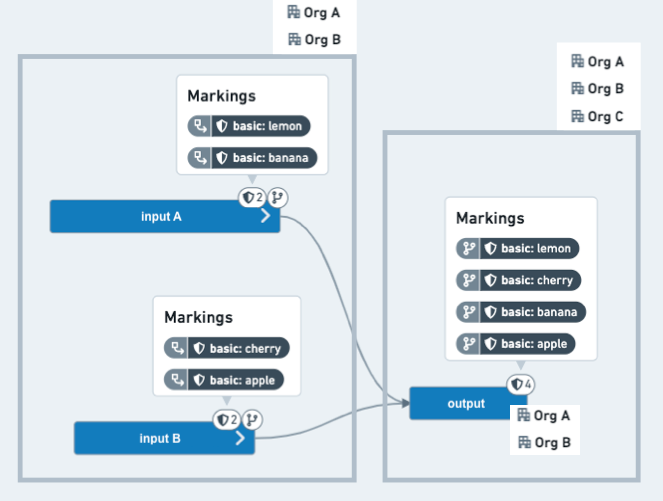
Before: 결과물 데이터셋은 코드 에디터의 브랜치에서 모든 네 개의 마킹을 상속받았고, 여전히 OrgA 또는 OrgB의 사용자에게 제한되어 있습니다.
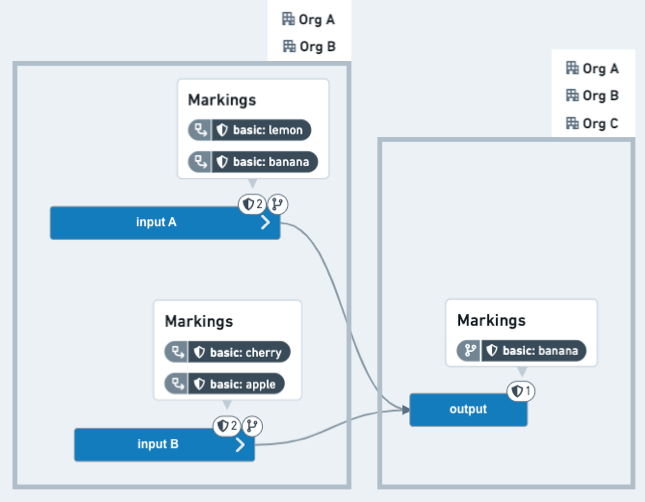
After: 결과물 데이터셋은 보호된 브랜치(예를 들어, main)로 병합되면, 이제 상속받은 마킹은 하나만 가지고 있고 OrgA 또는 OrgB의 구성원이어야 하는 것은 필요하지 않습니다.
단계
- 코드 에디터는 하위 프로젝트의 저장소의
기능/클린 데이터브랜치에 새로운 변환을 작성합니다.
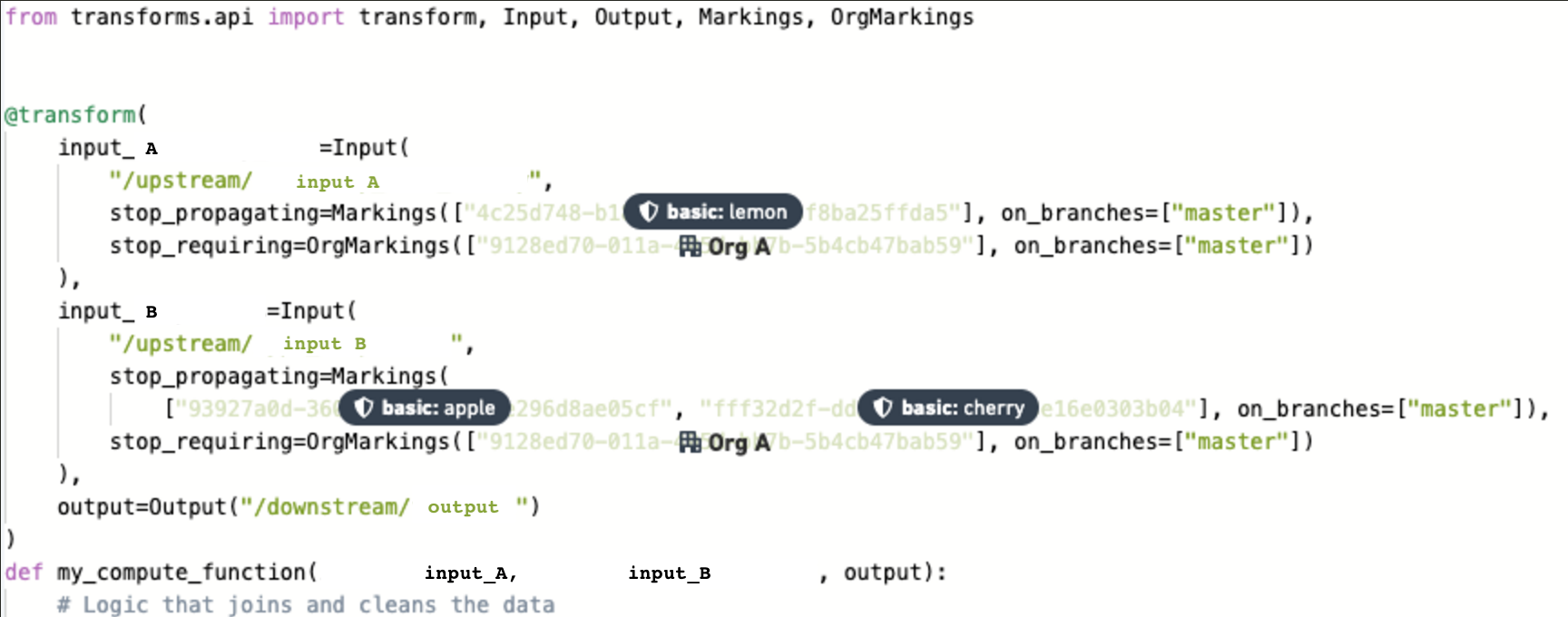
-
모든 마킹 변경이
master브랜치를 위해 요청되므로,기능/클린 데이터에서 작업하는 데 필요한 승인은 없습니다. 다시 말해, 결과물 데이터셋이기능/클린 데이터브랜치에서 빌드될 때, 모든 상위 마킹은 여전히 상속됩니다. -
코드 에디터는 메인 브랜치에 풀 요청을 생성하고
lemon,apple,cherry마킹에 의해 제한된 데이터를 관리하는 데이터 거버넌스 사용자들로부터 승인을 요청합니다. 코드 에디터는 또한 OrgA 데이터가 다른 그룹과 공유될 필요가 있을 때 승인할 수 있는 OrgA의접근 확장그룹 관리자로부터 승인을 요청합니다.
