Pipeline Builder로 점진적 파이프라인 생성
이 튜토리얼에서는 Pipeline Builder를 사용하여 단일 데이터셋의 결과물이 있는 간단한 점진적 파이프라인을 생성합니다.
아래에 사용된 데이터셋은 점진적 계산이 적용되는 방식을 설명하기 위한 가상의 예시입니다.
파트 1: 문제 설명
매주 새로운 데이터가 추가되는 flights 입력 데이터셋이 있다고 가정해봅시다. 우리는 JFK 공항에서 출발하는 항공편만 필터링한 다음, 그 항공편만 filtered_flights 결과물에 추가하려고 합니다.
flights 데이터셋의 행이 2000만 개라고 가정하고, 매주 100만 개의 행이 추가된다고 합시다. 점진적 계산을 사용하면, 파이프라인은 스냅샷 계산에서처럼 모든 행 대신 flights의 최신 처리되지 않은 트랜잭션만 고려해야 합니다.
파이프라인이 정기적으로 실행되면 점진적 처리를 통해 각 실행의 데이터 규모를 크게 줄일 수 있어 시간과 리소스를 절약할 수 있습니다.
이제 점진적 파이프라인을 설정하는 방법을 살펴보겠습니다.
파트 2: 점진적 요구사항 검증
먼저, 모든 점진적 제약 조건이 충족되었는지 확인합니다:
- 입력