상속받은 그룹을 제거함으로써 접근을 확장하는 것은 모든 상속받은 그룹을 제거하는 효과가 있지만, 승인은 변환에 나열된 그룹에 적절한 권한을 가진 사용자로부터만 필요합니다. 모든 그룹으로부터 승인을 요구하려면, 모든 ID를 `stop_requiring` 컴포넌트에 나열해야 합니다. 이 예에서, OrgA는 주로 상위 프로젝트의 데이터를 담당하므로, 에디터는 그룹 간 승인 과정에 OrgA를 선택했습니다. 따라서, 에디터는 상속받은 그룹을 제거하기 위해 OrgA 관리자로부터만 승인이 필요합니다. 에디터가 요청하려는 그룹 승인에 따라, 에디터는 다음을 `stop_requiring`할 수 있습니다:
(1) OrgA (OrgA 관리자에 의한 승인과 함께),
(2) OrgB (OrgB 관리자에 의한 승인과 함께), 또는
(3) OrgA와 OrgB 모두 (두 그룹의 관리자로부터의 승인과 함께).
결과적으로, 결과물 데이터셋은 입력값에서 어떤 그룹도 상속받지 않고, 그것이 위치한 프로젝트에서의 그룹만을 존중하게 됩니다.
-
데이터 거버넌스 사용자와 그룹 관리자들은 Foundry 알림을 받아 그들의 승인이 요청되었다는 것을 알게 됩니다.
-
PR이 승인되었다고 가정하면, 코드 에디터는 이를 병합하고 After 이미지에 표시된 대로 결과물 데이터셋을 빌드합니다.
-
다음 주에, 다른 코드 에디터가 다른 코드 파일을 변경하고
master로 병합하기 위해 PR을 엽니다.
모든 마킹이 재승인을 필요로 하지 않으면, PR은 보안 리뷰를 거치지 않고 승인될 수 있습니다. 어떤 마킹이 승인을 필요로 하면, 이 새로운 PR은 그 마킹을 관리하는 데이터 거버넌스 또는 그룹 관리자에 의한 보안 리뷰를 필요로 할 것입니다.