flights는 기존 파일을 수정하지 않는APPEND트랜잭션 또는UPDATE트랜잭션을 통해 업데이트됩니다. flights에서filtered_flights를 계산하는 논리는 나중에 빌드하는 동안filtered_flights에 이전에 쓰여진 데이터를 변경할 필요가 없습니다.- 파이프라인 논리를 변경하려면 (예:
LGA공항에서 출발하는 항공편을 포함시키기 위해), 파이프라인을 업데이트할 수 있습니다. 이전에 처리된 항공편에 그 논리를 적용하려면 파이프라인을 다시 실행하려고 할 수 있습니다.
- 파이프라인 논리를 변경하려면 (예:
- 파이프라인에 윈도우 함수, 집계, 피벗이 포함된 경우 현재 트랜잭션에만 적용되도록 합니다.
Pipeline Builder에서 점진적 계산에 대한 중요한 제한 사항을 참조하여 전체 사항을 확인하십시오.
파트 3: 파이프라인 생성
이제 새로운 파이프라인을 초기화할 수 있습니다(단계별 설명서는 Pipeline Builder에서 배치 파이프라인 생성을 참조하십시오). flights를 입력 데이터셋으로 가져왔다고 가정합시다.
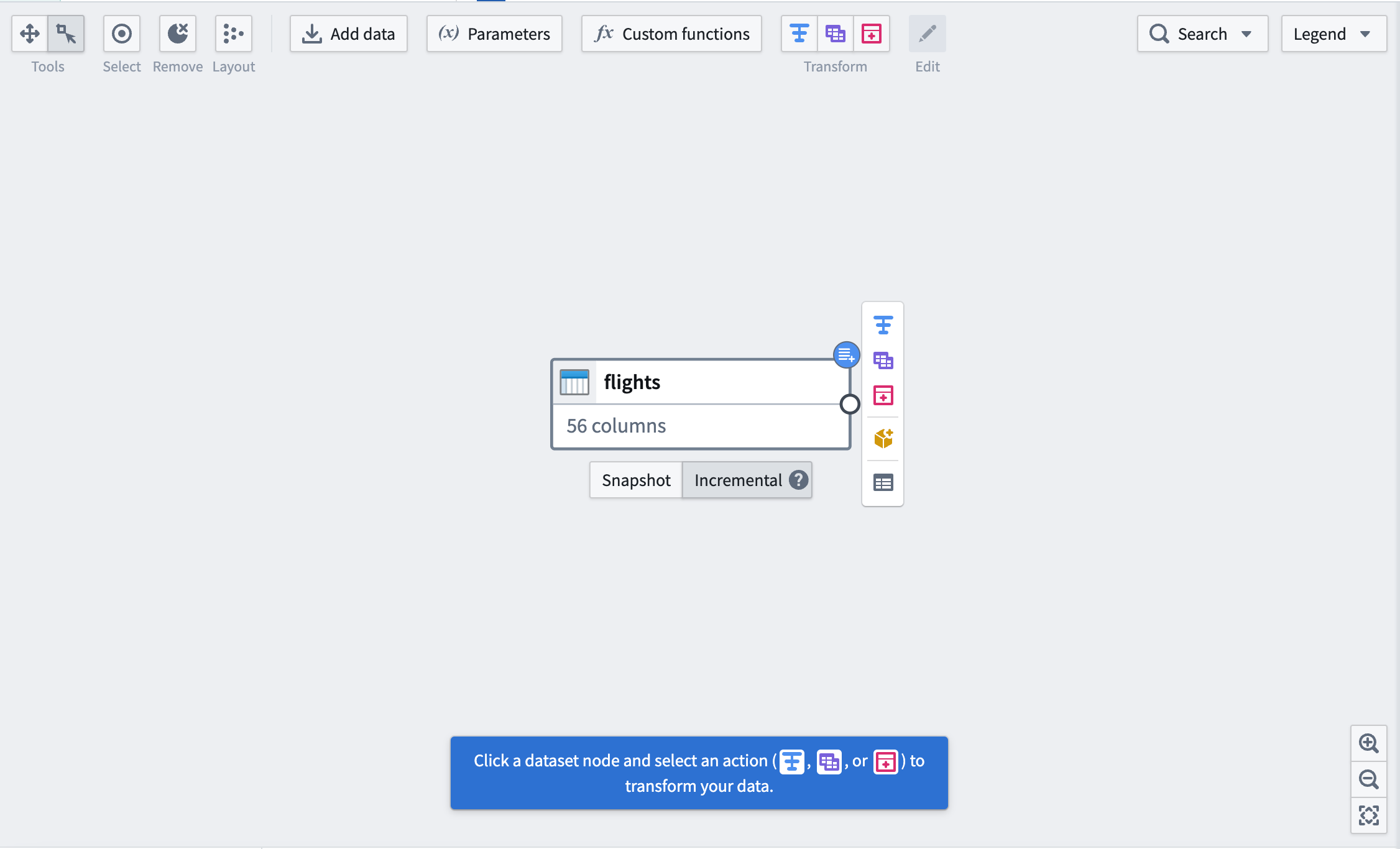
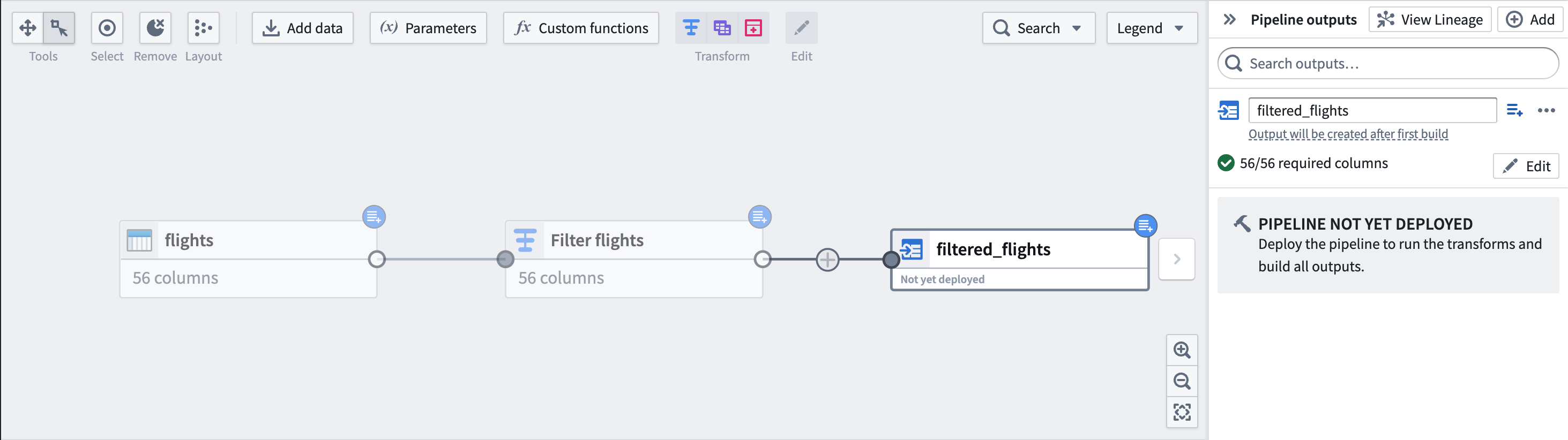
먼저, 데이터셋 아래의 버튼을 사용하여 입력 데이터셋을 Incremental로 표시합니다. 오른쪽 상단 모서리에 파란 배지가 표시되어 변경 사항을 나타냅니다.
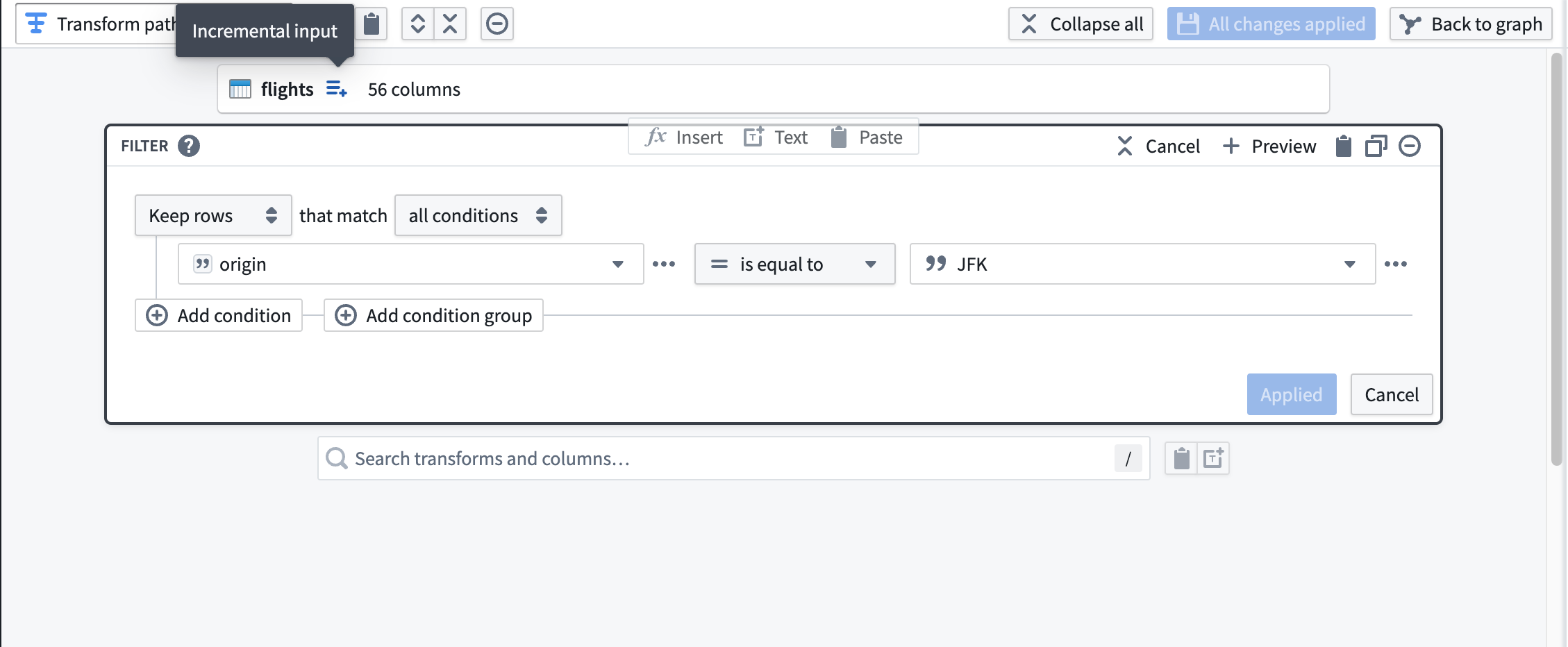
다음으로, JFK 공항에서 출발하는 항공편만 필터링하기 위해 flights에 변환을 추가합니다. 데이터셋 입력 오른쪽에 있는 Incremental input 툴팁으로 레이블이 지정된 아이콘에 주목하세요. 하류 변환은 점진적으로 처리되고 있음을 나타내기 위해 이 아이콘을 사용합니다.
그래프에서 하류 노드는 입력과 동일한 파란 배지로 표시됩니다.
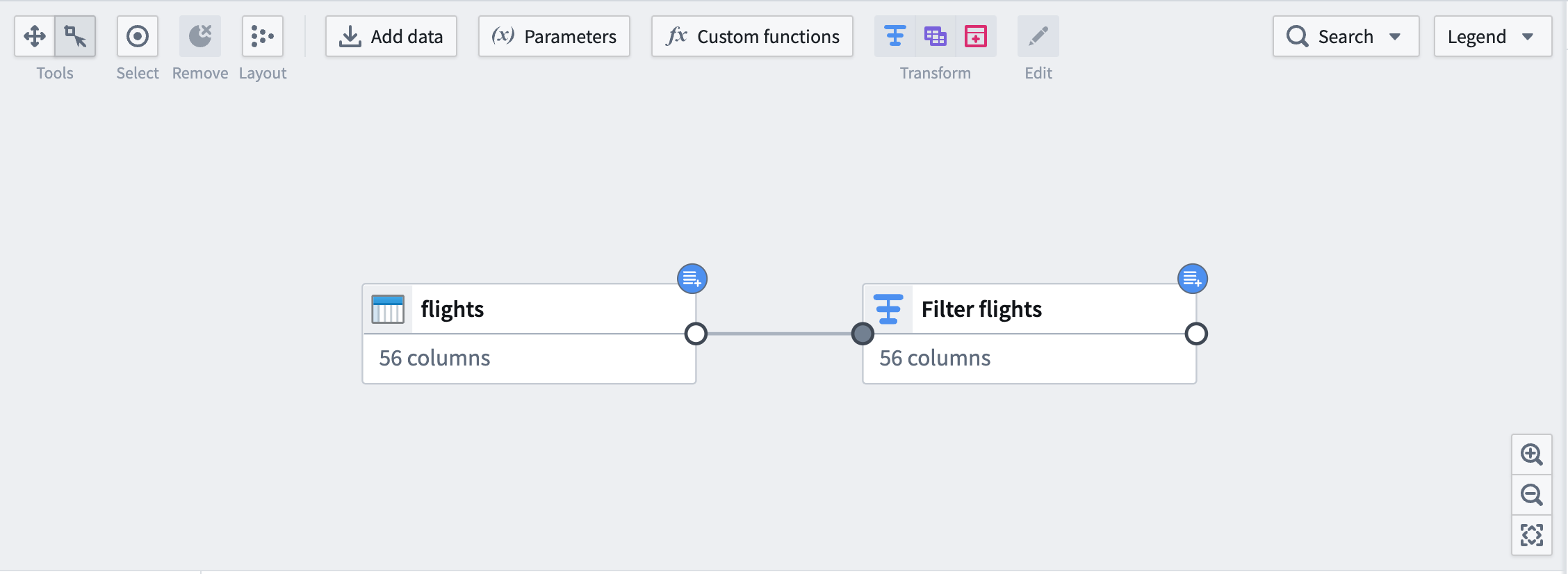
마지막으로, 결과물 데이터셋 filtered_flights를 추가합니다.
파트 4: 결과물 데이터셋 배포
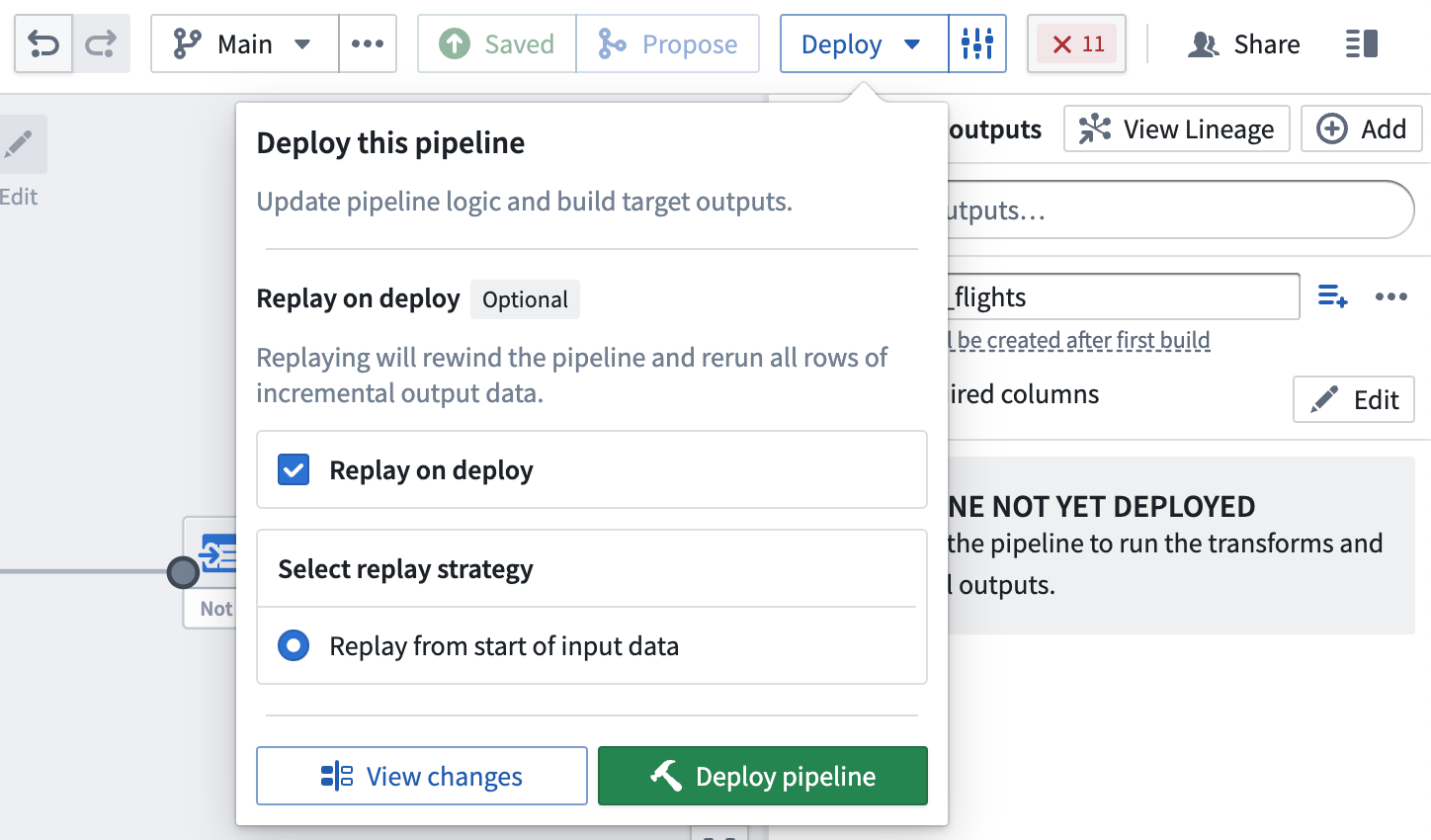
이제 파이프라인을 배포할 준비가 되었습니다.
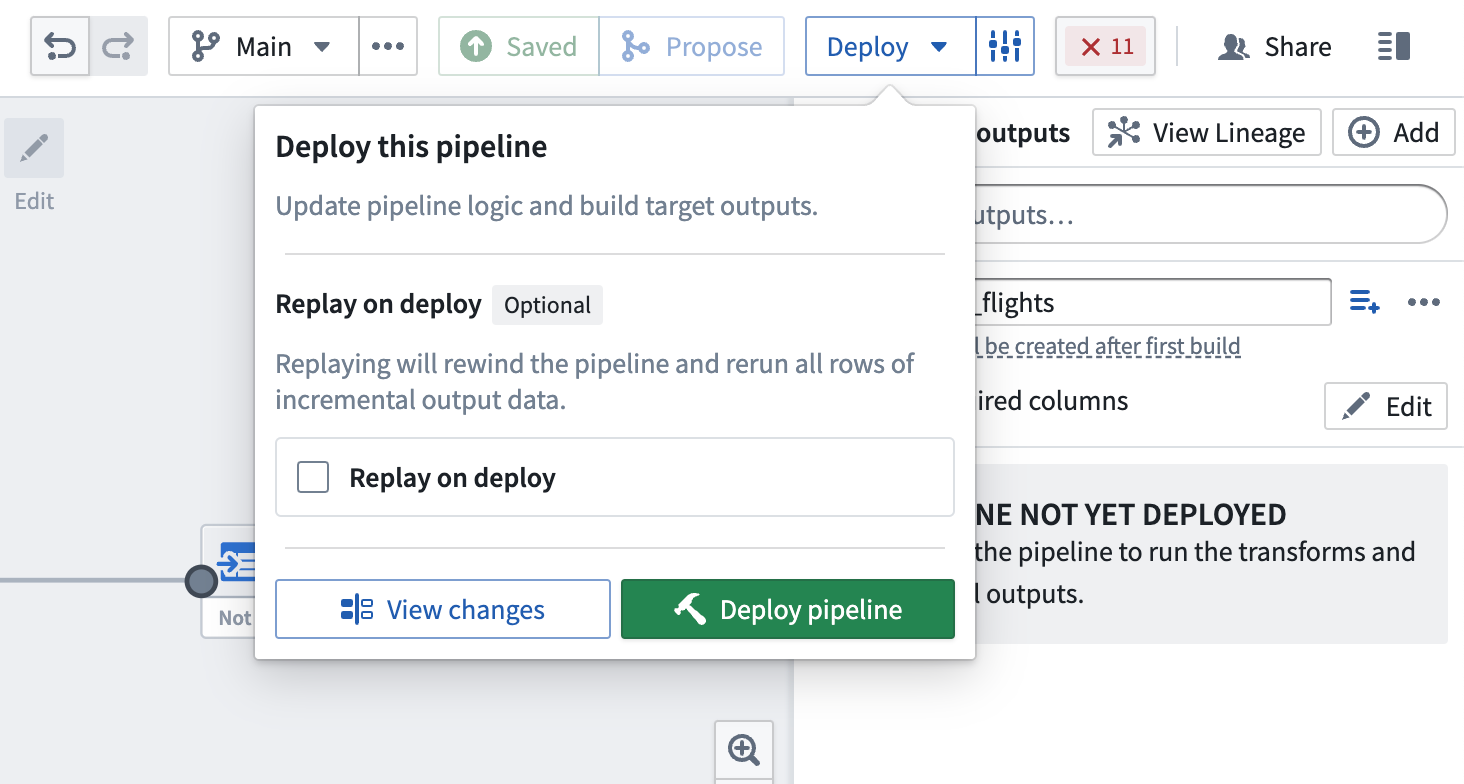
배포 시 다시 실행
때때로 이전 입력 트랜잭션을 다시 처리해야 할 필요가 있을 수 있습니다(예: 논리가 변경되고 이전 버전의 출력 데이터가 이제 사용되지 않는 경우). 이 경우에는 배포 시 다시 실행을 선택하여 전체 입력을 파이프라인 논리를 통해 실행할 수 있습니다. 다시 실행 후에는 입력에 새로운 추가 트랜잭션이 추가됨에 따라 점진적 계산이 계속되어야 합니다.
배포 시 다시 실행하면 결과물 데이터셋에서 SNAPSHOT 트랜잭션이 생성됩니다.